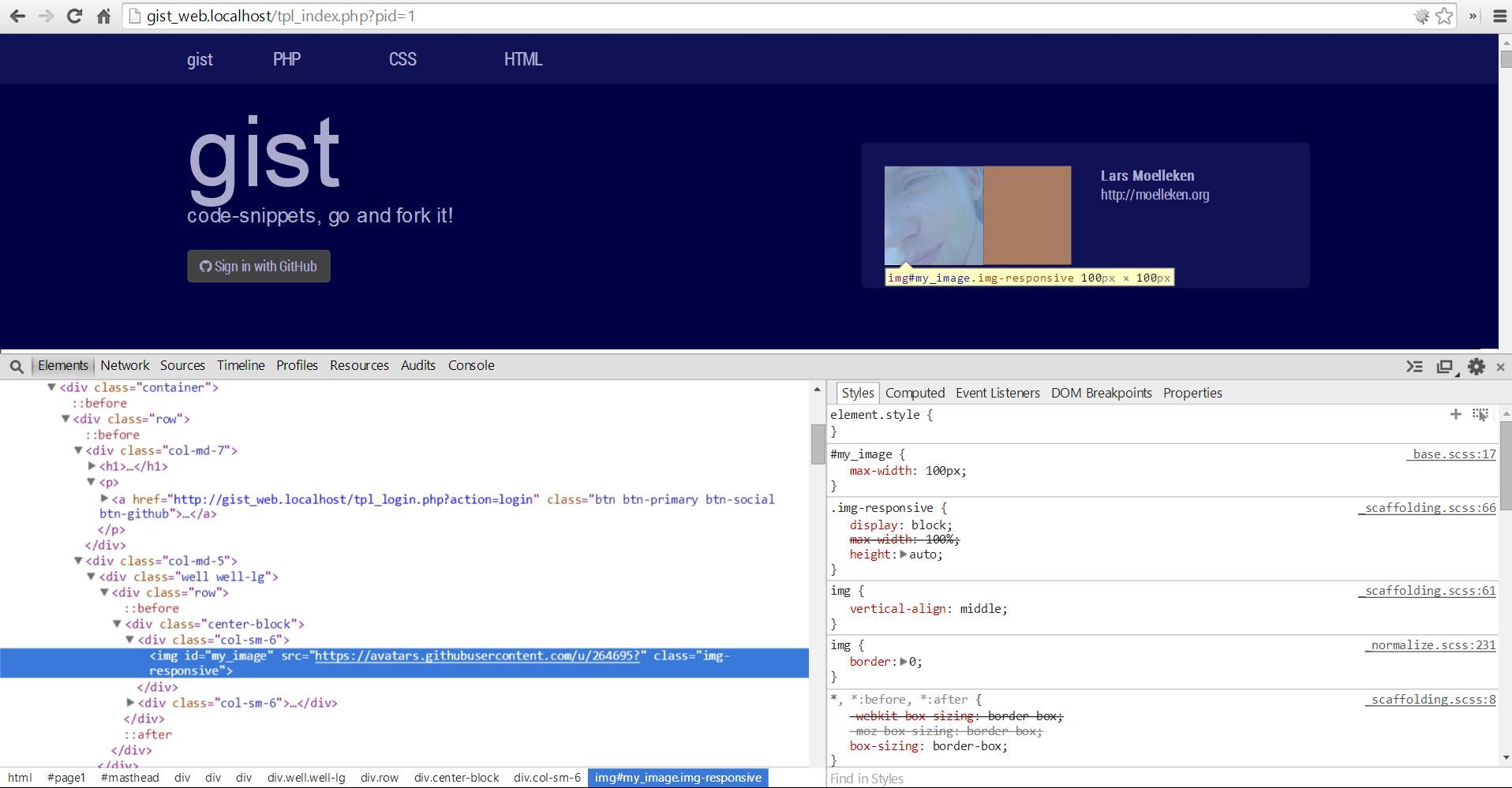
Neue Webseiten werden heutzutage oft via SASS erstellt, aber was macht man mit alten Projekten? Kann man auch hier SASS einsetzten? – Ja! Das schöne an “SCSS”-Dateien ist das diese 100% mit CSS kompatibel sind, so dass man die entsprechende Dateiendung umbenennen kann und neue / kleine Anpassungen in der SASS-Syntax schreiben kann. Wer jedoch eine ganze CSS-Datei auf den SCSS-Style anpassen möchte kann z.B. den “sass-convert”-Befehl auf der Kommandozeile verwenden.
See the Pen tqJvn by Lars Moelleken (@voku) on CodePen.
CSS > SCSS
Mit dem folgendem Befehl kann man die CSS-Datei in eine SCSS-Datei umwandeln lassen.
See the Pen Arxuv by Lars Moelleken (@voku) on CodePen.
Es folgt eine kleine manuelle Optimierung, dabei gilt: Umso besser die ursprüngliche CSS-Datei aufgebaut war, desto besser kann diese konvertiert werden.
See the Pen eFdlJ by Lars Moelleken (@voku) on CodePen.
