We’ve all heard the promises of Agile: faster delivery, more flexibility, and a better team dynamic. But let’s face it—Agile won’t save your project if the foundation isn’t right. Frameworks are tools, not magic wands, and success depends on one key factor: your people. Without commitment, purpose, and vision, even the best methodology falls flat.
Commitment Is the Foundation
In every successful project I’ve seen, there’s one constant: the team cares. They’re passionate about the project, the technology, or the customer. When people are engaged, they bring their A-game. Without that commitment, Agile rituals become hollow motions—stand-ups where no one stands up for quality and retrospectives that only scratch the surface.
But how do you ignite that spark?
Give Purpose: Teams perform better when they know why their work matters. Whether it’s a product that changes lives or a system that transforms workflows, connect the dots between their efforts and the bigger picture.
Empower Ownership: Nothing kills commitment faster than micromanagement. Give your team the autonomy to solve problems their way, and they’ll take pride in their work.
Set the North Star: Someone needs to have the big picture in mind. This isn’t about controlling every detail; it’s about providing clarity and direction. A team without a vision is just a group of people checking tasks off a backlog.
Agile: A Framework, Not a Fix
Agile isn’t inherently bad—it’s just not a silver bullet. A poorly implemented Agile process can feel like busy work, creating friction instead of flow. You’ve seen it: endless sprints with no tangible value, misaligned priorities, and teams that are Agile in name only.
The truth is, Agile is just a tool, and like any tool, its effectiveness depends on how you use it. Without the right culture, mindset, and leadership, Agile can’t thrive.
The Power of Flow
When your team is committed and has a clear purpose, they enter the elusive “flow” state. Flow is where the magic happens: work feels both challenging and enjoyable, and everything just clicks. Achieving flow requires more than process—it demands an environment that fosters focus, removes blockers, and aligns everyone toward shared goals.
Common Pitfalls in Agile Projects
Lack of Vision: If the goals are unclear, the team loses direction. Agile iterations can’t compensate for a missing strategy.
Token Empowerment: Teams are told they’re empowered, but their decisions are constantly overridden by management.
Process Over People: Agile becomes a checkbox exercise, focusing on rituals instead of outcomes.
Burnout Culture: Passion doesn’t mean working endless hours. A healthy pace is critical for long-term success.
Building the Right Environment
Here’s what makes the difference:
Clarity and Direction: Define a clear vision and align the team’s work with it. Avoid vague objectives—make the goals tangible and achievable.
Purposeful Leadership: Leaders need to support, not control. Their role is to remove obstacles, align efforts, and amplify strengths.
Empowerment: Trust your team to make decisions. Give them the tools, autonomy, and confidence to innovate.
Continuous Reflection: Agile emphasizes improvement, but that requires honesty. Create a safe space for open feedback and genuine introspection.
Final Thoughts: Commitment Over Process
At the end of the day, success isn’t about following Agile to the letter. It’s about creating an environment where your team thrives. Agility is just one piece of the puzzle. Your team’s commitment, passion, and purpose are what truly drive results.
So don’t just “go Agile.” Build a culture that values people over processes, outcomes over rituals, and vision over micromanagement. Agile might not save your project, but your team will.
🚀 Because in the end, your people are your greatest asset.
Optimizing inputs for LLMs ensures better, more consistent outputs while leveraging the full potential of the model’s underlying capabilities. By understanding core concepts like tokenization, embeddings, self-attention, and context limits, you can tailor inputs to achieve desired outcomes reliably. Below, you’ll find fundamental techniques and best practices organized into practical strategies.
🎯 1. Controlling Probabilities: Guide Model Outputs
🧠 Theory: LLMs always follow probabilities when generating text. For every token, the model calculates a probability distribution based on the context provided. By carefully structuring inputs or presenting examples, we can shift the probabilities toward the desired outcome:
Providing more examples helps the model identify patterns and generate similar outputs.
Clear instructions reduce ambiguity, increasing the probability of generating focused responses.
Contextual clues and specific phrasing subtly guide the model to prioritize certain outputs.
⚙️ Technology: The model operates using token probabilities:
Each token (word or part of a word) is assigned a likelihood based on the input context.
By influencing the input, we can make certain tokens more likely to appear in the output.
For example:
A general query like “Explain energy sources” might distribute probabilities evenly across different energy types.
A more specific query like “Explain why solar energy is sustainable” shifts the probabilities toward solar-related tokens.
⚙️ Shifting Probabilities in Prompts: The structure and wording of your prompt significantly influence the token probabilities:
For specific outputs: Use targeted phrasing to increase the likelihood of desired responses: Explain why renewable energy reduces greenhouse gas emissions.
For diverse outputs: Frame open-ended questions to distribute probabilities across a broader range of topics: What are the different ways to generate clean energy?
Few-Shot Learning: Guide the model using few-shot learning to set patterns: Example 1: Input: Solar energy converts sunlight into electricity. Output: Solar energy is a renewable power source. Example 2: Input: Wind energy generates power using turbines. Output: Wind energy is clean and sustainable. Task: Input: Hydropower generates electricity from flowing water. Output:
💡 Prompt Tips:
Use clear, direct instructions for precise outputs: Write a PHP function that adds two integers and returns a structured response as an array.
Use contextual clues to steer the response: Explain why PHP is particularly suited for web development.
💻 Code Tips: LLMs break down code and comments into tokens, so structuring your PHPDocs helps focus probabilities effectively. Provide clarity and guidance through structured documentation:
/**
* Adds two integers and returns a structured response.
*
* @param int $a The first number.
* @param int $b The second number.
*
* @return array{result: int, message: string} A structured response with the sum and a message.
*/
function addIntegers(int $a, int $b): array {
$sum = $a + $b;
return [
'result' => $sum,
'message' => "The sum of $a and $b is $sum."
];
}
Include examples in PHPDocs to further refine the probabilities of correct completions: /** * Example: * Input: addIntegers(3, 5) * Output: [‘result’ => 8, ‘message’ => ‘The sum of 3 and 5 is 8’] */
✂️ 2. Tokenization and Embeddings: Use Context Efficiently
🧠 Theory: LLMs break down words into tokens (numbers) to relate them to each other in multidimensional embeddings (vectors). The more meaningful context you provide, the better the model can interpret relationships and generate accurate outputs:
Tokens like “renewable energy” and “sustainability” have semantic proximity in the embedding space.
More context allows the model to generate richer and more coherent responses.
⚙️ Technology:
Tokens are the smallest units the model processes. For example, “solar” and “energy” may be separate tokens, or in compound languages like German, one long word might be broken into multiple tokens.
Embeddings map these tokens into vectors, enabling the model to identify their relationships in high-dimensional space.
⚙️ Optimizing Tokenization in Prompts: To make the most of tokenization and embeddings:
Minimize irrelevant tokens: Focus on core concepts and avoid verbose instructions.
Include context-rich phrases: Relevant terms improve the embedding connections.
Simplify Language: Use concise phrasing to minimize token count: Solar energy is renewable and reduces emissions.
Remove Redundancy: Eliminate repeated or unnecessary words: Explain why solar energy is sustainable.
💡 Prompt Tips:
Include only essential terms for better embedding proximity: Describe how solar panels generate electricity using photovoltaic cells.
Avoid vague or verbose phrasing: Explain solar energy and its uses in a way that a normal person can understand and provide details.
Use specific language to avoid diluting the context: Explain why solar energy is considered environmentally friendly and cost-effective.
Avoid vague instructions that lack actionable context: Explain me solar energy.
💻 Code Tips: Write compact and clear PHPDocs to save tokens and improve context:
/**
* Converts raw user input into a structured format.
*
* @param string $input Raw input data.
*
* @return array{key: int, value: string} Structured output.
*/
function parseInput(string $input): array {
$parts = explode(":", $input);
return [
'key' => (int)$parts[0],
'value' => trim($parts[1])
];
}
Use compact and descriptive documentation to maximize token efficiency: /** * Example: * Input: “42:Hello” * Output: [‘foo’ => 42, ‘bar’ => ‘Hello’] */
🧭 3. Self-Attention and Structure: Prioritize Context
🧠 Theory: LLMs work with the principle of self-attention, where the input tokens are interrelated with each other to determine the relevance and context. This mechanism assigns importance scores to tokens, ensuring that the most relevant words and their relationships are prioritized.
⚙️ Technology:
Self-attention layers: Compare each token with every other token in the input to generate an attention score.
Multi-head attention: Allows the model to consider multiple perspectives simultaneously, balancing relevance and context.
Pitfall: Too many irrelevant tokens dilute the attention scores, leading to distorted outputs.
⚙️ Optimizing Structure in Prompts:
Structure Your Inputs: Use lists, steps, or sections to emphasize relationships: Compare the benefits of solar and wind energy: 1. Environmental impact 2. Cost-efficiency 3. Scalability
Minimize Irrelevant Tokens: Keep prompts focused and free from extraneous details.
💡 Prompt Tips:
Well-Structured: Organize tasks into sections: Explain the environmental and economic benefits of renewable energy in two sections: 1. Environmental 2. Economic
Unstructured: Avoid asking everything at once: What are the environmental and economic benefits of renewable energy?
💻 Code Tips: In PHPDocs, organize information logically to enhance clarity and guide models effectively:
🧠 Theory: LLMs operate within a fixed token limit (e.g., ~8k tokens for GPT-4), encompassing both input and output. Efficiently managing context ensures relevant information is prioritized while avoiding irrelevant or redundant content.
⚙️ Technology:
Chunking: Break long inputs into smaller, manageable parts: Step 1: Summarize the introduction of the report. Step 2: Extract key arguments from Section 1. Step 3: Combine summaries for a final overview.
Iterative Summarization: Condense sections before integrating them: Summarize Section 1: Solar energy’s benefits. Summarize Section 2: Wind energy’s benefits. Combine both summaries.
Pitfall: Excessive context can truncate critical data due to token limits.
💡 Prompt Tips:
For large inputs, use step-by-step processing: Step 1: Summarize the introduction of the document. Step 2: Extract key arguments from Section 1. Step 3: Combine these points into a cohesive summary.
Avoid presenting the full text in a single prompt: Summarize this 20-page document.
Focus on specific sections or tasks: Summarize the introduction and key points from Section 1.
💻 Code Tips: Divide tasks into smaller functions to handle token limits better:
function summarizeSection(string $section): string {
// Summarize section content.
}
function combineSummaries(array $summaries): string {
// Merge individual summaries.
