After many years of using PHPStan, PHP-CS-Fixer, PHP_CodeSniffer, … I will give you one advice: add your own custom code to extend your Code-Quality-Tooling.
Nearly every project has custom code that procures the real value for the product / project, but this custom code itself is often not really improved by PHP-CS-Fixer, PHPStan, Psalm, and other tools. The tools do not know how this custom code is working so that we need to write some extensions for ourselves.
Example: At work, we have some Html-Form-Element (HFE) classes that used some properties from our Active Record classes, and back in the time we used strings to connect both classes. :-/
Hint: Strings are very flexible, but also awful to use programmatically in the future. I would recommend avoiding plain strings as much as possible.
1. Custom PHP-CS-Fixer
So, I wrote a quick script that will replace the strings with some metadata. The big advantage is that this custom PHP-CS-Fixer will also automatically fix code that will be created in the future, and you can apply / check this in the CI-pipline or e.g. in a pre-commit hook or directly in PhpStorm.
<?php
declare(strict_types=1);
use PhpCsFixer\Tokenizer\Analyzer\ArgumentsAnalyzer;
use PhpCsFixer\Tokenizer\Analyzer\FunctionsAnalyzer;
use PhpCsFixer\Tokenizer\Token;
use PhpCsFixer\Tokenizer\Tokens;
final class MeerxUseMetaFromActiveRowForHFECallsFixer extends AbstractMeerxFixerHelper
{
/**
* {@inheritdoc}
*/
public function getDocumentation(): string
{
return 'Use ActiveRow->m() for "HFE_"-calls, if it is possible.';
}
/**
* {@inheritdoc}
*/
public function getSampleCode(): string
{
return <<<'PHP'
<?php
$element = UserFactory::singleton()->fetchEmpty();
$foo = HFE_Date::Gen($element, 'created_date');
PHP;
}
public function isRisky(): bool
{
return true;
}
/**
* {@inheritdoc}
*/
public function isCandidate(Tokens $tokens): bool
{
return $tokens->isTokenKindFound(\T_STRING);
}
public function getPriority(): int {
// must be run after NoAliasFunctionsFixer
// must be run before MethodArgumentSpaceFixer
return -1;
}
protected function applyFix(SplFileInfo $file, Tokens $tokens): void
{
if (v_str_contains($file->getFilename(), 'HFE_')) {
return;
}
$functionsAnalyzer = new FunctionsAnalyzer();
// fix for "HFE_*::Gen()"
foreach ($tokens as $index => $token) {
$index = (int)$index;
// only for "Gen()"-calls
if (!$token->equals([\T_STRING, 'Gen'], false)) {
continue;
}
// only for "HFE_*"-classes
$object = (string)$tokens[$index - 2]->getContent();
if (!v_str_starts_with($object, 'HFE_')) {
continue;
}
if ($functionsAnalyzer->isGlobalFunctionCall($tokens, $index)) {
continue;
}
$argumentsIndices = $this->getArgumentIndices($tokens, $index);
if (\count($argumentsIndices) >= 2) {
[
$firstArgumentIndex,
$secondArgumentIndex
] = array_keys($argumentsIndices);
// If the second argument is not a string, we cannot make a swap.
if (!$tokens[$secondArgumentIndex]->isGivenKind(\T_CONSTANT_ENCAPSED_STRING)) {
continue;
}
$content = trim($tokens[$secondArgumentIndex]->getContent(), '\'"');
if (!$content) {
continue;
}
$newContent = $tokens[$firstArgumentIndex]->getContent() . '->m()->' . $content;
$tokens[$secondArgumentIndex] = new Token([\T_CONSTANT_ENCAPSED_STRING, $newContent]);
}
}
}
/**
* @param Token[]|Tokens $tokens <phpdoctor-ignore-this-line/>
* @param int $functionNameIndex
*
* @return array<int, int> In the format: startIndex => endIndex
*/
private function getArgumentIndices(Tokens $tokens, $functionNameIndex): array
{
$argumentsAnalyzer = new ArgumentsAnalyzer();
$openParenthesis = $tokens->getNextTokenOfKind($functionNameIndex, ['(']);
$closeParenthesis = $tokens->findBlockEnd(Tokens::BLOCK_TYPE_PARENTHESIS_BRACE, $openParenthesis);
// init
$indices = [];
foreach ($argumentsAnalyzer->getArguments($tokens, $openParenthesis, $closeParenthesis) as $startIndexCandidate => $endIndex) {
$indices[$tokens->getNextMeaningfulToken($startIndexCandidate - 1)] = $tokens->getPrevMeaningfulToken($endIndex + 1);
}
return $indices;
}
}
To use your custom fixes, you can register and enable them: https://cs.symfony.com/doc/custom_rules.html
Example-Result:
$fieldGroup->addElement(HFE_Customer::Gen($element, 'customer_id'));
// <- will be replaced with ->
$fieldGroup->addElement(HFE_Customer::Gen($element, $element->m()->customer_id));Hint: There are many examples for PHP_CodeSniffer and Fixer Rules on GitHub, you can often pick something that fits 50-70% for your use-case and then modify it for your needs.