SCSS > CSS
Nun erstellen wir aus der neuen SCSS-Datei wieder eine CSS-Datei + Sourcemap
An dieser Stelle wollte ich einmal notieren wie ich in der täglichen Arbeit mit z.B. “grep” oder “find” etc. umgehe, um möglichst schnell in Verzeichnissen und Dateien zu suchen oder Text zu ersetzten.
Ich werde hier nicht alle Möglichkeiten der entsprechenden Befehle nennen können, daher beschränke ich mich auf das, was ich wirklich verwende. Falls du dich weiter in der Thematik einlesen möchtest, empfehle ich gerne den “man”-Befehl oder wie andere es ausdrücken RTFM!
Falls dir die Begriffe tail, cat, less nicht viel sagen, dann klick hier!!!
grep:
global regular expression print -> durchsucht Dateien und Verzeichnisse via RegEx bzw. nach Strings
Kurzform
Langform
Beschreibung
-H
--with-filename
gibt den Dateinamen vor jedem Treffer aus.
-i
--ignore-case
unterscheide nicht zwischen Groß- und Kleinschreibung.
-n
--line-number
gibt die Zeilennummer vor jedem Treffer aus.
-R
-r
--recursive
liest alle Dateien unter jedem Verzeichnis rekursiv.
-v
--invert-match
Invertiert die Suche und liefert alle Zeilen die nicht auf das gesuchte Muster passen.
z.B.:
grep -rHn test ~/php/
-> sucht im Verzeichnis “php”, welches sich wiederum im Home-Verzeichnis [~] befindet nach dem String “test”
PS: hier der selbe Befehl, jedoch eingeschränkt auf php-Dateien
grep -Hn test ~/php/**/*.php
Info: wenn man “git” im Einsatz hat, sollte man “git grep” verwenden ;)
ack:
Ack hat die selbe Aufgabe wie “grep” ist jedoch auf Entwickler zugeschnitten, so sucht “ack” im Standardmäßig rekursiv, ignoriert Binärdaten und Verzeichnisse von Versionkontrollsystemen (.svn, .git, etc.)
PS: unter Debian / Ubuntu findet man das entsprechende Paket unter “ack-grep”
find:
ist bei der Suche nach Dateien behilflich (“Alles ist eine Datei”)
Suchkriterien für find
Kriterium
Beschreibung
-name Datei
Es wird nach Dateien mit dem Namen “Datei” gesucht. Sollen bei der Suche Platzhalter Verwendung finden, so muss der ganze Ausdruck in Anführungszeichen gestellt werden, zum Beispiel
-name "*.txt"
-iname Datei
Es wird nach Dateien mit dem Namen “Datei” – ohne Beachtung der Groß und Kleinschreibung – gesucht.
-type f
Es wird nur nach regulären Dateien gesucht.
-type d
Es wird nur nach Verzeichnissen gesucht.
find -size +10M -20M -exec ls -lah {} \;
-> sucht alle Dateien welche eine Dateigröße zwischen 10 – 20 MB haben und zeigt diese an
WARNING: der “exec”-Parameter kann auch für jeden anderen Befehl auf die Ergebnismenge von “find” ausführen, dabei sollte man jedoch bei dem “rm”-Befehl besonders vorsichtig sein. Und ggf. kann man sich safe-rm anschauen. ;)
“sudo updatedb” nicht vergessen und schon kann man sehr schnell nach Dateien suchen, da die Dateien nicht im Filesystem, sondern in einer Datenbank (updatedb) gesucht werden.
z.B.:
locate Download | grep home
sed:
Es handelt sich hier um einen “nicht-interaktiver Texteditor” was eigentlich nur bedeutet, dass man damit String verarbeite kann. Zum Bespiel kann man ein bestimmtes Wort in einer Datei durch ein anderes ersetzten.
# WARNING -> replace: changes multiple files at once
replace()
{
if [ $3 ]; then
find $1 -type f -exec sed -i 's/$2/$3/g' {} \;
else
echo "Missing argument"
fi
}
replace *.php alt neu
-> dieser Befehl such im aktuellen (+ Unterverzeichnisse) nach Dateien, welche auf “.php” enden und ersetzt darin “alt” gegen “neu”
Dabei ist besonders praktisch, dass man diese Funktionalität auch im “vim” verwenden kann indem man z.B. folgendes eingibt …
:%s/alt/neu/g
diff:
Wie der Name schon vermuten lässt, kann man hiermit Dateien vergleichen. z.B.:
diff -u --ignore-all-space -r old/ new/
-> vergleicht alle Dateien rekursiv (-r) vom Verzeichnis “old/” und “new/” und ignoriert dabei Änderungen vom Leerräumen z.B. Leerzeichen oder Zeilenumbrüche (\r <-> \r\n)
Info: wenn man “git” im Einsatz hat, sollte man “git diff” verwenden ;)
wc:
word count kann Wörtern, Zeichen und Bytes (man ahnt es bereits) zählen. z.B.:
Habe soeben einen älteren Blog-Post aktualisiert und einen kleinen Tipp hinzugefügt, welchen ich hier an zwei Beispielen zeigen möchte: suckup.de/linux/ubuntu/aptitude-dpkg/
sudo aptitude search "^php5-[a-cA-C]+"
-> sucht alle Pakete welche mit “php5-” anfangen und darauf “a”, “b oder “c” in beliebiger Häufigkeit folgen
sudo aptitude search "(^bash|^git).*completion"
-> sucht Pakete welche entweder mit “bash” oder mit “git” anfangen gefolgt von beliebigen (auch beliebige Anzahl) von Zeichen, gefolgt von dem String “completion”
Die RegEx-Funktionalität funktioniert sowohl bei “apt-cache”, “apt-get” als auch bei “aptitude” und auch bei anderen Befehlen wie z.B.: “remove”, “install”, “search”, “purge” etc. Bei meinen Tests hat dies jedoch mit “aptitude” am besten funktioniert, da hier nur nach den Paketnamen gesucht wird, falls man jedoch nicht genau weiß wonach man eigentlich sucht, dann sollte man es wohl mit “apt-cache” versuchen.