}
🎨 5. Reasoning and Goals: Strengthen Prompt Direction
🧠 Theory: LLMs generate better results when the reasoning behind a task and its intended goal are explicitly stated. This guides the model’s probabilities toward meaningful and relevant outcomes.
⚙️ Technology:
Explicit reasoning provides semantic depth, helping the model focus on the task’s purpose.
Explaining the goal improves alignment with user expectations and narrows token probabilities.
💡 Prompt Tips:
State the reason for the task and its goal: Explain renewable energy because I need to create an introductory guide for high school students.
Avoid generic prompts without a clear goal: Describe renewable energy.
💻 Code Tips: Use PHPDocs to explain both the reasoning and expected outcomes of a function:
/**
* Generates a detailed user profile report.
*
* This function is designed to create a comprehensive profile report based on user data inputs.
* It is useful for analytical dashboards requiring well-structured user insights.
*
* @param array{name: string, age: int, email: string} $userData The user data array.
*
* @return string A formatted profile report.
*/
function generateProfileReport(array $userData): string {
return sprintf(
"User Profile:\nName: %s\nAge: %d\nEmail: %s\n",
$userData['name'],
$userData['age'],
$userData['email']
);
}
🧠 Theory: Breaking down complex tasks into smaller, manageable steps improves accuracy and ensures the model generates focused and coherent outputs. This method allows you to iteratively refine results, combining outputs from smaller subtasks into a complete solution.
⚙️ Technology:
Chunking: Split large tasks into multiple smaller ones to avoid overwhelming the model.
Validation: Intermediate outputs can be validated before moving to the next step, minimizing errors.
Recombination: Smaller validated outputs are merged for the final result.
💡 Prompt Tips:
For multi-step tasks, provide clear, incremental instructions: Step 1: Summarize the environmental benefits of solar energy. Step 2: Describe the cost savings associated with solar energy. Step 3: Combine these summaries into a single paragraph.
Avoid handling complex tasks in a single step: Explain the environmental benefits and cost savings of solar energy in one response.
💻 Code Tips: Ask the LLM to create the code step by step and ask for confirmation after each step so that the LLM can focus on one aspect of the implementation at a time. Focus on one aspect of the implementation at a time.
🧠 Theory: LLMs lack persistent memory between interactions, making it essential to reintroduce necessary context for consistent responses across prompts. By maintaining cross-contextual coherence, outputs remain aligned and relevant, even in multi-step interactions.
⚙️ Technology:
Use context bridging: Reference key elements from previous responses to maintain relevance.
Store critical details in persistent structures, such as arrays or JSON, to reintroduce when needed.
Avoid overloading with irrelevant details, which can dilute coherence.
💡 Prompt Tips:
Reintroduce essential context from previous interactions: Based on our discussion about renewable energy, specifically solar power, explain the benefits of wind energy.
Summarize intermediate outputs for clarity: Summarize the main benefits of renewable energy. Then expand on solar and wind energy.
💻 Code Tips: Use seperated files for Code-Examples that we can provide e.g. Custom GPTs so it can learn from learnings/findings this way.
🌍 8. Style and Tone: Adapt Outputs to the Audience
🧠 Theory: LLMs generate better responses when the desired style and tone are explicitly stated. By matching the tone to the audience, you can make content more engaging and effective.
⚙️ Technology:
The model uses semantic cues in the prompt to adjust style and tone.
Specific words and phrases like “formal,” “casual,” or “technical” help steer the model’s output.
💡 Prompt Tips:
Specify the tone and audience: Write a technical explanation of solar panels for an engineering audience.
Adjust the style for different contexts: Explain solar panels in a simple and friendly tone for kids.
💻 Code Tips: In PHPDocs, define the intended audience and tone to guide LLM-generated documentation:
/**
* Calculates the total energy output of a solar panel system.
*
* Intended Audience: Engineers and technical experts.
* Tone: Formal and technical.
*
* @param float $panelArea The total area of solar panels in square meters.
* @param float $efficiency The efficiency rate of the solar panels (0-1).
* @param float $sunlightHours Daily sunlight hours.
*
* @return float Total energy output in kilowatt-hours.
*/
function calculateSolarOutput(float $panelArea, float $efficiency, float $sunlightHours): float {
return $panelArea * $efficiency * $sunlightHours;
}
🔍 9. Fine-Tuning and Domain Expertise
🧠 Theory: Fine-tuning allows LLMs to specialize in specific domains by further training them on domain-specific datasets. This enhances their ability to generate accurate, relevant, and nuanced outputs tailored to specialized tasks or fields.
⚙️ Technology:
Fine-tuning adjusts the weights of a pre-trained model by using a curated dataset that focuses on a specific domain.
This process requires labeled data and computational resources but significantly improves task performance in niche areas.
💡 Prompt Tips:
Use fine-tuning to simplify prompts for repeated tasks: Generate a legal brief summarizing the key points from this case.
Without fine-tuning, include detailed instructions and examples in your prompt: Write a summary of this legal case focusing on liability and negligence, using a formal tone.
💻 Code Tips: When fine-tuning is not an option, structure your PHPDocs to include domain-specific context for LLMs:
/**
* Generates a compliance report for renewable energy projects.
*
* This function creates a detailed compliance report tailored for regulatory agencies. It checks for adherence to
* energy efficiency standards and sustainability guidelines.
*
* @param array<string, mixed> $projectData Details of the renewable energy project.
* @param string $region The region for which the compliance report is generated.
*
* @return string The compliance report in a formatted string.
*/
function generateComplianceReport(array $projectData, string $region): string {
// Example report generation logic.
return sprintf(
"Compliance Report for %s:\nProject: %s\nStatus: %s\n",
$region,
$projectData['name'] ?? 'Unnamed Project',
$projectData['status'] ?? 'Pending Review'
);
}
The year 2050 is closer than the year 1990, yet we’re still writing code like it’s the 1800s.
It’s 2025, and while we’ve made incredible strides in software development—automated memory management, static analysis tools, refactoring IDEs, and AI copilots like ChatGPT—it still feels like the Wild West. Sure, the tools are better, but the way we approach software remains chaotic, inefficient, and overly reliant on custom solutions.
Every day, thousands of developers solve the same problems repeatedly. Companies roll out their own authentication systems, file upload handlers, and error trackers. Many of these are flawed. Vulnerabilities creep in because we’re not building resilient systems—we’re building digital bonfires.
This isn’t progress. This is the time before the First Industrial Revolution of Software Development.
Lessons from History: What the Past Teaches About Our Digital Fires
1. The Great Fire of Hamburg (1842): Building Without Safety
In 1842, a quarter of Hamburg burned to the ground. The city’s lack of fire safety standards—wooden buildings, narrow streets, no prevention systems—made disaster inevitable.
Software today mirrors this recklessness:
File upload systems without malware checks.
APIs with vulnerabilities because “it’s faster to skip security.”
Custom-built logging systems without consistency or reliability.
After the fire, Hamburg rebuilt with fireproof materials and strict regulations. We need the same shift in software development: adopting universal standards, secure-by-design frameworks, and centralized tools to prevent disaster before it happens.
2. Electrical Sockets in the Early 1900s: Chaos Without Standards
Before standardization, electrical sockets were a mess. Every region had its own plug type, making interoperability nearly impossible. Plugging in a device often meant wasting time finding the right adapter.
Software development today is no different:
APIs lack consistent patterns.
Libraries solve the same problem in incompatible ways.
Developers reinvent logging, error handling, and authentication with every project.
The solution? Standardized, language-agnostic tools—the equivalent of universal plug designs. Imagine APIs and services that integrate seamlessly across languages and frameworks:
Centralized logging and error tracking APIs, similar to Sentry but designed for internal use with cross-language compatibility.
High-performance Unix socket APIs for tasks like logging, monitoring, and file scanning.
Shared SDKs for foundational needs like security or metrics collection.
By building shared infrastructure, we could eliminate redundant work and improve reliability across projects.
3. The Facade Problem: Buying Software for Looks, Not Stability
Imagine buying a house because the facade looks amazing but never checking the foundation. That’s how most software is evaluated today:
Buyers focus on flashy UIs and marketing demos.
Security, scalability, and maintainability are often ignored.
This approach leads to brittle, insecure systems. What’s missing? Inspectors for digital bridges—specialized roles that assess software foundations, enforce accountability, and ensure systems are solid beneath their shiny exteriors.
Moving Toward the First Industrial Revolution of Software Development
The Industrial Revolution replaced handcrafting with standardization and mass production. Software development is still stuck in its pre-industrial phase:
Custom solutions are built repeatedly for the same problems.
Accountability is rare—no one ensures the “bridge” (software) is stable before it’s deployed.
To mature as an industry, we need:
1. Universal Blueprints
Developers today still create bespoke solutions for common problems. We need standardized tools and APIs, such as:
A unified SDK for antivirus scanning, accessible via /usr/sbin/antivirus or unix:///var/run/antivirus.
Centralized APIs for error tracking, metrics, and monitoring, with cross-language support.
2. Specialized Roles
In the 19th century, collapsing bridges led to the creation of specialized roles: architects for design, builders for execution, and inspectors for safety. Software teams need similar specialization:
System Inspectors to evaluate software for security, scalability, and maintainability.
Digital Firefighters to enforce standards and proactively address vulnerabilities.
3. Accountability
When a bridge collapses, someone is held responsible. In software, failures are often patched silently or ignored. We need:
Transparency: Bugs and vulnerabilities must be documented openly.
Retrospectives: Focused on systemic improvements, not just quick fixes.
Building Digital Cities That Don’t Burn
Imagine a future where software is built like modern cities:
Fireproof Systems: Universal standards for security, maintainability, and testing.
Digital Firefighters: Publicly funded teams safeguarding critical infrastructure.
Inspectors for Digital Bridges: Specialized roles ensuring software is built to last.
AI tools like GPT can help accelerate this process, but they are not the solution. AI is like the steam engine of programming—amplifying productivity but requiring skilled operators. If we don’t lay the right foundations, AI will only magnify our inefficiencies.
This future isn’t about writing more code—it’s about creating resilient, scalable systems that stand the test of time. The tools to build fireproof digital cities are already here. The question is: are we ready to use them?
Let’s move beyond the Wild West of coding and into the Industrial Revolution our industry desperately needs. It’s time to stop building bonfires and start building something that lasts.
After some years, working with a > 10 years old legacy PHP codebase, I can truly say: you can escape the legacy codebase and introduce whatever is helpful, in a well-maintained system.