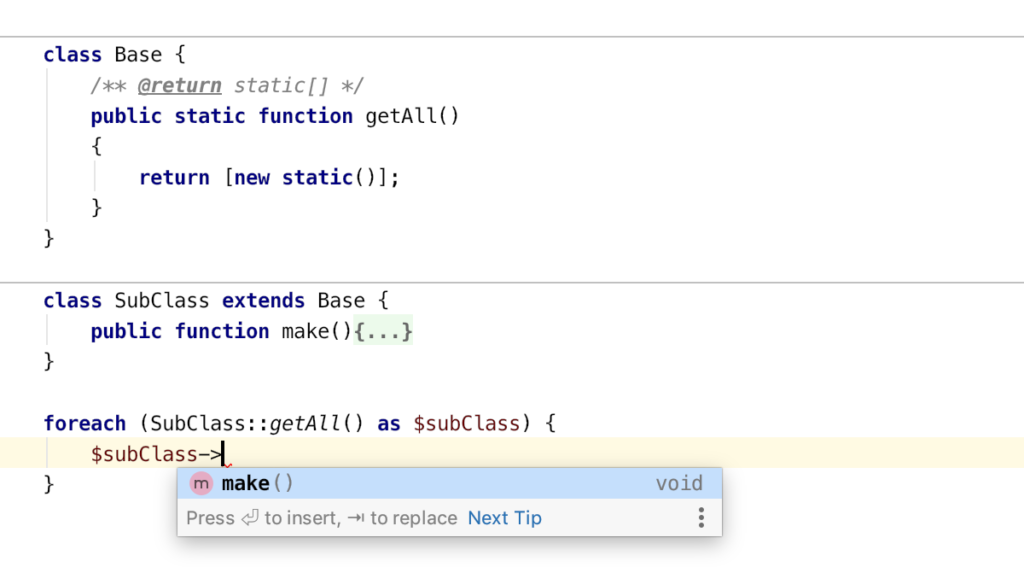
The “m()” method looks like this and will call the simple “ActiveRowMeta”-class. This class will return the property name itself instead of the real value.
/**
* (M)ETA
*
* @return ActiveRowMeta|mixed|static
* <p>
* We fake the return "static" here because we want auto-completion for the current properties in the IDE.
* <br><br>
* But here the properties contains only the name from the property itself.
* </p>
*
* @psalm-return object{string,string}
*/
final public function m()
{
return (new ActiveRowMeta())->create($this);
}
<?php
final class ActiveRowMeta
{
/**
* @return static
*/
public function create(ActiveRow $obj): self
{
/** @var static[] $STATIC_CACHE */
static $STATIC_CACHE = [];
// DEBUG
// var_dump($STATIC_CACHE);
$cacheKey = \get_class($obj);
if (!empty($STATIC_CACHE[$cacheKey])) {
return $STATIC_CACHE[$cacheKey];
}
foreach ($obj->getObjectVars() as $propertyName => $propertyValue) {
$this->{$propertyName} = $propertyName;
}
$STATIC_CACHE[$cacheKey] = $this;
return $this;
}
}
2. Custom PHPStan Extension
In the next step, I added a DynamicMethodReturnTypeExtension for PHPStan, so that the static code analyze knows the type of the metadata + I still have auto-completion in the IDE via phpdocs.
Note: Here I’ve also made the metadata read-only, so we can’t misuse the metadata.