PS: wer sich RegEx noch nicht angeschaut hat, der sollte auch mal die Links in den Quellen anklicken, da man dies z.B. in so gut wie jeder Programmiersprache, in der Shell oder ansatzweise selbst bei der Google-Suche nutzen kann. Wer mehr über Tricks in der Google-Suche erfahren möchte, klickt hier! ;)
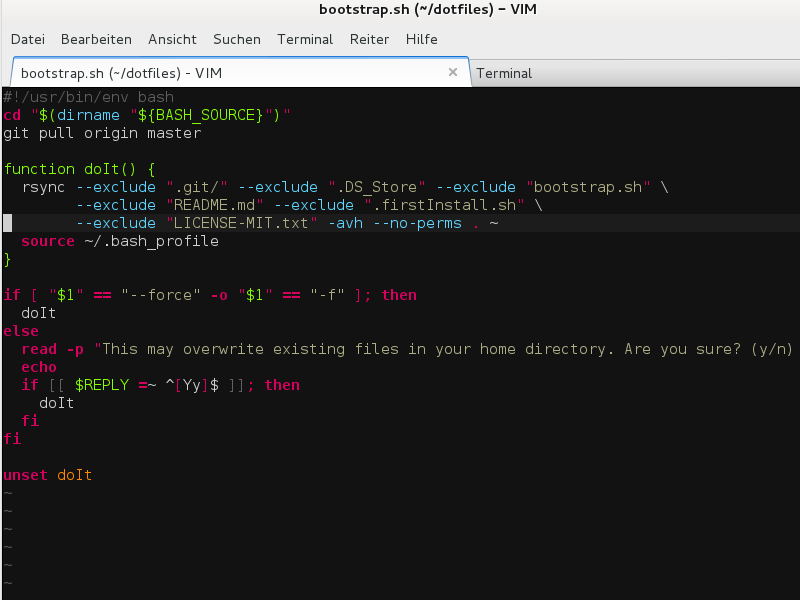
Habe meine dotfiles (Dateien im Home-Verzeichnis, welche mit einem “.” beginnen) mit anderen Quellen angereichert und diese auf github veröffentlicht. Wer möchte kann diese Einstellungen, Aliase, Funktionen für die “Linux-Shell” verwenden oder auch verbessern, indem man einen entsprechenden Fork von dem Projekt erstellt.
cd ~ && git clone https://github.com/voku/dotfiles.git && cd dotfiles && ./bootstrap.sh
… wenn gewünscht kann man mit diesem kleinen Skript entsprechende ggf. benötigte Pakete nachinstallieren:
./firstInstall.sh
Update:
./bootstrap.sh
Einstellungen:
Die Datei “~/.config_dotfiles” beinhaltet einige Einstellungen für die entsprechenden dotfiles. Wenn diese Datei nicht existiert wird diese automatisch beim ausführen der “bootstrap.sh”-Datei erzeugt.
Die Plugins sind von “bash-it“, “oh-my-zsh” und eigenen eigenen Anpassungen zusammengefügt. Außerdem wurden Plugins welche allgemeingültig sind in die globalen “.aliases” und “.functions” ausgelagert.
Wenn die Datei “~/.extra” existiert, wird diese zusammen mit den anderen Dateien verarbeitet. Man kann diese nutzen, um benutzerdefinierte Befehle ausführen zu lassen.
International PHP Conference: Thorsten Rinne (@ThorstenRinne) zeigt die Möglichkeiten von Tools wie Bower, Grunt und Yeoman, mit denen man den kompletten Entwicklungsworkflow im Frontend-Bereich abdecken kann. (auf deutsch)
CSS-Tricks Screencast #124: A Modern Web Designer’s Workflow
Fluent 2012: Paul Irish (@paul_irish) Learn what a modern development workflow looks like, from editors and plugins, to authoring abstractions, testing and DVCS integration.
