

Mark Zuckerberg says AI will write most of Meta’s code in the next 12–18 months. If your first reaction is dread — congratulations, you’re a developer who already maintained code.
Because the problem isn’t writing code.
It’s understanding it. Maintaining it. Refactoring it two years later without breaking production on a Friday.
AI is getting scary-good at generating code. Not just autocompleting lines — we’re talking entire service layers, test suites, and infrastructure scripts. That feels like a superpower until you realize this superpower has no memory, no system knowledge, and no architectural intuition. Just vibes. “AI tools like GPT can help accelerate this process, but they are not the solution.” – The Wild West of Coding: Why We’re Still Burning Digital Cities – SUCKUP.de
We’re now past the point of discussing whether AI can write useful code. It can. The question is what happens after it does.
And here’s the brutal truth:
AI knows how to write code. It has no idea why the code exists.
It doesn’t know about that performance fix from 2021. It doesn’t understand your team’s domain language. It doesn’t realize that “active” isn’t just a string — it’s a business-critical contract baked into legal compliance.
If we don’t separate generation from intent, we’re going to drown in beautifully structured, semantically useless garbage.
This post presents a two-part strategy:
-
Define a blueprint format that captures the what.
-
Encode the why directly into your codebase.
The goal isn’t to stop AI from writing code — it’s to make sure it only writes code that deserves to exist.
Abstraction Got Us Here — But It’s Breaking
Every generation of developers inherits more power and more abstraction.
That power is only useful if we don’t forget how the system underneath works.
Let’s break it down:
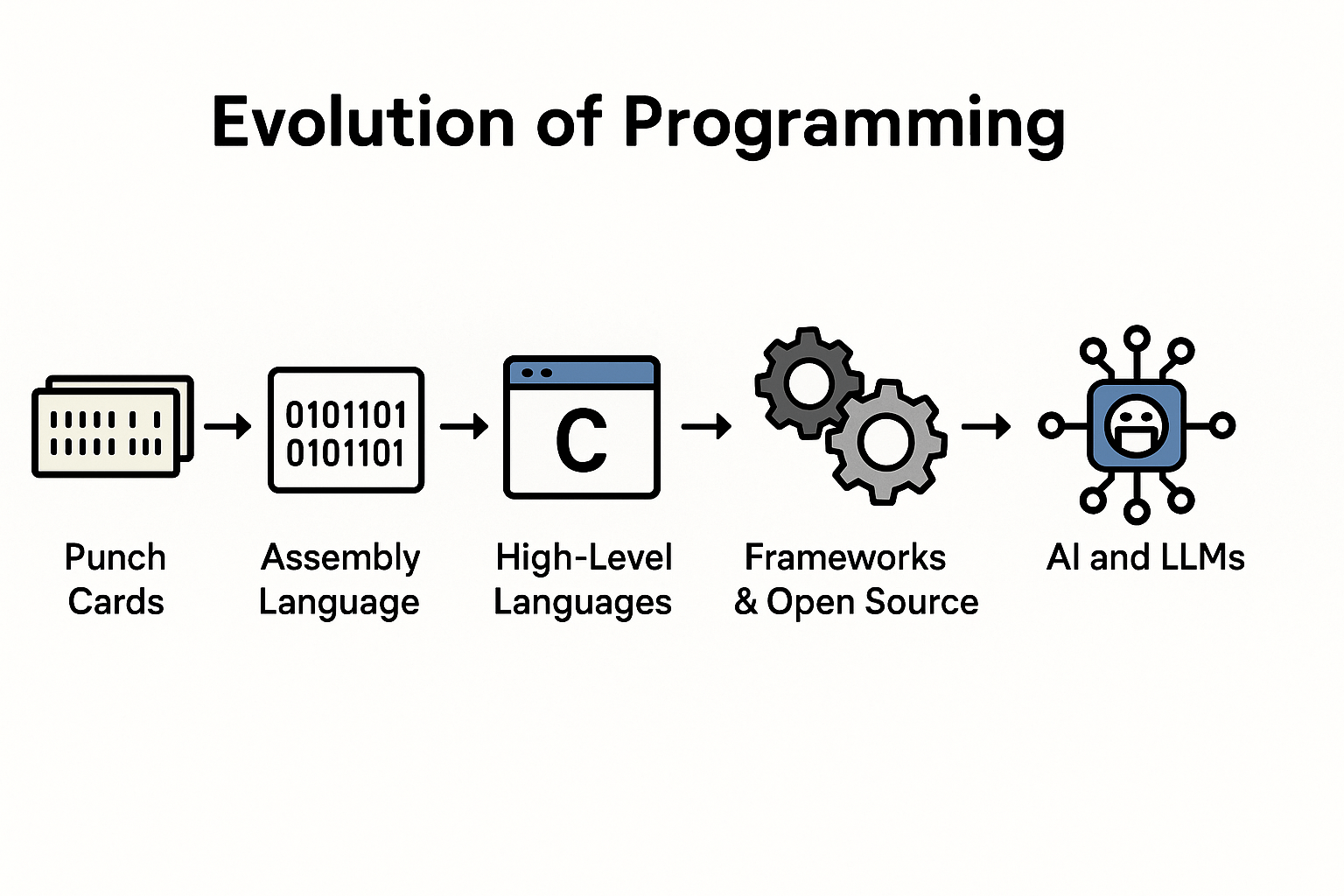

🧱 Layer 0: Physical Switches & Punch Cards
Total control. No productivity. Every bit was your problem.