<?php
declare(strict_types=1);
namespace meerx\App\scripts\githooks\StandardMeerx\PHPStanHelper;
use PhpParser\Node\Expr\MethodCall;
use PHPStan\Analyser\Scope;
use PHPStan\Reflection\MethodReflection;
use PHPStan\Type\Type;
final class MeerxMetaDynamicReturnTypeExtension implements \PHPStan\Type\DynamicMethodReturnTypeExtension
{
public function getClass(): string
{
return \ActiveRow::class;
}
public function isMethodSupported(MethodReflection $methodReflection): bool
{
return $methodReflection->getName() === 'm';
}
/**
* @var \PHPStan\Reflection\ReflectionProvider
*/
private $reflectionProvider;
public function __construct(\PHPStan\Reflection\ReflectionProvider $reflectionProvider)
{
$this->reflectionProvider = $reflectionProvider;
}
public function getTypeFromMethodCall(
MethodReflection $methodReflection,
MethodCall $methodCall,
Scope $scope
): Type
{
$exprType = $scope->getType($methodCall->var);
$staticClassName = $exprType->getReferencedClasses()[0];
$classReflection = $this->reflectionProvider->getClass($staticClassName);
return new MeerxMetaType($staticClassName, null, $classReflection);
}
}
<?php
declare(strict_types=1);
namespace meerx\App\scripts\githooks\StandardMeerx\PHPStanHelper;
use PHPStan\Reflection\ClassMemberAccessAnswerer;
use PHPStan\Type\ObjectType;
final class MeerxMetaType extends ObjectType
{
public function getProperty(string $propertyName, ClassMemberAccessAnswerer $scope): \PHPStan\Reflection\PropertyReflection
{
return new MeerxMetaProperty($this->getClassReflection());
}
}
<?php
declare(strict_types=1);
namespace meerx\App\scripts\githooks\StandardMeerx\PHPStanHelper;
use PHPStan\Reflection\ClassReflection;
use PHPStan\TrinaryLogic;
use PHPStan\Type\NeverType;
use PHPStan\Type\StringType;
final class MeerxMetaProperty implements \PHPStan\Reflection\PropertyReflection
{
private ClassReflection $classReflection;
public function __construct(ClassReflection $classReflection)
{
$this->classReflection = $classReflection;
}
public function getReadableType(): \PHPStan\Type\Type
{
return new StringType();
}
public function getWritableType(): \PHPStan\Type\Type
{
return new NeverType();
}
public function isWritable(): bool
{
return false;
}
public function getDeclaringClass(): \PHPStan\Reflection\ClassReflection
{
return $this->classReflection;
}
public function isStatic(): bool
{
return false;
}
public function isPrivate(): bool
{
return false;
}
public function isPublic(): bool
{
return true;
}
public function getDocComment(): ?string
{
return null;
}
public function canChangeTypeAfterAssignment(): bool
{
return false;
}
public function isReadable(): bool
{
return true;
}
public function isDeprecated(): \PHPStan\TrinaryLogic
{
return TrinaryLogic::createFromBoolean(false);
}
public function getDeprecatedDescription(): ?string
{
return null;
}
public function isInternal(): \PHPStan\TrinaryLogic
{
return TrinaryLogic::createFromBoolean(false);
}
}
Summary
Think about your custom code and how you can improve it, use your already used tools and extend it to understand your code. Sometimes it’s easy, and you can add some modern PHPDocs or you need to go down the rabbit hole and implement some custom stuff, but at last it will help your software, your team and your customers.