Paul Irish on Web Application Development Workflow
HTML5DevConf: Paul Irish (@paul_irish) Iterating faster, avoiding bugs through tools, and improved automated testing are great ideas, but in this talk Google’s Paul Irish will show how to really incorporate them into a functional and realistic developer workflow.
… und zum Schluss noch ein Beispiel, wie man mit “Yeoman” & “Grunt” & “Bower” & “AngularJS” eine modere Web-App baut: http://yeoman.io/codelab.html
OS error code 1: Operation not permitted
OS error code 2: No such file or directory
OS error code 3: No such process
OS error code 4: Interrupted system call
OS error code 5: Input/output error
OS error code 6: No such device or address
OS error code 7: Argument list too long
OS error code 8: Exec format error
OS error code 9: Bad file descriptor
OS error code 10: No child processes
OS error code 11: Resource temporarily unavailable
OS error code 12: Cannot allocate memory
OS error code 13: Permission denied
OS error code 14: Bad address
OS error code 15: Block device required
OS error code 16: Device or resource busy
OS error code 17: File exists
OS error code 18: Invalid cross-device link
OS error code 19: No such device
OS error code 20: Not a directory
OS error code 21: Is a directory
OS error code 22: Invalid argument
OS error code 23: Too many open files in system
OS error code 24: Too many open files
OS error code 25: Inappropriate ioctl for device
OS error code 26: Text file busy
OS error code 27: File too large
OS error code 28: No space left on device
OS error code 29: Illegal seek
OS error code 30: Read-only file system
OS error code 31: Too many links
OS error code 32: Broken pipe
OS error code 33: Numerical argument out of domain
OS error code 34: Numerical result out of range
OS error code 35: Resource deadlock avoided
OS error code 36: File name too long
OS error code 37: No locks available
OS error code 38: Function not implemented
OS error code 39: Directory not empty
OS error code 40: Too many levels of symbolic links
OS error code 42: No message of desired type
OS error code 43: Identifier removed
OS error code 44: Channel number out of range
OS error code 45: Level 2 not synchronized
OS error code 46: Level 3 halted
OS error code 47: Level 3 reset
OS error code 48: Link number out of range
OS error code 49: Protocol driver not attached
OS error code 50: No CSI structure available
OS error code 51: Level 2 halted
OS error code 52: Invalid exchange
OS error code 53: Invalid request descriptor
OS error code 54: Exchange full
OS error code 55: No anode
OS error code 56: Invalid request code
OS error code 57: Invalid slot
OS error code 59: Bad font file format
OS error code 60: Device not a stream
OS error code 61: No data available
OS error code 62: Timer expired
OS error code 63: Out of streams resources
OS error code 64: Machine is not on the network
OS error code 65: Package not installed
OS error code 66: Object is remote
OS error code 67: Link has been severed
OS error code 68: Advertise error
OS error code 69: Srmount error
OS error code 70: Communication error on send
OS error code 71: Protocol error
OS error code 72: Multihop attempted
OS error code 73: RFS specific error
OS error code 74: Bad message
OS error code 75: Value too large for defined data type
OS error code 76: Name not unique on network
OS error code 77: File descriptor in bad state
OS error code 78: Remote address changed
OS error code 79: Can not access a needed shared library
OS error code 80: Accessing a corrupted shared library
OS error code 81: .lib section in a.out corrupted
OS error code 82: Attempting to link in too many shared libraries
OS error code 83: Cannot exec a shared library directly
OS error code 84: Invalid or incomplete multibyte or wide character
OS error code 85: Interrupted system call should be restarted
OS error code 86: Streams pipe error
OS error code 87: Too many users
OS error code 88: Socket operation on non-socket
OS error code 89: Destination address required
OS error code 90: Message too long
OS error code 91: Protocol wrong type for socket
OS error code 92: Protocol not available
OS error code 93: Protocol not supported
OS error code 94: Socket type not supported
OS error code 95: Operation not supported
OS error code 96: Protocol family not supported
OS error code 97: Address family not supported by protocol
OS error code 98: Address already in use
OS error code 99: Cannot assign requested address
OS error code 100: Network is down
OS error code 101: Network is unreachable
OS error code 102: Network dropped connection on reset
OS error code 103: Software caused connection abort
OS error code 104: Connection reset by peer
OS error code 105: No buffer space available
OS error code 106: Transport endpoint is already connected
OS error code 107: Transport endpoint is not connected
OS error code 108: Cannot send after transport endpoint shutdown
OS error code 109: Too many references: cannot splice
OS error code 110: Connection timed out
OS error code 111: Connection refused
OS error code 112: Host is down
OS error code 113: No route to host
OS error code 114: Operation already in progress
OS error code 115: Operation now in progress
OS error code 116: Stale NFS file handle
OS error code 117: Structure needs cleaning
OS error code 118: Not a XENIX named type file
OS error code 119: No XENIX semaphores available
OS error code 120: Is a named type file
MySQL error code 120: Didn't find key on read or update