Here are 5 important steps that I have done:
Custom error handling: Reporting notices for developers, report bad “assert” calls in the dev container, report bad indexes, reporting wrong code usage, …
Autocompletion for everything: classes, properties, SQL queries, CSS, HTML, JavaScript in PHP (e.g. via /* @lang JavaScript */ in PhpStorm), …
Static-Code Analysis: Preventing bugs is even better than fixing bugs, so just stop stupid bugs and use types in your code.
Automate the refactoring: With tools like PHP-CS-Fixer or Rector you can not only fix your code one time, you can fix any future wrong usage of the code.
Do not use strings for code: Just use constants, classes, properties, … use something that can be processes by your static-code analysis and something where you will have autocompletion.
Here are 5 additional steps that I already introduce:
Sentry: External error collecting (aggregating) tool + custom handler to see e.g. IDs of every Active Record object.
Generics: via PHPDocs + autocompletion via PhpStorm
No “mixed” types: Now we use something like, e.g. “array<int, string>” instead of “array”.
PSR standards: e.g. PSR-15 request handler, PSR-11 container, PSR-3 logger, …
Code Style: One code style to rule them all, we use PHP-CS-Fixer and PHP-Code-Sniffer to check / fix our code style for all ~ 10,000 PHP classes.
Here is what helped me mostly while working with old existing code.
First rule, first: 🥇 think or / and ask someone in the team
Analyzing: Here are some things that helped my analyzing software problems in our codebase.
Errors: Better error handling / reporting with a custom error handler, with all relevant information.
Understandable logging: Hint, you can just use syslog for medium-sized applications.
Grouping errors: Displaying and grouping all the stuff (PHP / JS / errors + our own custom reports) into Sentry (https://sentry.io/), now you can easily see how e.g. how many customers are effected from an error.
git history: Often new bugs were introduced with the latest changes (at least in often used components), so that good commit messages are really helpful to find this changes. (https://github.com/voku/dotfiles/wiki/git-commit-messages)
Local containers: If you can just download the application with a database dump from yesterday, you can analyze many problems without touching any external server.
Linux tools: mytop, strace, htop, iotop, lsof, …
Database tools: EXPLAIN [SQL], IDE integration / autocompletion, …
Fixing: Here are some tricks for fixing existing code more easily.
IDE: PhpStorm with auto-completion and suggestions (including results from static analysis)
auto-code-style formatter: (as pre-commit hook) is also helpful because I do not need to think about this anymore while fixing code
git stuff: sometimes it can also be helpful to understand git and how to revert or cherry-pick some changes
Preventing: Here are some hints how you can prevent some bugs.
root cause: fixing the root cause of a problem, sometimes this is very hard because you need to fully understand the problem first, bust mostly spending this time is a good investment
testing: writing a test is always a good idea, at least to prevent the same problem
I will start a new job next month (02-2023), so time to recap, I’m going to describe what I’ve learned so far.
me: Lars Moelleken | > Assistant for business IT > IT specialist for system integration > IT specialist for application development
What did I learn as IT specialist for system integration?
– You only learn as much as you want to learn.
In contrast to school / technical college, I could and had to teach and work on many things myself during the training. And you quickly realize that you only learn as much as you want. Once you’ve understood this, you’re happy to sit down and learn whatever you want. For example, local or online courses, go to meetups or conferences. Worry about your skill because if you do something, you should do it right.
“An investment in knowledge still pays the best interest.” – Benjamin Franklin
– No panic!
What you learn pretty quickly as a sysadmin is “keep calm” and think first – then act. Hasty actionism does not help and usually even damages. Before you act, you should first obtain some information yourself (information from log files, hardware status, system status, …) so that you really know how to fix the error.
– Unix & command line <3
If you haven’t worked with a Unix operating system before, you unfortunately don’t know what you’re missing out on. If you want or have to use Windows for whatever reason, you can nowadays still use some of the advantages of Linux via WSL (Windows Subsystem for Linux). Leave your own comfort zone and trying out new operating systems helps to understand your computer better overall. At this point, I would have recommended “Arch Linux” as sysadmin, but today I would choose something that needs less maintaining.
One should also become familiar with the command line if you want to increase your productivity rapidly. For example, you should take a closer look at the following commands: e.g. find / grep / lsof / strace
– Read the official documentation.
It is often better to read the official documentation of the thing (hardware || software) you are currently using. While you start programming or learn a new programming language / framework, we often use stackoverflow.com and quickly finds answers and code examples, but the “why” and “how” is usually neglected. If you look at the specification / documentation first, you not only solve this problem, you also understand the problem, and maybe you will learn how to solve similar problems.
– Always make a backup (never use “sudo” drunken).
Some things you have to learn the hard way, apparently installing “safe-rm” was part of it for me!
apt-get install safe-rm
“Man has three ways of acting wisely. First, on meditation; that is the noblest. Secondly, on imitation; that is the easiest. Thirdly, on experience; that is the bitterest.” – (Confucius)
– Be honest with customers, employees and yourself.
Be honest with customers, especially when things go wrong. If the customer’s product (e.g. server) fails, then offer solutions and no excuses and solve the problem, not the question of blame. No one is helped by pointing the finger at colleagues or customers, not at the server, not at the customer and ultimately not at yourself.
– Ask questions if you don’t understand something.
Don’t talk to customers about something you don’t understand, not knowing something (especially in training) is fine, but then ask a colleague before you talk to a customer about it!
– Think about what you are doing (not only at work).
If you question things and think about your work and what you do, then you can develop personally. Question critical, for example, whether you should really order from Amazon, or should you rather order the book directly from the publisher? What is the advantage for the author and do I have any disadvantages? Should we use Nagios or rather Icinga directly? Question your work and critically evaluate whether this is really a good / safe / future-oriented solution.
If you are not sure yourself or your perspective is too limited (because you only know this one solution, for example), then you should acquire new knowledge, research other solutions or “best practices” and discuss the topic with others.
– Use Google correctly …
1. When searching an issue, look for the error message in quotes: “Lars Moelleken”
What did I learn as IT specialist for application development?
– You never stop learning…
When you start to deal with web programming (HTML, CSS, JS, PHP, …), you don’t even know where to start. There is so much to learn, and this feeling accompanies you for some time (years) until you recognize recurring concepts. However, the advantage in web programming is that many different things have common APIs or at least can be combined. I can write a class in PHP that creates data attributes for my HTML, which I can read out with JavaScript to design them accordingly using CSS classes. But it stays the same, you never stop learning, and that’s also what’s so exciting about this job.
– Try to write code every day. (but set yourself a LIMIT)
Even if the boss isn’t in the office today, and you don’t have any more tasks, then write some code, if you’re sitting on the couch at home (and no new series is running on Netflix), then write or read some code and if you’re on vacation, you’re on vacation!
If you write software every day, you don’t want to code the same functionality (e.g. database connection, send e-mail or error logging …) multiple times for different projects (and remember, mostly you don’t want to code standard functions yourself). Therefore, every programmer should think in modules and design an application in different, preferably interchangeable parts. Often, the system can then also be expanded better, since there is already an interface for modules that can be used. The independence and decoupling of program parts also has the advantage that side effects from different places in the source code are further avoided. In addition, one should minimize the coupling of the corresponding modules, otherwise one gains nothing from modules.
There are already package managers for almost everything in web development. e.g.: – Frontend (css, js): npm – Backend (php): composer
– Open-Source-Software
If you are already working with modules and packages, you can publish them as an OSS project + run tests via GitHub actions + code coverage + at least a small amount of documentation. For these reasons alone, publishing as open source is worthwhile. The code quality also increases (in my experience), since the source code is released to the public and therefore more or less conscious attention is paid to the code quality.
The moment when you get your first pull request for your software or code together with someone from Israel, Turkey and the USA is priceless.
At some point, you would like to have the same advantages of OSS in your daily work because often, there is no package (code is directly added into the existing code), no tests (even not for bugs) and no documentation. So, possibly, you have now collected enough arguments to convince your boss to publish some package from your code at work.
– Git & Good
I don’t know how people can work with the PC without version control. I even use “git” for smaller private projects or for configuration files. The following are some advantages, but the list can certainly be extended with a few more points:
– changes can be traced (git log, git blame) – changes can be undone (git revert, git reset) – changes can be reviewed by other employees – employees can work on a project at the same time (git commit, git pull, git push) – development branches (forks) can be developed simultaneously (git checkout -b , git branches)
– Use GitHub and learn from the best.
GitHub itself is not open-source, but there has been an unofficial agreement to use the platform for open-source projects. You can therefore find many good developers and projects there, and you can learn a lot just by reading the source code / changes. Especially because you can understand and follow the development of the projects: How do others structure your code? How do others write their “commit” messages? How much code should a method contain? How much code should a class contain? Which variable names are better to avoid? How to use specific libraries / tools? How do others test their code? …
– try { tests() }
Especially when you write tests for your own code, you catch yourself testing exactly the cases that you have already considered, so you should test the corresponding functionality with different (not yet considered) input. Here are some inputs for testing: https://github.com/minimaxir/big-list-of-naughty-strings
Hint: We should add another test whenever an error occurred, so that already fixed error does not come back to use.
– Automate your tests.
Unit tests, integration tests and front-end tests only help if they are also executed, so you should deal with automated tests at an early stage and also run them automatically when the source code changes. Where and when these tests are run also determines how effective these tests ultimately are. As soon as you have written a few tests, you will understand why it is better not to use additional parameters for methods and functions, since the number of tests increases exponentially.
– Deployment is also important.
As soon as you work with more than one developer on a project, or the project will become more complex, you want to use some kind of deployment. As in application development, often the simplest solution is also here a good starting point: e.g. just pull the given changes into a directory and change the symlink from the existing source directory so that you can switch or rollback all files easily. PS: And you properly never need to write database-migration rollbacks, I never used them.
– Understanding concepts is more important than implementing them.
Understanding design patterns (programming concepts) not only helps in the current programming language, but can mostly be applied to other programming languages as well.
Basic concepts (classes, objects, OOP, functions, ORM, MVC, DDD, unit tests, data binding, router, hooks, template engine, …) can be found in many frameworks / programming languages and once you have understood the terms and concepts, it is no longer that difficult to use new / different frameworks. And you can see different strengths and weaknesses of these frameworks and tools: “If you only have a hammer as a tool, you see a nail in every problem.”
– Solving problems also means understanding customers.
Design patterns are part of the basic equipment, but you should always ask yourself: Which problem is actually supposed to be solved with the given solution? If necessary, you can find an even more elegant / simpler solution. And sometimes the customer actually wants something thoroughly different, he just doesn’t know it yet or someone has misunderstood the customer.