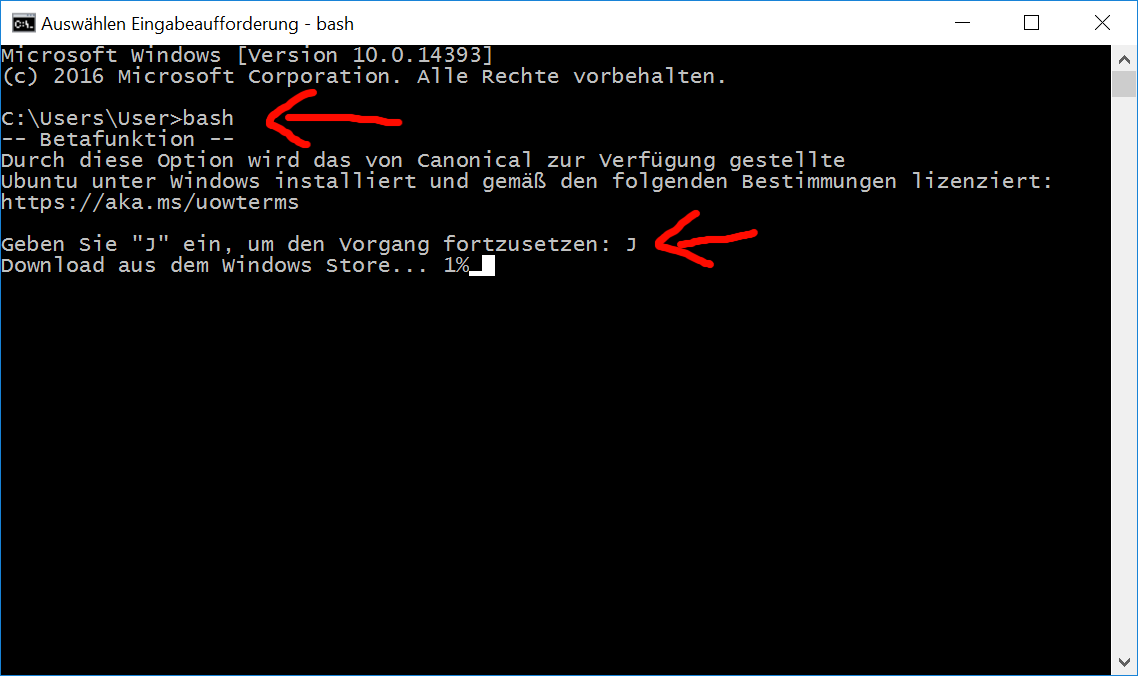
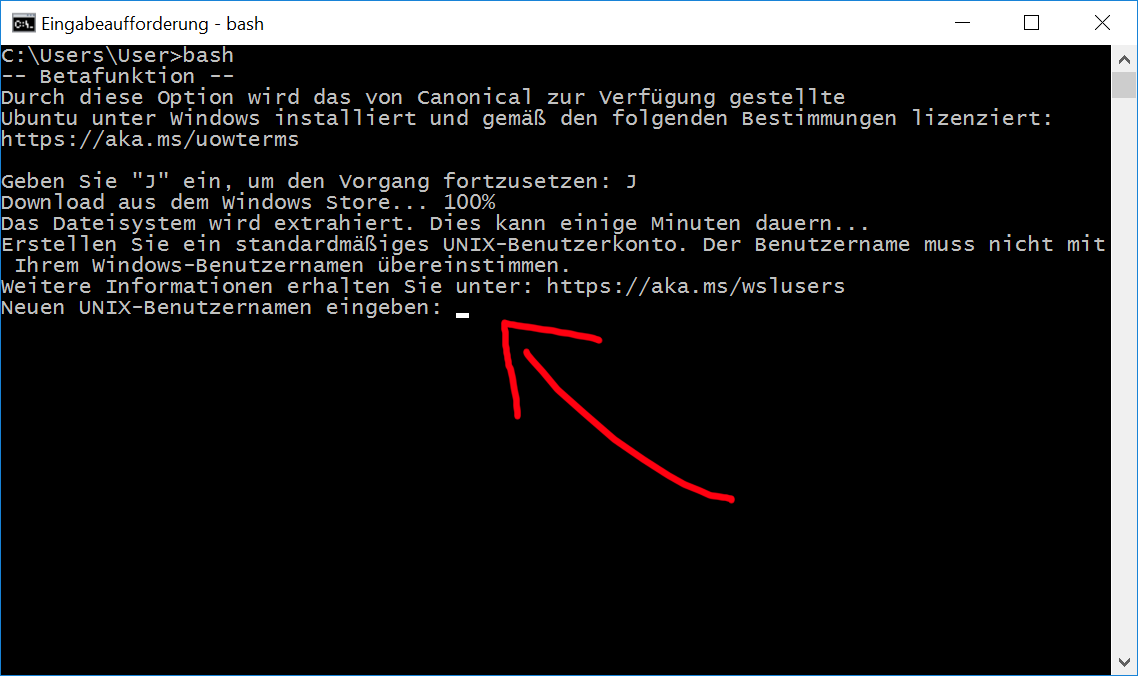
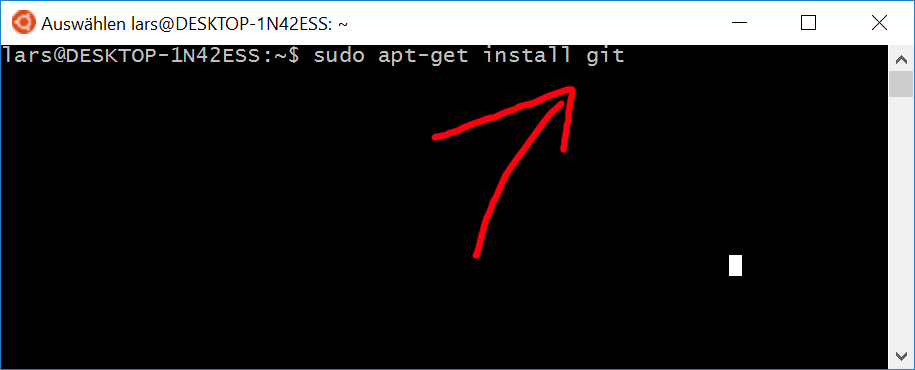

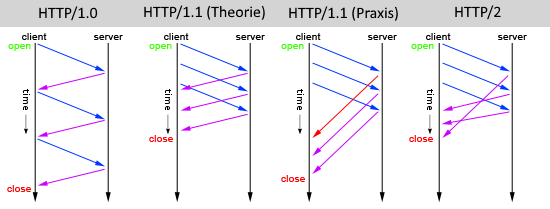