OS error code 121: Remote I/O error
MySQL error code 121: Duplicate key on write or update
OS error code 122: Disk quota exceeded
OS error code 123: No medium found
MySQL error code 123: Someone has changed the row since it was read (while the table was locked to prevent it)
OS error code 124: Wrong medium type
MySQL error code 124: Wrong index given to function
OS error code 125: Operation canceled
MySQL error code 125: Undefined handler error 125
OS error code 126: Required key not available
MySQL error code 126: Index file is crashed
OS error code 127: Key has expired
MySQL error code 127: Record file is crashed
OS error code 128: Key has been revoked
MySQL error code 128: Out of memory in engine
OS error code 129: Key was rejected by service
MySQL error code 129: Undefined handler error 129
OS error code 130: Owner died
MySQL error code 130: Incorrect file format
OS error code 131: State not recoverable
MySQL error code 131: Command not supported by database
MySQL error code 132: Old database file
MySQL error code 133: No record read before update
MySQL error code 134: Record was already deleted (or record file crashed)
MySQL error code 135: No more room in record file
MySQL error code 136: No more room in index file
MySQL error code 137: No more records (read after end of file)
MySQL error code 138: Unsupported extension used for table
MySQL error code 139: Too big row
MySQL error code 140: Wrong create options
MySQL error code 141: Duplicate unique key or constraint on write or update
MySQL error code 142: Unknown character set used in table
MySQL error code 143: Conflicting table definitions in sub-tables of MERGE table
MySQL error code 144: Table is crashed and last repair failed
MySQL error code 145: Table was marked as crashed and should be repaired
MySQL error code 146: Lock timed out; Retry transaction
MySQL error code 147: Lock table is full; Restart program with a larger locktable
MySQL error code 148: Updates are not allowed under a read only transactions
MySQL error code 149: Lock deadlock; Retry transaction
MySQL error code 150: Foreign key constraint is incorrectly formed
MySQL error code 151: Cannot add a child row
MySQL error code 152: Cannot delete a parent row
MySQL error code 153: No savepoint with that name
MySQL error code 154: Non unique key block size
MySQL error code 155: The table does not exist in engine
MySQL error code 156: The table already existed in storage engine
MySQL error code 157: Could not connect to storage engine
MySQL error code 158: Unexpected null pointer found when using spatial index
MySQL error code 159: The table changed in storage engine
MySQL error code 160: There's no partition in table for the given value
MySQL error code 161: Row-based binlogging of row failed
MySQL error code 162: Index needed in foreign key constraint
MySQL error code 163: Upholding foreign key constraints would lead to a duplicate key error in some other table
MySQL error code 164: Table needs to be upgraded before it can be used
MySQL error code 165: Table is read only
MySQL error code 166: Failed to get next auto increment value
MySQL error code 167: Failed to set row auto increment value
MySQL error code 168: Unknown (generic) error from engine
MySQL error code 169: Record is the same
MySQL error code 170: It is not possible to log this statement
MySQL error code 171: The event was corrupt, leading to illegal data being read
MySQL error code 172: The table is of a new format not supported by this version
MySQL error code 173: The event could not be processed no other hanlder error happened
MySQL error code 174: Got a fatal error during initialzaction of handler
MySQL error code 175: File to short; Expected more data in file
MySQL error code 176: Read page with wrong checksum
MySQL error code 177: Too many active concurrent transactions
MySQL error code 178: Index column length exceeds limit
MySQL error code 179: Index corrupted
MySQL error code 180: Undo record too big
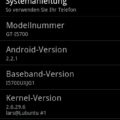
Vor einiger Zeit habe ich ein kleines Shell-Script (SSSwitch – auto-switch settings) geschrieben, welches mein Android Handy beim Start optimiert und die Kernel-Einstellungen anpasst, wenn der Bildschirm an bzw. aus ist. Einige der Einstellungen kann man auch unter Linux verwenden. Als Beispiel beschreibe ich hier kurz, wie man die I/O Leistung verbessern kann und wer allgemein etwas zum optimieren von Linux / Ubuntu lesen möchte, dem hilft ggf. folgender Blog-Post weiter -> SpeedUp-Ubuntu ;)
Ein Ausschnitt aus dem besagtem Skript …
# =========
# One-time tweaks to apply on every boot;
# =========
STL=`ls -d /sys/block/stl*`;
BML=`ls -d /sys/block/bml*`;
MMC=`ls -d /sys/block/mmc*`;
… hier wurde der externe / interne Speicher von Android angegeben unter meinem Linux-System würde ich hier also z.B. folgendes angeben.
SDA=`ls -d /sys/block/sda/*`;
# =========
# Remount all partitions
# =========
for k in $(busybox mount | cut -d " " -f3);
do
sync;
busybox mount -o remount,noatime,nodiratime $k;
done;
“atime – Update inode access time for each access. See also the strictatime mount option.” – man mount Hier schalten wir die Funktion aus, welche aufzeichnet wann ein Datei oder Verzeichnis zuletzt angesehen wurde, da wir diese Funktionalität unter Android selten benötigen werden. ;) Ggf. kann man diesen Abschnitt komplett so unter Linux / Ubuntu verwenden z.B.:
mount
/dev/sda5 on / type ext4 (rw,errors=remount-ro,commit=0)
[...]