– Solving problems also means understanding processes.
But it is just as important to understand why a certain feature is implemented, and otherwise you are programming something that is either not needed or used at all. One should therefore understand the corresponding task before implementation and even before planning in the overall context.
– Spread code across multiple files.
Use one file for a class, use one file for CSS properties of a module or a specific page, use a new file for each new view. Dividing the source code into different files / directories offers many advantages, so the next developer knows where new source code should be stored and you can find your way around the source code faster. Many frameworks already provide a predefined directory structure.
– Readability comes first!
The readability of source code should always come first, since you or your work colleagues will have to maintain or expand this code in the future.
– Good naming is one of the most difficult tasks in programming.
It starts with the domain name / project name, goes through file names, to directory names, class names, method names, variable names, CSS class names. Always realize that others will read this and need to understand it. Therefore, you should also avoid unnecessary abbreviations and write what you want to describe.
We want to describe what the function does and not how it is implemented.
Good comments explain “why” and not “what” the code is doing, and should offer the reader added value that is not already described in the source code.
Sometimes it makes sense to add some “what” comments anyway, e.g. for complicated regex or some other not optimal code that needs some hints.
Examples of inline comments:
bad code:
// Check if the user is already logged in if ( isset ( $_SESSION['user_loggedin']) && $_SESSION['user_loggedin'] > 1 ) { ... }
slightly better code:
// check if the user is already logged-in
if ( session ( 'user_loggedin' ) > 1 ) { ... }
– Consistency in a project is more important than personal preferences!
Use the existing code and use given functions. If it brings benefits, then change / refactor the corresponding code, but then refactor all places in the project which are implemented in this way.
Example: If you have formerly worked without a template system and would like to use one for “reasons”, then use this for all templates in the project and not just for your current use case; otherwise, inconsistencies will arise in the project. For example, if you create a new “Email→isValid()” method, then you should also replace all previous RegEx attempts in the current project with the “Email” class; otherwise inconsistencies will arise again.
– A uniform code style has a positive effect on quality!
As in real life, if there is already rubbish somewhere, the inhibition threshold to dump rubbish there drops extremely. But if everything looks nice and tidy, then nobody just throws a “randumInt() { return 4; }” function on the floor.
It also helps to automate some refactoring because the code looks everywhere the same, you can also apply the same e.g. PHP-CS-Fixer and you do not need to think about every different coding style.
– Use functional principles & object-oriented concepts.
A pure function (“Pure Functions”) only depends on its parameters and with the same parameters it always returns the same result. These principles can also be considered in OOP and create so-called immutable classes (immutable class).
Global variables make testing difficult because they can cause side effects. Also, it’s difficult to refactor code with global variables because you don’t know what effects these changes will have on other parts of the system.
In some programming languages (e.g. JavaScript, Shell) all variables are global and only become local with a certain keyword (e.g. in the scope of a function or a class).
– Learn to use your tools properly!
For example, if you’re writing code with Notepad, you can dig a hole with a spoon, which is just as efficient. Learn keyboard shortcuts for your programs and operating system! Use an IDE, e.g. from JetBrains (https://www.jetbrains.com/products.html) and use additional plugins and settings.
Modern IDEs also give hints/suggestions on how to improve your code. For example, for PHP, you can use PhpStorm + PHPStan and share the global IDE Inspections settings in the team.
– Performance?
In nearly every situation you don’t have to worry too much about performance, as modern programming languages / frameworks support us and with common solutions; otherwise the motto is “profiling, profiling… profiling”!
– Exceptions === Exceptions
You should not use exceptions to handle normal errors. Exceptions are exceptions, and regular code handles the regular cases! “Use exceptions only in exceptional circumstances” (Pragmatic Programmers). And nearly under no circumstances you should “choke off” exceptions, e.g. by trivially catching several exceptions.
– Finish your work
You should finish what you started. For example, if you need to use “fopen()” you should also use “fclose()” in the same code block. So, nobody in the team needs to clean up your stuff after he / she uses your function.
– Source code should be searchable [Ctrl + F] …
The source code should be easy to search through, so you should avoid using string nesting + “&” with Sass, for example, and also avoid using PHP functions such as “extract()”. Whenever variables are not declared, but created as if by magic (e.g. using magic methods in PHP), it is no longer so easy to change the source text afterward.
A big problem in programming is that you have to try to think and program in a generalized way so that you can (easily) expand the source code if new requirements are added or you can (easily) change it.
What does project sometimes look like? → A customer orders 10,000 green apples from a farm, changes his order to 10,000 red apples the morning before delivery and when these are delivered, the customer would prefer 10,000 pears and would like to pay for them in 6 months.
And precisely for this reason you should only write the source code that is really required for the current use case because you can’t map all eventualities anyway and the source code is unnecessarily complicated.
– KISS – Keep it simple, stupid.
One should always keep in mind that the source code itself is not that valuable. The value only arises when other developers understand it and can adapt / configure / use it for the customer or themselves. This should be kept in mind during programming so that a solution can be implemented as comprehensibly and “simply” as possible. And if I don’t need to use a new class or nice design pattern for the current problem, I probably shouldn’t. However, this does not mean that you should throw all good intentions overboard and use global variables / singletons everywhere. However, if a simple solution already does the job, go for that one.
A good example of what not to do is the JavaScript DOM Selector API. Not exactly nice to read or write…
Repetitions / redundancies in the source text or in recurring work arise relatively quickly if people do not communicate with each other. But also unintentionally due to errors in the software design because you don’t have a better idea or don’t think you have time for it.
To avoid repetition, make your solution easy to find and easy to use. So that other devs will use it instead of re-creating a solution.
– The will to learn and understand something new is more important than previous knowledge.
If you can already program ActionScript (Flash), for example, but are not willing to learn something new, then previous knowledge is of no use because “The only constant in the universe is change.” – Heraclitus of Ephesus (about 540 – 480 BC).
– Follow other programmers on Twitter / GitHub / dev.to / YouTube / Medium / …
It sometimes helps to motivate yourself, to write e.g. a blog post or testing some new stuff, if you know some people how has the same interest, so just follow some of them online, there are many excellent developers out there, and they share their knowledge and tricks mostly for free. :)
– Listen to podcasts & subscribe to RSS feeds / newsletters & watch videos, for example from web conferences
To find out about new technologies, techniques, standards, patterns, etc., it is best to use different media, which can be consumed in different situations. An interesting podcast on “Frontend Architecture” before falling asleep or a video on “DevOps” while preparing lunch, reading a book on the tram in the morning entitled “Programming less badly” … to name just a few examples.
– Attend Meetup’s & web conferences and talk to other developers.
Meetups are groups of people who meet regularly and talk about things like Python, Scala, PHP, etc. Usually, someone gives a lecture on a previously agreed topic.
Web conferencing is fun. Point. And every developer / admin should visit them because you get new impressions and meet wonderful people. Some conferences are expensive, but here you should contact your employer, if necessary, the company will take care of it. And there are also really cheap conferences.
– Post answers at quora.com || stackoverflow.com || in forums || your blog…
To deal with a certain topic yourself and to really understand it, it is worth doing research and writing a text (possibly even a lecture) that others can read and criticize and thus improve.
– Don’t stay at work for so long every day; otherwise nobody will be waiting for you at home!
With all the enthusiasm for the “job” (even if it’s fun), you shouldn’t lose sight of the essential things. Again, something I had to learn the hard way. :-/
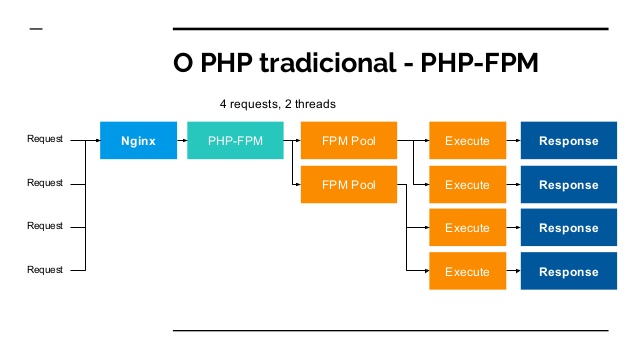
First there is an HTTP request and that will hit your Web server, then it will pass the request via TCP- or UNIT-Socket via FastCGI to your PHP-FPM Daemon, here we will start a new PHP process and in this process we will connect e.g. to the database and run some queries.
The Problem!
There are different timeout problems here because we connect different pieces together and this parts need to communicate. But what if one of the pieces does not respond in a given time or, even more bad, if one process is running forever like a bad SQL-query.
Understand your Timeouts.
Timeouts are a way to limit the time that a request can run, and otherwise an attacker could simply run a denial-of-service with a simple request. But there are many configurations in several layers: Web server, PHP, application, database, curl, …
– Web server
Mostly you will use Apache or Nginx as Web server and in the end it makes not really a difference, there are different timeout settings, but the idea is almost the same: The Web server will stop the execution and kills the PHP process, now you got a 504 HTTP error (Gateway Timeout) and you will lose your stack trace and error-tracking because we killed our application in the middle of nothing. So, we should keep the Web server running as long as needed.
Here you can see all configurations for Apache2 timeouts, but we only need to change etc/apache2/conf-enabled/timeout.conf`` because it will overwrite `/etc/apache2/apache2.conf` anyway.
PS: Remember to reload / restart your Web server after you change the configurations.
If we want to show the user at least a custom error page, we could add something like:
… into our Apache configuration or in a .htaccess file, so that we can still use PHP to show an error page, also if the requested PHP call was killed. The problem here is that we will lose the error message / stack trace / request etc. from the error, and we can’t send e.g. an error into our error logging system. (take a look at sentry, it’s really helpful)
– PHP-FPM
Our PHP-FPM (FastCGI Process Manager) pool can be configured with a timeout (request-terminate-timeout), but just like the Web server setting, this will kill the PHP worker in the middle of the process, and we can’t handle the error in PHP itself. There is also a setting (process_control_timeout) that tells the child processes to wait for this much time before executing the signal received from the parent process, but I am uncertain if this is somehow helpfully here? So, our error handling in PHP can’t catch / log / show the error, and we will get a 503 HTTP error (Service Unavailable) in case of a timeout.
Shutdown functions will not be executed if the process is killed with a SIGTERM or SIGKILL signal. :-/
PS: Remember to reload / restart your PHP-FPM Daemon after you change the configurations.
