SLIDES
- Was ist Open Source Software?
- Geschichte
- Freie Software ⊆ Open Source Software
- Lizenzen
- Geschäftsmodelle
- Wo veröffentliche ich Open Source Software?
- Welche Open Source Software Standards gibt es?
- Lizenz
- Quellcode-Organisatzion
- Dokumentation
- Kommunikation
- Versionsnummern
- Abhängigkeitsmanagement
- Testabdeckung
- Issue-Tracking-System
- Wie veröffentliche ich Open Source Software?
- Beispiel: npm
- Beispiel: bower
- Beispiel: composer
- Beispiel-Repository
1. Was ist Open Source Software?
Freiheit 0: Das Programm zu jedem Zweck auszuführen.
Freiheit 1: Das Programm zu untersuchen und zu verändern.
Freiheit 2: Das Programm zu verbreiten.
Freiheit 3: Das Programm zu verbessern und diese Verbesserungen zu verbreiten, um damit einen Nutzen für die Gemeinschaft zu erzeugen.
1.1 Geschichte
1893: AT&T wird gegründet
1911: IBM wird gegründet
1969: AT&T beginnt mit der Entwicklung eines quelloffenes Betriebssystem – Unix
1972: Dennis Ritchie veröffentlciht die Programmiersprache – C
1975: Microsoft wird von Bill Gates und Paul Allen gegründet
1976: Apple wird von Steve Jobs, Steve Wozniak und Ron Wayne gegründet
1977: Universität von Kalifornien in Berkeley entwickelt einen Fork von Unix – BSD
1980: Unix wird proprietär
1981: 86-DOS wird von Microsoft gekauft und an IBM verkauft ~ MS-DOS
1984: Richard Stallman beginnt mit der Entwicklung eines freien Betriebssystems – GNU
1985: Richard Stallman gründet eine gemeinnützliche Organisation – Free Software Foundation
1985: NeXT wird von Steve Jobs gegründet
1987: IBM und Microsoft veröffentlichen ein proprietäres Betriebssystem – OS/2
1987: Andrew S. Tanenbaum Minix veröffentlichen ein freies Betriebssystem – Minix
1988: MIT-Lizenz wird veröffentlicht
1988: NeXT, Inc. veröffentlicht ein proprietäres Betriebssystem, ein Fork von BSD – NeXTStep
1989: Richard Stallman schreibt eine Lizenz für Freie Software: GNU General Public License
1991: Linus Torvalds entwickelt einen freien Kernel – Linux
1993: Ian Murdock beginnt mit der Entwicklung eines freien Betriebssystems – Debian (GNU/Linux)
1993: Open-Source-Community veröffentlicht ein freies unixoides Betriebssystem – FreeBSD 1.0
1993: Microsoft veröffentlicht ein proprietäres Betriebssystem – Microsoft_Windows_3.1
1995: Rasmus Lerdorf entwickelt eine Skriptsprache für Webanwendungen – PHP
1995: Sun Microsystems entwickelt eine objektorientierte Programmiersprache – Java
1995: Netscape entwickelt eine Skriptsprache für Client-Webanwendungen – JavaScript
1996: erste Version des Betriebssystems Debian wird veröffentlicht – Debian 1.1 (GNU/Linux)
1998: Goolge wird von Larry Page und Sergey Brin gegründet – Google
1998: Organisation, zur Förderung von Open-Source-Software wird gegründet – OSI
2000: Apple veröffentlicht ein freies unixoides Betriebssystem, einen Fork von NeXTStep (FreeBSD) – Darwin