/dev/sda3 on /boot type ext2 (rw)
/dev/sda6 on /home type ext4 (rw,commit=0)
[...]
for k in $(busybox mount | cut -d " " -f3); do sync; mount -o remount,noatime,nodiratime $k; done;
mount
/dev/sda5 on / type ext4 (rw,noatime,nodiratime,errors=remount-ro)
[...]
/dev/sda3 on /boot type ext2 (rw,noatime,nodiratime)
/dev/sda6 on /home type ext4 (rw,noatime,nodiratime)
[...]
… wie man sieht sind die neuen Mount-Optionen nun aktiv. Wer mehr dazu erfahren möchte findet in dem bereits erwähnten “SpeedUp Ubuntu“-Beitrag unter dem Punkt “3.1) Filesystem” mehr Infos.
# =========
# check enabled/disabled status for IO settings
# =========
if [ "$IO_SETTINGS_ENABLED" -eq "1" ];
then
# =========
# Optimize non-rotating storage
# =========
for i in $STL $BML $MMC;
do
/system/xbin/echo "1" > $i/queue/iosched/rq_affinity;
/system/xbin/echo "1" > $i/queue/iosched/low_latency;
/system/xbin/echo "64" > $i/queue/max_sectors_kb;
/system/xbin/echo "$READ_AHEAD_ALL" > $i/queue/read_ahead_kb;
done;
Hier legen wir unter anderem die Puffergröße von unseren Speichermedien ein. Als Beispiel zeige ich kurz wie sich der Buffer auf die Lesegeschwindigkeit auswirkt, wenn eine Datei z.B. erneut geöffnet wird. ;) Dazu benötigen wir zuerst einen Compiler (gcc)
… und in eine leere Datei (io_speed_buffer.c) einfügen, nun compilieren wir noch schnell das Programm mit folgendem Befehl …
gcc io_speed_buffer.c -o io_speed_buffer
… als nächsten benötigen wir eine etwa 10 MB große Datei als Eingabe, diese erzeugen wir mittels “dd” im aktuellen Verzeichnis.
dd if=/dev/zero of=./test count=20000
Und schon können wir mittels folgenden Befehl die optimale Buffer-Größe herausfinden. Wobei man bei minimaler Verbesserung nicht den höheren Wert nutzen sollte.
Ggf. kann man diese Einstellungen auch unter Linux direkt beim start ausführen lassen z.B. könnte man den zuvor gezeigten “echo”-Befehl in der “rc.local”-Datei einfügen. (/etc/rc.local)
# =========
# Optimize io scheduler
# =========
for i in $STL $BML $MMC;
do
/system/xbin/echo "$IO_SCHEDULER" > $i/queue/scheduler;
Welcher I/O Scheduler der beste für das Speichermedium ist kann man am betesten selber testen, indem man z.B. wieder den “dd”-Befehl verwendet. -> [Discussion] SSSwitch – auto-switch settings PS: Für mein Android-System nutze ich momentan “bfq” wobei “noop” gerade für SSD-Speichermedien schneller sein soll …
Hier noch ein-wenig Feintuning für die entsprechenden I/O Scheduler ;) ggf. müssen diese Werte auf anderen Systemen (Hardware) angepasst werden, dies habe ich bisher nur auf meinem Android System getestet. Falls euch / jemanden dieser Blog-Beitrag gefallen hat, werde ich weitere Einstellungen von dem Skript erklären … :)
In diesem Blog-Post stelle ich kurz mein kleines Shell-Skript vor, mit dem man sein Ubuntu 11.04 einrichten bzw. optimieren kann. Wenn jemandem noch ein Feature fehlt, kann dies angepasst werden. Zudem habe ich im Quelltext an den meisten Stellen Kommentare hinterlassen, sodass man gleich noch etwas über die shell lernen kann … :-)
[stextbox id=”info”]Über konstruktive Kritik und / oder Verbesserungen würde ich mich freuen.[/stextbox]
Ich habe hier ein kleines HowTo zum beschleunigen von Android / Spica geschrieben und wollte euch das Tweak-Skript für “bfs-Kernel” / “cfs-Kernel” / “Dateisystem” (ext2) / “3G/Edge Speed” … zur Verfügung stellen. -> Forum-Link & Download
Ich habe schon einige kleine Blog-Beiträge zum Thema “Shell / Bash” geschrieben und werde versuchen diese Blog-Beiträge zu einer hoffentlich umfassenden Einführung in das Thema Shell zusammenfassen… :-)
Was ist eine Shell?