– PHP
The first idea from most of us would be maybe to limit the PHP execution time itself, and we are done, but that sounds easier than it is because `max_execution_time` ignores time spent on I/O (system commands e.g. `sleep()`, database queries (SELECT SLEEP(100)). But these are the bottlenecks of nearly all PHP applications, PHP itself is fast but the external called stuff isn’t.
Theset_time_limit()function and the configuration directive max_execution_time only affect the execution time of the script itself. Any time spent on activity that happens outside the execution of the script such as system calls using system(), stream operations, database queries, etc. is not included when determining the maximum time that the script has been running. This is not true on Windows where the measured time is real.
Many PHP applications spend most of their time waiting for some bad SQL queries, where the developer missed adding the correct indexes and because we learned that the PHP max execution time did not work for database queries, we need one more timeout setting here.
There is the MYSQLI_OPT_CONNECT_TIMEOUT and MYSQLI_OPT_READ_TIMEOUT (Command execution result timeout in seconds. Available as of PHP 7.2.0. – mysqli.options) setting, and we can use that to limit the time for our queries.
In the end you will see a “Errno: 2006 | Error: MySQL server has gone away” error in your PHP application, but this error can be caught / reported, and the SQL query can be fixed, otherwise the Apache or PHP-FPM would kill the process, and we do not see the error because our error handler can’t handle it anyway.
Summary:
It’s complicated. PHP is not designed for long execution and that is good as it is, but if you need to increase the timeout it will be more complicated than I first thought. You need for example different “timeout”-code for testing different settings:
We can combine different timeout, but the timeout from the called commands e.g. database, curl, etc. will be combined with the timeout from PHP (max_execution_time) itself. The timeout from the Web server (e.g. Apache2: Timeout) and from PHP-FPM (request_terminate_timeout) need to be longer than the combined timeout from the application so that we still can use our PHP error handler.
I think we are mostly lazy, and so we use names from underlying structures like APIs or the databases, instead of using names that describe the current situation.
For example, the method “Cart->getUser(): User“: There is a “user_id“ in the underlying database table, so the developer chooses the name “getUser()“ where the User will be returned. The problem is “getX“ and “setX“ are terrible names for methods because they did not say you anything about the context of these methods. Maybe something like “Cart->orderUser(): OrderUser“ and at some point “Cart->orderApprovalUser(): OrderApprovalUser“ are better names. But keep in mind that this depends on your use cases. And please rename also e.g. your “user_id“ in the cart database table, so that you keep the code consistent and readable.
In Eric Evans’ book Domain-Driven Design he introduces the concept of a “Ubiquitous Language“ — a shared, common vocabulary that the entire team shares when discussing or writing software. This “entire team” is made up of designers, developers, the product owner and any other domain experts that exist at the organization. And take the note that it is important that your team have a domain expert! Mostly we are not the expert in the field we are writing software for, so we need some professional input. If you build an invoice-system you will need an expert in finance-questions and -laws.
if ()
# BAD:
if ($userExists == 1) { }
# BETTER: use "==="
if ($userExists === 1) {}
# BETTER: use the correct type
if ($userExists === true) {}
# BETTER: use something readable
if ($this->userExists()) {}
# BAD:
$foo = 3;
if ($lall === 2) { $foo = 2; }
# BETTER: use if-else
if ($lall === 2) {
$foo = 2;
} else {
$foo = 3;
}
# BETTER: only for simple if-else
$foo = ($lall === 2) ? 2 : 3;
# BETTER: use something readable
$foo = $this->foo($lall);
# BAD
foreach ($cartArticles as $key => $value)
# BETTER: use correct names
foreach ($cartArticles as $cartIndex => $cartArticle)
# BETTER: move the loop into a method
cart->getArticles(): Generator<int, Article>
# BAD
foreach ($cartArticles as $cartArticle) {
if ($cartArticle->notActive) {
$this->removeArticle($cartArticle)
}
}
# BETTER: use continue
foreach ($cartArticles as $cartArticle) {
if (! $cartArticle->active) {
continue;
}
$this->remove_article($cartArticle)
}
# BETTER: use something readable
cart->removeNonActiveArticles(): int;
method ( )
# BAD
thisMethodNameIsTooLongOurEyesCanOnlyReadAboutFourCharsAtOnce(bool $pricePerCategory = false): float|float[]
# BETTER: use shorter names if possible (long names mostly indicates that the method does more than one thing)
cartNetPriceSum(bool $pricePerCategory = false): float|float[]
# BETTER: use less parameter and use one return type
cartNetPriceSum(): float
cartNetPriceSumPerCategory(): float[]
class ()
# BAD:
class \shop\InvoicePdfTemplate;
class \shop\InvoicePdfTemplateNew extends \shop\InvoicePdfTemplate;
class \shop\InvoicePdfTemplateSpecial extends \shop\InvoicePdfTemplateNew;
# BETTER: use non-generic class names for non-generic classes
class \shop\InvoicePdfTemplate;
class \shop\PdfTemplateCustomerX extends \shop\InvoicePdfTemplate;
class \shop\PdfTemplateActionEaster2020 extends \shop\PdfTemplateCustomerX;
# BETTER: do not use multi-inheritance, because of side-effects
class \shop\invoice\PdfTemplateGeneric
class \shop\invoice\PdfTemplate extends \shop\invoice\PdfTemplateGeneric;
class \shop\invoice\PdfTemplateCustomerX extends \shop\invoice\PdfTemplateGeneric;
class \shop\invoice\PdfTemplateActionEaster2020 extends \shop\invoice\PdfTemplateGeneric;
# BETTER: use composition via interfaces
interface \shop\invoice\PdfTemplateInterface;
class \shop\invoice\PdfTemplateGeneric implements \shop\invoice\PdfTemplateInterface;
class \shop\invoice\PdfTemplate extends \shop\invoice\PdfTemplateGeneric;
class \shop\invoice\PdfTemplateCustomerX extends \shop\invoice\PdfTemplateGeneric;
class \shop\invoice\PdfTemplateActionEaster2020 implements \shop\invoice\PdfTemplateInterface;
# BETTER: use abstract or final
interface \shop\invoice\PdfTemplateInterface;
abstract class \shop\invoice\PdfTemplateGeneric implements \shop\invoice\PdfTemplateInterface;
final class \shop\invoice\PdfTemplate extends \shop\invoice\PdfTemplateGeneric;
final class \shop\invoice\PdfTemplateCustomerX extends \shop\invoice\PdfTemplateGeneric;
final class \shop\invoice\PdfTemplateActionEaster2020 implements \shop\invoice\PdfTemplateInterface;
// BAD:
/**
* Set amount.
*
* @since 3.0.0
* @param float $amount Amount.
*/
public function set_amount( $amount ) {
$amount = wc_format_decimal( $amount );
if ( ! is_numeric( $amount ) ) {
$amount = 0;
}
if ( $amount < 0 ) {
$this->error( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
if ( 'percent' === $this->get_discount_type() && $amount > 100 ) {
$this->error( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
$this->set_prop( 'amount', $amount );
}
// BETTER: fix phpdocs
/**
* @param float|string $amount Expects either a float or a string with a decimal separator only (no thousands).
*
* @since 3.0.0
*/
public function set_amount( $amount ) {
$amount = wc_format_decimal( $amount );
if ( ! is_numeric( $amount ) ) {
$amount = 0;
}
if ( $amount < 0 ) {
$this->error( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
if ( 'percent' === $this->get_discount_type() && $amount > 100 ) {
$this->error( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
$this->set_prop( 'amount', $amount );
}
// BETTER: use php types (WARNING: this is a breaking change because we do not allow string as input anymore)
/**
* @since 3.0.0
*/
public function set_amount( float $amount ) {
if ( $amount < 0 ) {
throw new WC_Data_Exception( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
if (
$amount > 100
&&
'percent' === $this->get_discount_type()
) {
throw new WC_Data_Exception( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
$this->set_prop( 'amount', $amount );
}
// BETTER: merge the logic
/**
* @since 3.0.0
*/
public function set_amount( float $amount ) {
if (
$amount < 0
||
(
$amount > 100
&&
'percent' === $this->get_discount_type()
)
) {
throw new WC_Data_Exception( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
$this->set_prop( 'amount', $amount );
}
// BETTER: make the logic readable
/**
* @since 3.0.0
*/
public function set_amount( float $amount ) {
if (! is_valid_amount($amount)) {
throw new WC_Data_Exception( 'coupon_invalid_amount', __( 'Invalid discount amount', 'woocommerce' ) );
}
$this->set_prop( 'amount', $amount );
}
private function is_valid_amount( float $amount ): bool {
if ($amount < 0) {
return false;
}
if (
$amount > 100
&&
'percent' === $this->get_discount_type()
) {
return false;
}
return true;
}
Should we write code that everybody can read?
I don’t think that every non-programmer need to read the code, so we do not need to write the code this way. But we should remember that we could write our code, so that every non-programmer could read it.
Summary
There are only two hard things in Computer Science: cache invalidation and naming things.
― Phil Karlton
“Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. …[Therefore,] making it easy to read makes it easier to write.”
“White space is to be regarded as an active element, not a passive background.” – Jan Tschichold
At least since Apple is using massive white space for their product pages, every web-designer knows that the visitors prefer simple over the complex designs. And I think we can use some of this design principles to make our code more readable.
What is white space?
White space is created by pressing the Return key [\n|\r|\r\n], Spacebar key [ ], or the Tab key [\t]. White space is essentially any bit of space in your code that is not taken up by „physical“ characters.
[\n] = LF (Line Feed) → Used as a new line character in Unix/Mac OS X
[\r] = CR (Carriage Return) → Used as a new line character in Mac OS before X
[\r\n] = CR + LF → Used as a new line character in Windows
White space is critical for organizing our code, because we tend to find some relations between “things” to instinctively find a meaning in the composition. Whatever you see, your mind will filter, add and remove the given input and because of that we should prepare the input. So that we can easily consume the code.
Vertical Whitespace:
A single blank line.
Horizontal Whitespace:
Leading White Space (at the start of a line): Leading white space (i.e., indentation) is addressed elsewhere. (Indent with i.e. 4 spaces is a good default.)
Internal White Space (in the code itself): The code is more readable with some white space between the different operations in a single line.
Trailing White Space (at the end of a line): This kind of white spaces are unnecessary and can complicate diffs.
Horizontal alignment: Alignment can aid readability, but it creates problems for future maintenance, if you do not automate your code style.