2001: Microsoft veröffentlicht ein proprietäres Betriebssystem – Microsoft Windows XP
2001: ein freies Onlinelexikon geht online – Wikipedia
2001: gemeinnützliche Organisation für freie Software (Europa) wird gegründet – FSFE
2001: gemeinnützliche Organisation für freie Lizenzen wird gegründente – Creative Commons
2002: freie Software wird im deutschen Urhebergesetz rechtskräftig – Linux-Klausel
2003: ein freie Software zur Verwaltung von Websiten wird veröffentlicht – WordPress
2005: Linux Torvalds beginnt mit der Entwicklung einer freien Versionsverwaltung – git
2008: Google Chrome (freeware) / Chromium (free) wird veröffentlicht – Chrom[e|ium]
2008: Google veröffentlicht ein freies Betriebssystem – Android
2009: Joyent Inc. entwickelt freie serverseitige Plattform für Netzwerkanwendungen – NodeJS
2012: Microsoft veröffentlicht ein proprietäres Betriebssystem – Microsoft Windows 8
2013: Mozilla veröffentlicht ein freies Betriebssystem – Firefox OS
2014: Open-Source-Community veröffentlicht ein freies unixoides Betriebssystem – FreeBSD 10.0
2015: Linus Torvalds veröffentlicht eine neue Version seines freien Kernels – Linux 4.0
…
Umsatz: Um zu verdeutlichen, wie viel Geld mit Software (Computer) verdient werden kann, auch mit Open Source Software …
Apple: 182,8 Mrd. USD (2014)
AT&T: 128,8 Mrd. USD (2013)
IBM: 92,8 Mrd. USD (2014)
Microsoft: 85,8 Mrd. USD (2014)
Google: 66 Mrd. USD (2014)
Red Hat: 1,33 Mrd. USD (2013)
Mozilla: 0,3 Mrd. USD (2013)
Canonical (Ubuntu): 0,065 Mrd. USD (2014)
1.2 Freie Software ⊆ Open Source Software
Man kann “Freie Software” als Teilmenge von “Open Source Software” verstehen, wobei der Begriff “Open Source” erst später eingeführt wurde, da man freie Software als geschäftsfreundlich und weniger ideologisch belastet darstellen wollte. Außerdem wollte man dem Begriffsproblem von „free software“ entgegenwirken, denn auch wenn viele freie Software kostenlos (free) ist, ist dies keine “freeware”.
Für die Definition von freier Software findet man folgenden Satz auf der GNU/GPL Webseite: To understand the concept, you should think of “free” as in “free speech,” not as in “free beer”.
Freie Software gewährt demnach dem Nutzer Freiheiten, was bei proprietärer Software nicht der Fall ist: z.B.:
https://govtrequests.facebook.com/: Hier kann man nachlesen, wie viele Anfragen die entsprechenden Regierungen an Facebook gestellt haben, um an unsere Informationen zu kommen oder uns bestimmte Informationen vorzuenthalten.
http://www.heise.de/newsticker/meldung/Amazon-loescht-gekaufte-Kindle-eBooks-6887.html: Hier hat Amazon Kindle-eBooks (“1984” und “Animal Farm” von George Orwell) von extern gelöscht, da der Verkäufer die nötigen Rechte zum verkaufen gar nicht besaß.
http://blogs.technet.com/b/mmpc/archive/2014/01/09/tackling-the-sefnit-botnet-tor-hazard.aspx: Hier wurde ebenfalls Software von extern gelöscht – Microsoft löscht Tor-Software nach Trojaner-Befall.