🧠 Layer 1: Assembly
Readable by machine and sad humans. Precision required. Errors fatal.
🔤 Layer 2: High-Level Languages (C, FORTRAN)
You write logic; the compiler handles machine details. This was the first big win: abstraction that didn’t cost traceability.
🧰 Layer 3: OOP and Dynamic Languages
Java, Python, PHP, C#. We got encapsulation, interfaces, and tooling. We also got frameworks, side effects, and runtime mysteries.
🔮 Layer 4: Frameworks, ORMs, DevTools
Laravel, Doctrine, Spring, React, ESLint. Magic happened. And so did performance bugs, leaky abstractions, and ten-minute stack traces.
Now?
🎲 Layer 5: LLMs (Large Language Models)
A stochastic machine trained to guess what code probably looks like based on tokens, not truth.
It’s autocomplete on steroids.
You say “Create a REST API for orders” — it gives you ten files and a Repository that “just works.”
Until it doesn’t.
Because here’s the core issue:
-
It doesn’t understand your domain.
-
It doesn’t know your technical debt.
-
It doesn’t track business rules.
-
It doesn’t care about your security policies.
And teams are merging this output like it’s a pull request from a trusted senior engineer.
Let me be clear:
LLMs are not teammates. They’re not compilers. They’re not even junior devs.
They’re trained to emit high-probability syntax. That’s it.
Yet we’re dropping their output straight into main, bypassing all the trust boundaries we spent decades learning to respect.
Remember the golden rule?
Don’t edit generated code.
We follow it for compilers, transpilers, ORMs, and IaC tools.
But when ChatGPT writes a controller? We treat it like gospel.
That’s technical debt in disguise. And it’s scaling faster than any abstraction layer before it.
The Strategy – Separate the ‘Why’ from the ‘How’
Here’s the fundamental mismatch:
LLMs generate the how. But only humans can define the why.
Yet we’re letting the “how” flow freely into production without anchoring it to the business context, architectural rationale, or historical landmines it depends on.
This isn’t a tooling problem. It’s a systems thinking failure.
To fix it, we need to separate generation from intent, and introduce a strict boundary between code that is guessed and code that is trusted.
Here’s the strategy:
🧱 Part 1: Define a Compiler-Compatible Blueprint Format (Own the Intent)
We don’t want AI writing raw PHP, Java, or Python.
We want it writing structured blueprints that describe behavior, constraints, and flow —
not implementation.
You then build a compiler that transforms these blueprints into safe, production-ready code using your stack, your rules, and your team’s architecture patterns.
✅ Blueprint Example (YAML – Compiler-Ready)
function: getActiveUserEmail
description: Return email of an active user or fail with domain-level exceptions
inputs:
- name: userId
type: Domain.UserId
output:
type: Domain.EmailAddress
rules:
- businessRule: Only active users can access the system
- security:
concern: InfoDisclosure
severity: High
mitigation: Throw domain-specific exceptions
- maintainability:
smell: MagicString
notes: Replace 'active' string with enum
steps:
- fetch:
from: UserRepository
method: findById
input: userId
output: user
- guard:
if: user == null
then: throw DomainError.UserNotFound
- guard:
if: user.status != ACTIVE
then: throw DomainError.UserInactive
- return:
value: user.email
⚙️ Why This Works:
-
Compiler-friendly: Each step maps cleanly to deterministic code generation.
-
LLM-compatible: Easy for AI to generate and validate.
-
Auditable: You can version this. You can diff it. You can reason about it.
-
Stack-agnostic: One blueprint, many possible code outputs (Laravel, Symfony, NestJS, Spring).
-
Intent-driven: You encode what needs to happen — and enforce how through rules.
Your compiler becomes the enforcement layer:
-
It checks the blueprint against your domain model.
-
It injects architecture-specific behavior (validation, DI, error handling).
-
It produces safe, maintainable, consistent code.
Blueprints are your contract with the machine.
Your compiler is the gatekeeper.
LLMs are just assistants — they don’t write production code; they write proposals.
🧩 Part 2: Embed the ‘Why’ Directly Into Your Codebase (Own the Context)
You don’t just need structure in generated code —
You need context in your existing code.
That’s where metadata comes in: structured, machine-readable, developer-accessible annotations that tell humans and LLMs why a piece of logic exists.
✅ Example (PHP Attributes)
#[BusinessRule("Only active users may access features")]
#[Security(concern: "UnauthorizedAccess", severity: "Critical")]
#[Maintainability(smell: "MagicString", notes: "Replace 'active' with enum")]
public function getActiveUserEmail(UserId $userId): EmailAddress
{
// ...
}
These attributes:
-
Can be enforced in CI with static analysis (PHPStan, Psalm, custom Rector rules)
-
Provide structure for documentation generation
-
Are readable by future devs and future AI tools
-
Make implicit decisions explicit
Is this over-engineering?
Or is it the minimum bar if you expect maintainable AI-integrated systems?
Let’s be honest: if we’re still coding the same way five years from now — merging raw AI output without structure, rules, or traceability — it won’t be because it works.
It’ll be because we never had the discipline to build something better.