“White space also makes content more readable. A study (Lin, 2004) found that good use of white space between paragraphs and in the left and right margins increases comprehension by almost 20%. Readers find it easier to focus on and process generously spaced content.” – [Lin, 2004] Evaluating older adults’ retention in hypertext perusal: impacts of presentation media as a function of text topology by Dyi-Yih Michael Lin in “Computers in Human Behavior”, Volume 20, Issue 4, July 2004, Pages 491-503
Where do we use white space?
We mostly add white space after a parameter, function, method, if-, else-, while-, and other calls so that it’s easier to identify where code that belongs together starts and ends.Unlike a book in which you read from top to bottom, we mostly jump into the code and only read parts of the code. It’s more like a newspaper where you read the headline (i.e. method name) and then jump to the next article (i.e. method).
Whitespace changes are tricky for “diff”
You can use something like “git diff -w” …
–ignore-space-at-eol: Ignore changes in whitespace at EOL.
-b, –ignore-space-change: Ignore changes in amount of whitespace. This ignores whitespace at line end, and considers all other sequences of one or more whitespace characters to be equivalent.
-w, –ignore-all-space: Ignore whitespace when comparing lines. This ignores differences even if one line has whitespace where the other line has none.
–ignore-blank-lines: Ignore changes whose lines are all blank.
… but the problems is still there, that white space changes hurts readability from default diffs in i.e. gitlab / github / etc. so that you should try to commit white space changes in a separated commit.
Be consistent!
The most important and the only things that everybody will agree on is: “Be consistent [and try to automate this process, please]!” For example, don’t mix tabs and spaces or playing different braces for the same type of code. If the team (or project) didn’t use any code style at all, then it’s quite simple, take an existing coding standard (try to follow the conventions already in place for a language, if there are any) where automation is already implemented for and stick to it in the first run.
Design principles for your code
Proximity: Things closer together will be seen as belonging together.
Code: Put code together that belongs together.
bad:
.example_1,.example_2{background:url(images/example.png) center center no-repeat,url(images/example-2.png) top left repeat,url(images/example-3.png) top right no-repeat;}
not that bad:
.example_1, .example_2 { background: url(images/example.png) center center no-repeat, url(images/example-2.png) top left repeat, url(images/example-3.png) top right no-repeat; }
I also like to have a single blank line before ‘break’, ‘continue’, ‘declare’, ‘return’, ‘throw’, ‘try’, so that you see that this is some kind of important code. But also the readability of simple “if”-statements can be improved.
bad:
if (($loggedInKunde->bestellungen_genehmigen || $loggedInKunde->manuelle_bestellgenehmigung) && ($wareneingang != 5)) {
Symmetry: Our mind tends to perceive objects by finding a starting point and it’s pleased when it can find uniformity structures. Sometimes our mind will see such structures also if they are not really there.
Code: Try to use uniformity code structures.
bad:
if (widget.IsRegular){service.Process(widget);} else {var result = widget.Calculation();widget.ApplyResult(result);service.ProcessSpecial(widget);}
not that bad:
if (widget.IsRegular){service.Process(widget);} else {service.ProcessSpecial(widget);}
Nachdem ich nun bereits seit einigen Jahren lerne zu deklarieren und zu programmieren, werde ich im folgenden beschreiben was ich bisher gelernt habe.
Kurz zu mir: Lars Moelleken |
> Assistent für Betriebsinformatik
> Fachinformatiker Systemintegration
> Informatik Studium (Abgebrochen)
> Fachinformatiker Anwendungsentwicklung
Was habe ich in meiner Ausbildung zum Fachinformatiker Systemintegration gelernt?
– Du lernst nur soviel, wie du lernen willst.
Im Gegensatz zur Schule / Fachhochschule konnte und musste ich mir vieles in der Ausbildung selber beibringen und erarbeiten. Und man erkennt schnell, dass man nur soviel lernt wie man möchte. Wenn man dies einmal verstanden hat, dann setzt man sich auch gerne hin und lernt z.B. Linux- / Shell-Befehle auswendig, besucht weitere Kurse (z.B. bei der VHS), geht zu Meetups oder Konferenzen. Krümmer dich um dein Können, denn wenn man etwas macht, sollte man es auch richtig machen.
“Eine Investition in Wissen bringt noch immer die besten Zinsen.” – Benjamin Franklin
– Keine Panik!
Was man ziemlich schnell als Sysadmin lernt ist „Ruhe bewahren“ and think first – then act. Überstürzter Aktionismus hilft nicht weiter und schadet meistens sogar. Bevor man handelt, sollte man zuvor selber einige Informationen einholen (Infos von Logfiles, Hardware Status, System Status, …) so dass man auch wirklich weiß was wie man den Fehler behene kann.
– Linux && Kommandozeile <3
Wer bisher noch nicht mit einem Unix Betriebssystem gearbeitet hat, weiß leider nicht was er verpasst. Wer aus welchen Gründen auch immer Windows nutzen möchten oder muss, kann trotzdem mit der Git-Bash [+ .dotfiles] einige Vorteile von Linux nutzen. Und seine eigene Komfortzone zu verlassen und neue Betriebssysteme auszuprobieren hilft dabei den Computer insgesamt besser zu verstehen. An dieser Stelle empfehle ich mal wieder “Arch Linux”.
Man sollte sich außerdem mit der Kommandozeile vertraut machen, wenn du deine Produktivität rapide steigern möchtest. Zum Beispiel sollte man folgende Befehle man genauer ansehen: find / grep / lsof / strace
– Lies in der offizielle Dokumentation (und erst dann bei “Stack Overflow”).
Ob Cisco oder Manpages man liest am besten die offizielle Dokumentation zu der Programm-Version / Hardware-Version welche man gerade einsetzt. Beim programmieren nutzt man jedoch häufig stackoverflow.com und findet schnell Antworteten und Code-Beispiele, aber das “Warum” und “Wie” kommt dabei meistens zu kurz. Wenn man als erstes in die Spezifikation / Dokumentation schaut löst man nicht nur dieses Problem, sondern man versteht ggf. das Problem und weiß auch wie man ähnliche Probleme lösen kann.
– Mach immer ein Backup (benutze nieeemals betrunken “sudo”).
Manche Sachen muss man auf die hart Tour lernen, apt-get install safe-rm zu installieren gehörte für mich anscheinend dazu!
“Der Mensch hat dreierlei Wege klug zu handeln; erstens durch Nachdenken, das ist der edelste; zweitens durch Nachahmen, das ist der leichteste; und drittens durch Erfahrung, das ist der bitterest.” – (Konfuzius)
– Sei ehrlich zu Kunden, Mitarbeitern und dir selbst.
Sei ehrlich zu Kunden, insbesondere wenn etwas schief geht. Wenn das Produkt (z.B. Server) vom Kunden ausfällt, dann biete Lösungsvorschläge an und keine Ausreden und löse das Problem nicht die Schuldfrage. Niemandem ist damit geholfen, wenn man mit dem Finger auf den Kollegen oder Kunden zeigt, dem Server nicht, dem Kunden nicht und letztlich einem selbst nicht.
– Stelle Fragen, wenn du etwas nicht verstanden hast.
Rede mit Kunden nicht über etwas was du nicht verstehst, etwas nicht zu wissen (insbesondere in der Ausbildung) ist nicht schlimm, aber dann frage einen Kollegen bevor du mit einem Kunden darüber sprichst!
– Denke über dein Tun nach (nicht nur auf der Arbeit).
Wenn man Dinge hinterfragt und über seine Arbeit und sein Tun nachdenkt, dann kann man sich persönlich weiterentwickeln. Hinterfrag kritische zum Beispiel ob man wirklich bei Amazon bestellen sollte oder sollte man das Buch lieber direkt beim Verlag bestellt? Welchen Vorteil hat der Autor davon und habe ich Nachteile? Sollten wir Nagios3 oder besser direkt Icinga einsetzen? Hinterfrage deine Arbeit und bewerte kritisch ob dies wirklich eine gute / sichere / zukunftsorientierte Lösung ist.
Falls man sich selber nicht sicher ist oder eine zu eingeschränkte Sichtweise hat (weil man z.B. nur diese eine Lösung kennt), dann sollte man sich neues Wissen aneignen, ggf. andere Lösungen oder „best practices“ recherchieren und mit anderen über die Thematik diskutieren.
– Google korrekt nutzen …
Wenn man ein Problem recherchiert, dann sucht man nach der Fehlermeldung in Anführungszeichen. Und wenn man keine Fehlermeldung hat sucht man zusätzlich nach der Versionsnummer oder / und einer entsprechenden Jahreszahl.
Was habe ich in meiner Ausbildung zum Fachinformatiker Anwendungsentwicklung gelernt?
– Du lernst niemals aus …
Wenn man anfängt sich mit der Web-Programmierung (HTML, CSS, JS, Node.js, PHP, …) zu beschäftigen, weiß man zunächst gar nicht wo man anfangen soll! Es gibt so vieles zu lernen und dieses Gefühl begleitet einen einige Zeit (Jahre), bis man wiederkehrende Konzepte erkennt. Der Vorteil in der Web-Programmierung ist jedoch, dass viele unterschiedliche Dinge gemeinsame APIs haben oder zumindest kombiniert werden können. Ich kann in PHP eine Klasse schreiben, welche mir Data-Attribute für mein HTML erstellt, welche ich wiederum mit JavaScript auslesen kann, um diese entsprechend über CSS-Klassen zu gestalten. Aber es bleibt dabei, man lernt niemals aus und genau das ist das Spannende an diesem Job!
– Programmiere jeden Tag. (aber setzte dir selber ein LIMIT 1, x)
Auch wenn der Chef heute nicht im Büro ist und man als Azubi gerade keine Aufgabe hat, dann programmiere, wenn du Zuhause auf der Couch sitzt (und keine neue Serie auf Netflix läuft), dann programmiere und wenn du Urlaub hast, hast du Urlaub!
Wenn man jeden Tag Software schreibt, möchte man die selbe Funktionalität (z.B. Datenbankverbindung, E-Mail senden oder Error-Logging …) nicht mehrfach für verschiedene Projekte programmieren (und eigentlich will man Standard-Funktionen gar nicht selber programmieren). Daher sollte jeder Programmierer in Modulen denken und eine Applikation in verschiedenen, am besten austauschbaren Teilen konzipieren. In vielen Fällen kann man das System dann auch besser erweitern, da es bereits eine Schnittstelle für Module gibt, welche man nutzen kann. Die Unabhängigkeit und Entkopplung von Programmteilen hat auch den Vorteil, dass Seiteneffekte von unterschiedlichen Stellen im Quelltext weiter vermieden werden. Außerdem sollte man die Kopplung von den entsprechenden Modulen minimieren, da man ansonsten nichts durch Modulen gewinnt.