1.3 Lizenzen
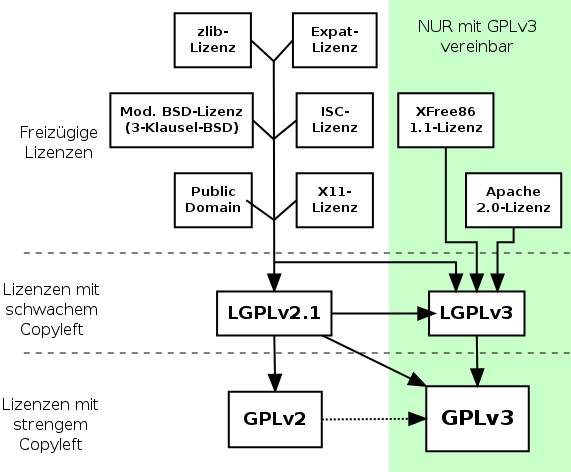
Es gibt es mittlerweile (zu) viele verschiedene Open Source Lizenzen und Lizenz-Versionen, welche teilweise nicht einmal miteinander kompatibel sind, so z.B. bei GPLv2 und GPLv3 welche man nicht gemeinsam in einem Programm nutzen darf: https://www.gnu.org/philosophy/license-list.html
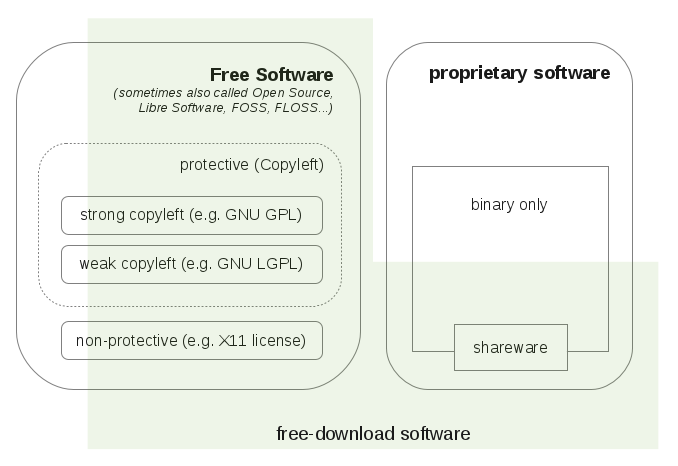
Allgemein kann man die verschiedenen Open Source Lizenzen jedoch in folgende Kategorien einteilen: Copyleft / Copyright

Copyleft ist eine Form von freier Software, bei der die Freiheit des Endanwenders hervorgehoben wird und die Freiheit der Programmierer hinten anstellt, so kann (darf) man z.B. “Google APIs Client Library for PHP” nicht für WordPress-Plugins verwenden, da diese Bibliothek nicht mit GPL kompatibel ist.

|
Art des Copyleft
|
Starkes Copyleft
|
Schwaches Copyleft
|
kein Copyleft
|
|
Kombinationsmöglichkeit
mit proprietärer Software
|
keine Einbindung in proprietären Code möglich
|
statisches und dynamisches Linken von Code mit proprietärer Software möglich. Eigen-Entwicklungen dürfen als proprietäre Software weitergegeben werden
|
darf auch in proprietäre Software verwendet werden
|
|
Beispiel-Lizenz
|
GPL
|
LGPL, MPL
|
BSD, Apache, MIT
|
1.4 Geschäftsmodelle
Beispiele:
– Adobe Systems veröffentlicht Flex (Apache License 2.0) und verkauft die Flash Builder IDE.
– Apple Inc. veröffentlicht Darwin (Apple Public Source License) und verkauft Mac OS X.
– Asterisk (PBX), verkauft Hardware auf welcher Open Source Software (GPL) läuft.
– Codeweavers verkauft CrossOver (proprietär + LGPL) und nutzt dafür als Grundlage Wine (LGPL)
– Canonical Ltd. bietet Ubuntu als Open Source an und bietet technischen Support gegen Zahlung an.
– Mozilla Foundation lässt sich von Google, Yahoo und anderen Unternehmen bezahlen, um z.B. die entsprechende Suchmaschine in Mozilla Firefox zu integrieren.
– Oracle bietet MySQL als Open Source Version (GPL) und als Enterprise Version (proprietär) mit Support und zusätzlichen Features an.
2. Wo veröffentliche ich Open Source Software?
Allein durch die Veröffentlichung von Quellcode entsteht zur noch keine Open Source Software, aber es bleibt die Grundvoraussetzung. Mittlerweile gibt es viele Plattformen, welche sich auf Quellcode-Repositories spezialisiert haben, dabei hat man sich inoffiziell bereits darauf geeinigt, dass “github.com” als Standard für Open Source Software angesehen wird. Sowohl npm, composer als auch bower nutzen github.com als Standard-Repository.