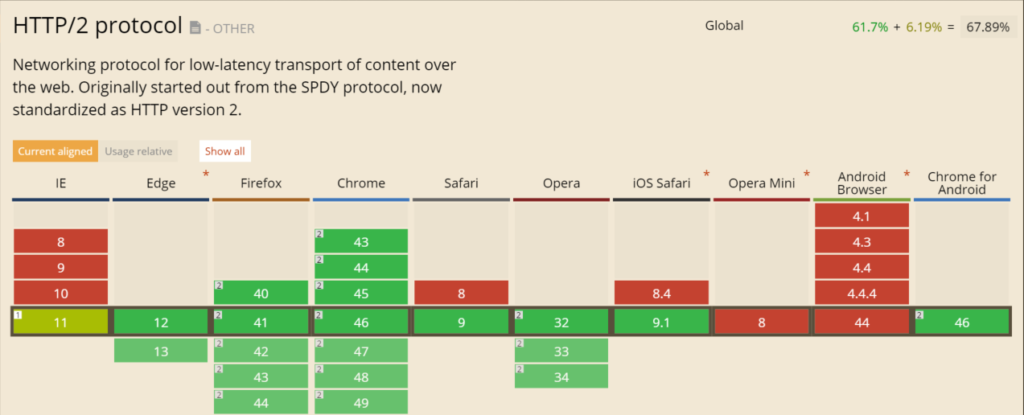
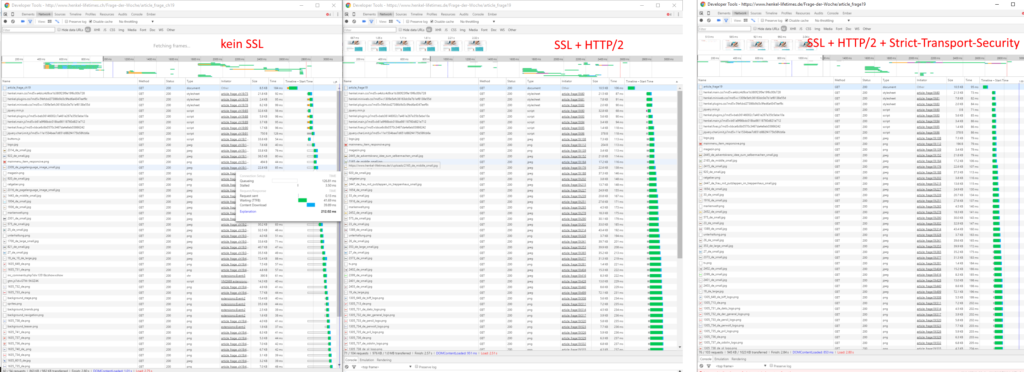
 ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.
ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.