Für fast alle Dinge in der Web-Entwicklung gibt es bereits Paket-Manager:
– Frontend (css, js): bower (npm)
– Backend (Node.js): npm
– Backend (php): composer
– Backend (ruby): gem
– Open Source <3
Wenn man bereits mit Modulen und Packages arbeitet, kann man diese auch gleich als Open Source Projekt veröffentlichen + Tests via Travis-CI + Code-Coverage anzeigen + zumindest einer kleinen Dokumentation und schon allein aus diesen Gründen lohnt sich die Veröffentlichung als Open Source. Auch die Code-Qualität steigt (nach meiner Erfahrung), da man den Quelltext der Öffentlichkeit freigibt und sich daher mehr oder weniger Bewusst auf die Code-Qualität achtet.
Der Moment, wenn man seinen ersten Pull-Request für seine Software erhält oder mit jemanden aus Israel, der Türkei und der USA zusammen programmiert, unbezahlbar.
– Git und Gut!
Ich weiß nicht wie Menschen ohne eine Versionskontrolle mit dem PC arbeiten können. Selbst bei privaten kleineren Projekten oder für Konfigurations-Dateien setze ich “git” ein. Es folgende einige Vorteile, aber die Liste kann man bestimmt noch um einige Punkte erweitern …
Vorteile:
– Änderungen können nachvollzogen werden (git log, git blame)
– Änderungen können rückgängig gemacht werden (git revert, git reset)
– Änderungen können von anderen Mitarbeitern gereviewed werden
– Mitarbeiter können gleichzeitig an einem Projekt arbeiten (git commit, git pull, git push)
– Entwicklungszweige (Forks) können gleichzeitig entwickelt werden (git checkout -b , git branches)
– Nutze “github.com” und lerne von den besten.
Github ist noch einmal was ganz anders als zum Beispiel ein privater (kostenloses / freies) „gitlab“-Server, da man sich indirekt darauf geeinigt hat, dass man die Plattform für Open Source Projekte verwendet, obwohl github selbst nicht Open Source ist. Man findet daher wirklich viele gute Entwickler und Projekte auf github.com und man kann bereits durch das lesen von Quelltext / Quelltextänderungen vieles lernen. Insbesondere weil man die Entwicklung der Projekte nachvollziehen und verfolgen kann: Wie strukturieren andere Ihren Code? Wie schreiben andere Ihre “commit”-messages? Wie viel Code sollte eine Methoden beinhalten? Wie viel Code sollte eine Klasse beinhalten? Welche Variablen-Namen sollte man besser vermeiden? …
Gerade wenn man Tests für seine eigenen Funktionen und Klassen schreibt, erwischt man sich dabei genau die Fällte zu testen, welche man bereits bedacht hat, daher sollte man die entsprechende Funktionalität mit unterschiedlichen (noch nicht bedachten) Daten testen. Außerdem ist es manchmal hilfreich den Quelltext absichtlich (temporär) zu sabotieren, so dass man seine Tests ebenfalls einmal testen kann. Hier einige Listen mit Eingaben welche man testen könnte: https://github.com/minimaxir/big-list-of-naughty-strings
Unit-Tests, Integrationstest und Frontend-Tests helfen nur, wenn diese auch ausgeführt werden, daher sollte man sich frühzeitig mit automatisierten Tests beschäftigen und diese bei Quelltextänderungen auch automatisch ausführen. Wo und wann diese Tests ausgeführt werden entscheidet gleichermaßen darüber, wie effektiv diese Tests letztendlich sind. Sobald man einige Tests geschrieben hat, versteht man auch warum man auf zusätzliche Parameter bei Methoden und Funktionen besser verzichten sollte, da die Anzahl der Tests exponentiell ansteigt.
Sobald man mit mehr als einem Entwickler an einem Projekte arbeitet, möchte man irgendeine Art von Deployment einsetzten, weil man seine Änderungen sonst gegenseitig überschreibt. Außerdem möchte man, dass der Quelltext aus dem Versionskontroll-System auf dem Server liegt, ansonsten kann man eine Applikation nicht warten bzw. erweitern!
– Konzepte zu verstehen ist wichtiger als dessen Implementierung.
Design-Patterns (Programmier-Konzepte) zu verstehen hilft einem nicht nur in der aktuellen Programmiersprache, sondern kann meistens auch auf andere Programmiersprachen angewendet werden.
Grundlegende Konzepte (Klassen, Objekte, OOP, Funktionen, ORM, MVC, DDD, Unit-Tests, Data-Binding, Hooks, Template-Engine, …) findet man in vielen Frameworks / Programmiersprechen und sobald man die Begriffe und Konzepte einmal verstanden hat, ist es gar nicht mehr so schwer neue / unterschiedliche Frameworks einzusetzen. Und man erkennt unterschiedliche stärken und schwächen von diesen Frameworks / Werkzeugen: „Wer als Werkzeug nur einen Hammer hat, sieht in jedem Problem einen Nagel.“
– Probleme lösen heißt auch Kunden verstehen.
Design-Patterns gehören zur Grundausstattung, aber man sollte sich auch immer wieder die Frage stellen: Welches Problem mit der gegebenen Lösung eigentlich gelöst werden soll? Ggf. findet man eine noch eleganterer / einfacherer Lösung. Und manchmal will der Kunde eigentlich auch was ganz anders, er weiß es nur noch nicht oder jemand hat den Kunden falsch verstanden.
– Probleme lösen heißt auch Prozesse verstehen.
Es ist aber ebenso wichtig zu verstehen warum ein bestimmtes Feature implementiert wird, da man ansonsten etwas programmiert was entweder gar nicht gebraucht bzw. genutzt wird. Man sollte daher die entsprechende Aufgabenstellung vor der Implementierung und noch vor der Planung im Gesamtkontext verstehen.
– Verteile auf mehreren Dateien.
Nutze eine Datei für eine Klasse, nutze eine Datei für CSS-Eigenschaften eines Modules oder einer speziellen Seite, nutze eine neue Datei für jeden neuen View. Den Quelltext auf verschiedene Dateien / Verzeichnisse aufzuteilen bietet viele Vorteile, so weiß der nächste Entwickler wo neuer Quelltext abgelegt werden soll und man findet sich schneller im Quelltext zurecht. So geben viele Frameworks bereits eine vordefinierte Verzeichnisstruktur für z.B. Model / View / Controller vor.
– Lesbarkeit geht vor!
Die Lesbarkeit von Quelltext sollte immer an erster Stelle stehen, da man selber oder Arbeitskollegen diesen Code in Zukunft warten bzw. erweitern müssen.
– Gute Namensgebung ist eine der schwierigsten Aufgaben in der Programmierung.
Es fängt beim Domainnamen / Projektnamen an, geht über Dateinamen zu Namen von Verzeichnissen, Klassennamen, Methodennamen, Variablennamen, CSS-Klassennamen. Mache dir immer bewusst, dass andere dies lesen werden und verstehen müssen. Daher sollte man auch auf unnötige Abkürzungen verzichten und schreiben, was man beschreiben möchte.
Wir wollen beschreiben was die Funktion macht und nicht wie diese implementiert ist.
Gute Kommentare erklären “Warum” und nicht “Was” gemacht wird und sollten dem Leser einem Mehrwert bieten, welcher nicht bereits im Quelltext (Stichwort: Namensgebung) beschrieben ist.
Beschreibungen für Methoden, Funktionen und Klassen (javadoc, phpdoc, …) sollte meiner Meinung nach immer hinterlegt werden, so dass man seine Dokumentation im Quelltext abbildet. Moderne IDEs können zudem prüfen, ob die Parameter und Rückgaben korrekt hinterlegt wurden.
// Prüfen ob der User bereits einloggt ist
if (isset($_SESSION['user_loggedin']) && $_SESSION['user_loggedin'] > 1) { ... }
etwas besserer Code:
// check if the user is already logged-in
if (session('user_loggedin') > 1) { ... }
besserer Code:
if ($user->isLoggedin === true) { ... }
… und noch ein Beispiel …
schlechter Code:
// regex: email
if (!preg_match('/^(.*<?)(.*)@(.*)(>?)$/', $email) { ... }
besserer Code:
define('EMAIL_REGEX_SIMPLE', '/^(.*<?)(.*)@(.*)(>?)$/');
if (!preg_match(EMAIL_REGEX_SIMPLE, $email) { ... }
– Konsistenz in einem Projekt, ist wichtiger als persönliche Präferenzen!
Nutze den bestehenden Code und nutze gegebene Funktionen. Wenn es Vorteile bringt, dann ändern / refactor den entsprechenden Code aber refactor dann alle Stellen im Projekt welche auf diese Weise implementiert sind.
Beispiel: Wenn man bisher ohne Template-System gearbeitet hat und aus „Gründen“ eines einsetzten möchte, dann nutze dies für alle Templates im Projekt und nicht nur für deinen aktuellen Use-Case, da ansonsten inkonsistenten im Projekt entstehen. Wenn man z.B. eine neue „Email→isValid()“ Methode, dann sollte man auch alle bisherigen RegEx-Versuche im aktuellen Projekt durch die „Email“-Klasse ersetzten, weil ansonsten wieder inkonsistenten entstehen.
– Ein einheitlicher Code-Style wirkt sich sehr positiv auf die Qualität aus!
Wie im echten Leben gilt auch hier, wenn irgendwo bereits Müll liegt, sinkt die Hemmschwelle seinen einen Müll dort abzuladen extrem an. Wenn aber alles schön ordentlich aussieht, wirft man nicht einfach eine “randumInt() { return 4; } “-Funktion hinzu.
Man sollte sich im Team einen Code-Style überlegen und diesen in neuen Projekten einsetzten. In bestehenden Projekten gibt wieder Konsistent geht vor.
Eine reine Funktion (“Pure Functions”) ist nur von ihren Parametern abhängig und mit den selben Parametern liefert diese immer das selbe Ergebnis. Diese Prinzipien kann man auch in OOP berücksichtigen und sogenannte Unveränderbare Klassen erstellen (immutable class).
Globale Variablen erschweren das Testen, da diese Seiteneffekte verursachen können. Außerdem kann man Quelltext mit globalen Variablen nur schwer refactoren, da man nicht weiß welche Effekte diese Änderungen auf andere Teile des Systems haben.
In einigen Programmiersprachen (z.B. JavaScript, Shell) sind alle Variablen global und werden erst durch eine bestimmtes Schlüsselwort lokal (z.B. im Scope einer Funktion oder einer Klasse).