3. Welche Open Source Software Standards gibt es?
Unix ist der Ursprung von Open Source und die Unix-Philosophie von ~1970 lässt sich noch immer auf heutige Software Projekte anwenden: „Mache nur eine Sache und mache sie gut.“
– Schreibe Computerprogramme so, dass sie nur eine Aufgabe erledigen und diese gut machen. (Packages?)
– Schreibe Programme so, dass sie zusammenarbeiten. (REST?)
– Schreibe Programme so, dass sie Textströme verarbeiten, denn das ist eine universelle Schnittstelle. (JSON?)
Es gibt viele inoffizelle Standards bei Open Source Projekten, welche ggf. jedoch auch erst von der Community erstellt oder / und überhaupt erst im laufe des Projektes erstellt werden.
3.1 Open Source Lizenz für Software angeben (z.B.: LICENSE.txt)
– kann man verwenden: GPL, LGPL, MIT, BSD3
– sollte man ggf. vermeiden: Creative Commons, Beerware, WTFPL
– CLA (Contributor License Agreement) beachten: z.B.: Zend Framework 1
3.2 Quellcode Organisatzion (z.B. “src/”, “tests/”, “lib/”)
– Wie heißt das Verzeichnis für Tests?
– Wo findet man die Abhänigkeiten (vendor)?
– Wo findet man den Quellcode?
3.3 Dokumentation für Entwickler und Anwender
– Beschreibung, Code-Beispiele, Testabdeckung, Version, Lizenz, … (z.B.: README.md)
– Wie man mithelfen kann (z.B.: CONTRIBUTING.md)
– Anwender-Dokumentation (nicht im Code-Repository), z.B.:
– Beschreibung mit Beispielen / Bildern / Demos
– Wie man Bugs melden sollte (yourbugreportsucks.com / Beispiel)
– Entwickler-Dokumentation (nicht im Code-Repository), z.B.:
– Wie man den Quelltext herunterlädt
– Wie ist die Verzeichnis-Strucktur des Projektes
– Wie installiert man das Build-System / Wie nutzt man das Build-System
– Wie führt man die entsprechenden Tests aus
– Wie sieht der Code-Style aus (z.B.: google-styleguide)
3.4 Plattform für Fragen und Kommunikation, z.B.:
– Mailingliste / Forum
– Stack Overflow
– gitter.im
– groups.google.com
3.5 Versionsnummern korrekt verwenden
– Semantic Versioning via MAJOR.MINOR.PATCH
– MAJOR: Hauptversion, wenn die API geändert wird
– MINOR: neue Funktionen, welche keine API-Änderungen hervorrufen
– PATCH: bei abwärtskompatibelen Bugfixes
– Tag-Versionen in der Quellcodeverwaltung nutzen (z.B. git tag)
– ggf. einen Changelog schreiben (z.B.: CHANGELOG.md)
– Abhängigkeiten definieren (z.B.: package-versions with composer)
3.6 Abhängigkeitsmanagement für verwendete Bibliotheken nutzen, z.B.:
– PHP: Composer (packagist.org)
– JS / Node.JS: npm
– HTML / CSS / JS: bower
3.7 Testabdeckung und automatische Tests bei jeder Änderung
– Unit-Tests / BDD / TDD, z.B.:
– PHP: PHPUnit / phpspec
– JavaScript: mocha, Jasmine, qUnit …
– Frontend-Testing, z.B.:
– CasperJS / DalekJS / Selenium
– automatisierte Tests
– Travis CI (Linux)
– AppVeyor (Windows)