Die Shell ist die Eingabe-Schnittstelle zwischen Computer und Benutzer, welche bei normaler Systemkonfiguration nach dem erfolgreichem Login eines Benutzers gestartet wird, so dass man auf dieser Kommandozeile die Möglichkeit hat weitere Programme zu starten. Die Shell könnte man somit aus Arbeitsumgebung bezeichnen, von wo aus der PC gesteuert werden kann bzw. Dateien bearbeitet werden können. Es gibt unterschiedliche Arten von Shell’s, wer ein modernes Linux-Betriebssystem (Debian, Ubuntu…) installiert, landet meistens in der sogenannten “bash“, darauf gehe ich jedoch gleich genauer ein. Die eingegebenen Texteingaben werden von der Shell interpretiert und ausgeführt, daher spricht man bei der Shell auch von einem Kommandozeileninterpreter (command-line interpreter, CLI).
Begrifflichkeiten!?
In Verbindung mit dem Begriff Shell hört man auch immer wieder folgendes …
Konsole: In ihrem ursprünglicher Definition war die Konsole ein Terminal, mit dem der Systemoperator die Systemfunktionen steuern konnte… heute wird der Begriff jedoch ebenfalls für “Terminalemulation” verwendet, zudem heißt die grafischen Terminalemulationen unter KDE “Konsole“.
Virtuelle Konsole: Die meisten Linux-Systeme kommen standardmäßig mit einigen virtuellen Konsolen daher, welche man über <Strg> + <Alt> + <F1> bis <F6> erreichen kann. Mittels <Strg> + <Alt> + <F7> wird der Desktop und somit die graphischen Oberfläche wieder angezeigt.
Terminal: Ein Terminal ist ein Computer, der den Zugriff auf einen entfernten Rechner erhält und die meisten Rechenoperationen somit nicht selber durchführt. (Terminal-PCs) Der Begriff “Terminal” wird heute jedoch auch als Abkürzung für “Terminalemulation” verwendet.
Terminalemulation: Mit einer Terminalemulation wird eine textorientierte Ein- und Ausgabeschnittstelle, ein Terminal emuliert, so dass man mehrer Instanzen eines Terminals auf dem Desktop zur Verfügung hat.
Wie bereits erwähnt kann man zum einen die virtuelle Konsolen, die mit tty bezeichnet werden per Tastenkombination erreichen. Die Abkürzung tty stammt von dem englischen Wort Teletype und wurde historisch bedingt von Unix übernommen. Mittels …
<Strg> + <Alt> + <F1>
… gelangt man in die erste der tty-Konsolen, in diesem Fall tty1.
Hinweis: Hat man eine grafische Oberfläche (Desktop) installiert, so befindet sich dieser standardmäßig auf tty7. Dieser Wert ist jedoch Variabel und kann umverlegt werden. Wer die Maus in einer solchen virtuellen Konsole verwenden will, sollte sich das Programm “gpm” anschauen / installieren.
Hat man sich einmal an die Desktop-Oberfläche gewöhnt, erscheinen einem diese virtuelle Konsolen meist wenig komfortabel, daher gibt es einige Programme (Terminalemulation) welche den Funktionsumfang erheblich erweitern.
KDE – Konsole
KDE-Nutzern steht das bereits erwähnte Programm “Konsole” zur Verfügung, wobei sich der Kreis der Begrifflichkeiten hier schließt und die Verwirrung bei so manchen gerade erst einsetzt. ;-) Lässt man dies außer Acht ist dieses Terminal(emulation) sehr gut. Das Programm unterstützt Tabs, Transparenz, verschiedenste Farbschema, unterschiedliche Schriften und man kann Profile anlegen.
konsole
Gnome – Terminal
Gnome-Nutzer verfügen von Haus aus über ein Programm mit dem Namen “Gnome-Terminal”. Ich persönlich bevorzuge dieses Programm, wobei dies wahrscheinlich eine Übungssache ist…
TASTENKÜRZEL
BEDEUTUNG
<Strg> + <Umschalttaste> + t
öffnet einen neuen Tab
<Strg> + d
schließt einen Tab
<Strg> + Bild rauf
öffnet nächsten Tab (rechts) bzw. den ersten
<Strg> + Bild runter
öffnet vorherigen Tab (links) bzw. den letzen
<Strg> + <Umschalttaste> + Bild rauf
verschiebt einen Tab nach rechts
<Strg> + <Umschalttaste> + Bild unter
verschiebt einen Tab nach links
Hinweis: Wer das Terminal immer Griffbereit haben möchte, sollte sich einmal “guake” anschauen … ;-)
gnome_terminal
Xterm
Xterm ist Bestandteil des X.org Projekts und war lange Zeit das Standardterminal für Linuxsysteme mit grafischer Oberfläche.