Wenn man z.B. mit Notepad Quelltext schreibt kann man auch mit einem Löffel ein Loch graben, denn dies ist ähnlich effizient. Lerne Tastatur-Shortcuts für deine Programme und dein Betriebssystem! Nutze eine IDE z.B. von JetBrains (https://www.jetbrains.com/products.html) und nutze zusätzliche Plugins und Einstellungen.
Moderne IDEs geben auch Hinweise / Vorschläge, wie man seinen Code verbessern kann. Für PHP kann man z.B. PhpStorm + Php Inspections (EA Extended) einsetzten und die globalen IDE- Inspections-Einstellungen im Team teilen.
– Performance?
In vielen Situationen muss man sich um die Performance gar nicht so viele Gedanken machen, da uns dabei moderne Programmiersprachen / Frameworks unterstützen und mit einem gesunden Menschenverstand kann man bereits vieles abschätzen, ansonsten heißt die Devise „Profiling, Profiling… Profiling“!
– Exceptions === Ausnahmen
Man sollte Ausnahmebehandlungen niemals zur Behandlung normaler (d.h. häufig auftretender) Fehler einsetzen. Ausnahmen sind Ausnahmen und sollten aus Ausnahmen bleiben. Regulärer Code behandelt die regulären Fälle! „Verwenden Sie Ausnahmen nur ausnahmsweise“ (Pragmatische Programmierer). Und auf keinen Fall sollte man Ausnahmen “abwürgen”, z.B. durch triviale Abfangen mehreren Exceptions.
– Führe deine Arbeit zu Ende
Man sollte in einer Funktion zu Ende führen, was man begonnen hat. So sollte man z.B. „fopen()“ und „fclose()“ immer in einem Code-Block (Methode || Funktion) nutzen, weil man ansonsten darauf vertrauen müsste, dass jemand anders die entsprechende Ressourcen wieder frei gibt.
– Quelltext sollte durchsuchbar sein [Strg + F] …
Der Quelltext sollte einfach zu durchsuchen sein, daher sollte man z.B. auf String-Nesting + „&” bei Sass verzichten und auch bei PHP-Funktionen wie “extract()” vermeiden. Immer wenn Variablen nicht deklariert, sondern wie von Zauberhand (z.B.: bei PHP durch Magic-Methoden) erzeugt werden, kann man den Quelltext anschließend nicht mehr so einfach ändern.
Ein großes Problem in der Programmierung ist, dass man versuchen muss generalisiert zu denken und zu programmieren, so dass man den Quelltext entsprechende (einfach) erweitern kann, wenn neue Anforderungen hinzukommen bzw. auch (einfach) ändern kann.
Wie sehen IT-Projekte manchmal aus? → Ein Kunde bestellt bei einem Bauernhof 10.000 grüne Äpfel, ändert seine Bestellung am morgen vor der Lieferung auf 10.000 rote Äpfel und als diese geliefert werden möchte der Kunde aber doch lieber 10.000 Birnen und möchte diese gerne erst in 6 Monaten bezahlen.
Und gerade aus diesem Grund sollte man nur den Quelltext schreiben, der wirklich für den aktuellen Use-Case benötigt ist, denn alle Eventualitäten kann man sowieso nicht abbilden und der Quelltext wird unnötig verkompliziert.
– KISS – Keep it simple, stupid.
Man sollte immer beachten, dass der Quelltext selber gar nicht so viel Wert besitzt. Der Wert entsteht erst dadurch, dass andere Entwickler diesen verstehen und für den Kunden oder sich selbst anpassen / konfigurieren / nutzen können. Dies sollte man während der Programmierung im Hinterkopf behalten, so dass man eine Lösung möglichst nachvollziehbar und „einfach“ implementiert. Und wenn ich keine neue Klasse oder schönes Design-Pattern für das aktuelle Problem verwenden muss, sollte ich dies ggf. auch nicht tun. Was jedoch auch nicht heißt, dass man alle guten Absichten über Board werfen und überall global Variablen / Singletons einsetzten sollte. Wenn jedoch eine einfache Lösung die Aufgabe bereits erfüllt, entscheide dich für diese.
Ein gutes Beispiel wie man es nicht machen sollte, stellt die JavaScript Dom Selector API da. Nicht gerade schön zu lesen oder zu schreiben …
(Ich weiß welche Schreibweise ich bevorzugen würde!)
– DRY – Don’t Reapeat Yourself.
Wiederholungen / Redundanzen im Quelltext oder auch in wiederkehrenden Arbeiten, entsteht relativ schnell wenn die Leute z.B. nicht miteinander kommunizieren. Aber auch unbeabsichtigt durch Fehler im Software-Entwurf, weil man es gerade keine bessere Idee hat oder meint dafür keine Zeit zu haben.
Um Wiederholungen zu vermeiden, sollte man den Quelltext bzw. den Task so ablegen, dass dieser einfach zu finden und einfach wiederzuverwenden ist, denn wenn es nicht einfach zu verwenden ist, werden die Leute es nicht nutzen.
– Der Wille etwas neues zu lernen und zu verstehen ist wichtiger als Vorkenntnisse.
Wenn man bereits z.B. ActionScript (Flash) programmieren kann, aber nicht willens ist etwas neues zu lernen dann bringt einem das vorherige Wissen nichts, denn „Die einzige Konstante im Universum ist die Veränderung.“ – Heraklit von Ephesus (etwa 540 – 480 v. Chr.)
– Lese gute Bücher und Zeitschriften.
Habe mir letztes Jahr das Ziel gesetzt mehr Fachbücher zu lesen. Dafür habe ich mir folgendes auferlegt: bevor ich ein “normales” Buch lesen darf, muss ich ein Fachbuch lesen und anschließend darf ich erst ein normales lesen …
– Infos: höre Podcast & abonniere RSS-Feeds / Newsletter & schaue Videos z.B. von Web-Konferenzen
Um sich über neue Technologien, Techniken, Standards, Pattern etc. zu informieren nutzt man am besten verschiedene Medien, welche man in unterschiedlichen Situationen konsumieren kann. Ein interessanten Podcast zum Thema “Frontend Architektur” vor dem einschlafen oder ein Video zum Thema “DevOp” beim zubereiten vom Mittagessen, morgens in der Straßenbahn ein Buch lesen mit dem Titel “Weniger schlecht programmieren” … um nur ein paar Beispiele zu nennen.
– Besuche Meetup’s & Web-Konferenzen und rede mit anderen Entwicklern.
Meetup’s sind Gruppen von Leuten die sich regelmäßig treffen und über z.B. Python, Scala, PHP, etc. austauschen. Meistens hält jemand einen Vortrag zu einem vorher abgestimmten Thema.
Web-Konferenzen machen Spaß. Punkt. Und jeder Entwickler / Administrator sollte diese besuchen, da man neue Eindrücke gewinnt und wirklich gute Leute trifft. Einige Konferenzen sind wirklich teuer, aber hier sollte man sich an seinen Arbeitgeber wenden, ggf. wird dies von der Firma übernommen. Außerdem gibt es auch wirklich günstige Konferenzen.
– Schreibe Antworten bei quora.com || stackoverflow.com || in Foren || deinem Blog …
Um sich selber mit einer bestimmten Thematik auseinander zu setzten und
wirklich zu verstehen, lohnt es sich zu recherchieren und einen Text (ggf. sogar einen Vortrag) zu verfassen, welchen andere lesen und kritisieren und somit verbessern können.
– Bleib nicht jeden Tag so lange auf der Arbeit, ansonsten wartet Zuhause irgendwann keiner mehr auf dich!!!
Bei all der Begeisterung für den “Job” (auch wenn es Spaß macht) sollte man die wirklich wichtigen Dinge nicht aus den Augen verlieren. Wieder etwas was ich auf die hart Tour lernen musste. :/
Meine ersten Befehle habe ich auf einem C64 getippt und zumindest in meiner Erinnerung ($zeit == ‘Grundschule’) hat das riesig Spaß gemacht, aber mit programmieren hatte das noch nicht viel zu tun. In der Schule wurde dann irgendwann “Programmieren” unterrichtet, aber auch dies hatte mit richtiger Programmierung nicht so viel gemeinsam. Nach der Schule habe ich eine Ausbildung bei der Global Village GmbH als “Fachinformatiker Systemintegration” gemacht und mich mit Netzwerken, Monitoring, Linux-Servern, MySQL-Server u.s.w. beschäftigt. Anschließend angefangen Informatik zu Studieren, habe jedoch abgebrochen und eine zweite Ausbildung als “Fachinformatiker Anwendungsentwicklung” bei der menadwork GmbH abgeschlossen.
meine Programmiersprachen in zeitlicher Reihenfolge: VBA -> Shell -> PHP -> C -> Java -> PHP (OOP) -> JavaScript (+jQuery)
PS: Go wird wohl als nächstes folgen :)
Zurück zur eigentlichen Fragestellung und eine schon oft diskutierte Frage. Welche Programmiersprache sollte man lernen bzw. lehren. Bis vor einiger Zeit habe ich noch gedacht, dass der klassische Weg mit “C” als erstes zu beschreiten wäre. Da man hier wirklich versteht wie ein Array funktioniert und was ein Pointer ist. Aber um z.B. Schülern das programmieren beizubringen würde ich als erstes die Web-Programmierung empfehlen, da man hier schneller zu einem sichtbaren Ergebnis kommt und z.B. Schüler somit besser motivieren kann. Auch wenn “HTML” und “CSS” keine Programmiersprachen sind, würde ich trotzdem empfehlen damit zu beginnen und anschließend via “jQuery” die ersten Dinge wirklich zu programmieren. Auf diesem Weg kann man bereits früh auf gelerntes Wissen zurückgreifen (z.B. CSS-Selektoren für jQuery oder inline CSS via jQuery ins HTML schreiben, …). Anschließend könnte man zu JavaScript und zur ersten echten Programmiersprache wechseln.
Hier einige Beispiel für eine “Hello Word” Ausgabe, welche direkt im Browser laufen (sozusagen mit GUI). Wenn man eine Browser (GUI) Anwendung z.B. via “C” oder “Java” entwickeln möchte benötigt man bereits um einiges mehr Code und / oder muss auf komplizierte Bibliotheken zurückgreifen.
Es folgenden einige Beispiele “Hello world!”-Beispiele in verschiedenen Web-Sprachen. Hier gibt es noch mehr Beispiele in anderen Programmiersprachen.
In order to optimize the website and to continuously improve it, this site uses cookies. By continuing to use the website, you consent to the use of cookies.