3.8 Issue-Tracking-System zur Verwaltung von Bugs verwenden
– z.B.: github – Issue-Tracking aktivieren
– Übersicht über Fehler und wer diese fixed
– “Gruppenzwang”, da das Issue-Tracking für jeden einsehbar ist
3.9 Contributor-Model bei größeren Projekten, z.B.: yui3
4. Wie veröffentliche ich Open Source Software?
4.2 Beispiel: npm
# Installation von node.js, z.B.:
sudo apt-get install nodejs
# Konfiguriere npm
npm set init.author.name "Lars Moelleken"
npm set init.author.email "lars@moelleken.org"
npm set init.author.url "http://moelleken.org"
# npm User erstellen (~/.npmrc)
npm adduser
# interaktiv eine “package.json”-Datei erstellen
npm init
# Abhänigkeiten & Tests hinzufügen
npm install mocha --save-dev
npm install chai --save-dev
# Veröffentliche dein Paket
npm publish
4.2 Beispiel: bower
# Installation von node.js, z.B.:
sudo apt-get install nodejs
# Installation von bower
npm install -g bower
# interaktiv eine “bower.json”-Datei erstellen
bower init
# Veröffentliche dein Paket
bower register <my-package-name> <git-endpoint>
4.3 Beispiel: composer
# Installation von composer, z.B.:
curl -sS https://getcomposer.org/installer | php
# interaktiv eine “composer.json”-Datei erstellen
composer init
# Veröffentliche dein Paket
https://packagist.org/packages/submit
5. Beispiel-Repositories
https://github.com/voku/node-lettering
https://github.com/voku/bower-lettering
Quellen / Links:
– eine Liste von offiziellen “Open Source” Lizenzen: http://opensource.org/licenses/alphabetical
– eine Liste von Programmiersprachen und deren Lizenzen: http://en.wikipedia.org/wiki/List_of_open-source_programming_languages
– Gespräch: Unterstützen von Open Source Projekten: https://www.radiotux.de/index.php?/archives/7995-RadioTux-Sendung-Maerz-2015.html
– Support for Open-Source Software: https://www.bountysource.com/
– Easy Pick (einfach zu behebende Bugs) -> z.B.: https://github.com/symfony/symfony/issues?q=is%3Aopen+is%3Aissue+label%3A%22Easy+Pick%22
– Help your favorite open source projects: http://www.codetriage.com/
– Statistik über freie Lizenzen auf github: http://ostatic.com/blog/the-top-licenses-on-github
– Erklärung zu freie Lizenzen: http://www.webmasterpro.de/management/article/freie-lizenzen.html
– A Beginner’s Guide to Creating a README: https://thechangelog.com/a-beginners-guide-to-creating-a-readme/
– Starting An Open-Source Project: http://www.smashingmagazine.com/2013/01/03/starting-an-open-source-project/
– qUnit vs Jasmine vs Mocha: http://www.techtalkdc.com/which-javascript-test-library-should-you-use-qunit-vs-jasmine-vs-mocha/
– Which programming language has the best package manager?http://blog.versioneye.com/2014/01/15/which-programming-language-has-the-best-package-manager/
– Erstelle Packages via bower: http://bower.io/docs/creating-packages/
– Open-Source-Lizenzen: http://www.heise.de/open/artikel/Open-Source-Lizenzen-224724.html
– Think about the license! http://lucumr.pocoo.org/2009/2/12/are-you-sure-you-want-to-use-gpl/
– Linus Torvalds says GPL v3 violates everything that GPLv2 stood for: https://www.youtube.com/watch?v=PaKIZ7gJlRU
– GNU – Free Software: https://www.gnu.org/philosophy/free-sw.en.html
– GNU/GPL: https://www.gnu.org/copyleft/gpl.html
– GNU/Packages: http://www.gnu.org/manual/blurbs
– FreeBSD über Vor- und Nachteile von GPL: https://www.freebsd.org/doc/en_US.ISO8859-1/articles/bsdl-gpl/gpl-advantages.html
– Geschäftsmodelle für Open-Source: http://t3n.de/magazin/geschaftsmodelle-open-source-unternehmer-welche-ansatze-221154/
– Open-Source-Finanzierung (Podcast): http://chaosradio.ccc.de/cr209.html
![[Update] Top Chrome Erweiterungen für Webdeveloper](https://suckup.de/wp-content/uploads//2010/11/google-chrome.jpg)