CLI Companion
Wer die Linux-Befehle noch lernen möchte oder sich einige komplizierte Behle öfter benötigt, kann sich auch dieses Terminal anschauen. -> cli-companion-die-gui-in-der-konsole
CLICompanion
Terminator
“Terminator ist ein in Python geschriebener Terminal-Emulator für die Desktop-Umgebung GNOME, der es ermöglicht mehrere Terminals innerhalb eines Fensters bzw. einzelner Tabs zu benutzen und mittels Tastatur-Kürzeln zwischen diesen zu wechseln. So kann man ohne Tabs und ohne weitere Terminalfenster mehrere Shells zur selben Zeit offen haben.” – http://wiki.ubuntuusers.de/Terminator
terminator_split_example
Wenn man seine Standard-Terminal ändern möchte, kann man dies mit dem Alternativen-System bewerkstelligen…
Wenn man sich ein wenig näher mit dem Thema beschäftigt, stellt man schnell fest, dass es eine Menge Alternative Shells gibt. Ich beschränke mich einfach mal auf die (heutige) Standard-Shell die bash und einer Alternative der zsh (Z-Shell)
Bourne Again Shell (bash)
Die Bourne Again Shell ist die Standard-Shell der meisten Linux-Distributionen. Die Shell beherrscht die Features der Borune- Korn- und C-Shell. Redet jemand von einer Shell, spricht man meistens von Bash. Um das volle Potenzial der Bash zu nutzen sollte man sich “.bashrc“-Datei anschauen und an seine Bedürfnisse anpassen, für den Anfang sollte meine Datei als Vorlage genügen. -> bashrc
Z-Shell (zsh)
Die Zsh kann man als eine Zusammenstellung aller Verbesserungen und Features aus der bash, der csh und der tcsh betrachten.
Zu einigen ihrer Features zählen:
eine frei programmierbare Wortvervollständigung (TAB-Completion)
die Möglichkeit, die History aus anderen – gleichzeitig laufenden – Shells zu nutzen
Rechtschreibüberprüfung
nahezu vollständige Kompatibilität zur bash, ksh und tcsh
Bei der Z-Shell kann hat man noch viel mehr Einstellungsmöglichkeiten, welche einem Anfangs ggf. überfordern können, daher auch hier meine “.zshrc“-Datei als Vorlage. -> zshrc
Z-Shell installieren:
sudo aptitude install zsh
Z-Shell ausprobieren:
zsh
Standardmäßig die Z-Shell verwenden:
sudo chsh -s /usr/bin/zsh `whoami`
Probieren geht über studieren…
… was ist damit sagen will, wer einmal die Vorteile der Shell erkannt hat und einige Befehle kennt, wird die Shell lieben lernen!
Linux-Dateipfade einigermaßen kennen
Auch wenn in der Shell meist angezeigt wird in welchem Verzeichnis man sich gerade befindet, kann es seht hilfreich sein, wenn man ungefähr weiß wo sich was bei Linux befindet! -> http://wiki.ubuntuusers.de/Verzeichnisstruktur
Verzeichnis
Bedeutung
~ Windows
/
Wurzelverzeichnis
C:\
/boot
Bootloader
C:\
/etc
Systemkonfiguration
registry,
C:\WINDOWS\*.ini
/bin
Systemprogramme für Benutzer
C:\WINDOWS\,C:\WINDOWS\COMMAND\
/sbin
Systemprogramme und -dienste für Admins
/lib
Systembibliotheken und Treiber
C:\WINDOWS\SYSTEM32\
/tmp
Temporäre Dateien
C:\WINDOWS\TEMP\
/usr
(“Unix System Resources”)
/usr/bin
Programme für Benutzer
C:\Programme\*\
/usr/sbin
Programme und Dienste für Admins
/usr/lib
Bibliotheken
/home
Heimatverzeichnisse
C:\Dokumente und Einstellungen\
/home/user
Heimatverzeichnis des Benutzers user
/root
Heimatverzeichnis des Benutzers root
/var
Daten von Diensten
/var/log
Systemprotokolle
/media
Wechseldatenträger, z.B. USB-Stick
/media/cdrom
CD-ROM
A:\, D:\, E:\,...
Beim Login in die Shell, landet man meistens in seinem eigenen home-Verzeichnis (z.B.: /home/lars/). Im “Prompt” (dem Text vor der Eingabeaufforderung, in der Shell) könnte nun so etwas angezeigt werden “lars@ubuntu:~$“.
lars ist hier der User-Name, ubuntu der Name des PCs und das ~ (Tilde-Zeichen) steht als Abkürzung und Synonym für das Homeverzeichnis, in welchem wir uns gerade befinden, dies kannst du gleich durch die Eingabe des Befehl “pwd” (print working directory) überprüfen. ;-)
Groß- und Kleinschreibung beachten
Anders als bei Windows unterscheidet Linux Groß- und Kleinschreibung, hier einige Beispiele zur Verdeutlichung …
… anzeigen lassen, welche Dateien / Verzeichnisse im aktuellen Verzeichnis erstellt wurden. Mittels “rm” bzw. “rmdir” kannst du diese Dateien wieder löschen. Falls du versehentlich z.B.: “touch ./–help” ausführst und somit eine leere Datei mit dem Namen-“–help” erstellt hast, kannst du diese mittels “rm ./–help” wieder entfernen.
Der Befehl “man” (z.B.: man mkdir) zeigt eine ausführliche Hilfe zum angegebenen Befehl an und “apropos” (z.B.: apropos mkdir) zeigt dessen Funktion schnell an… zudem kann man hinter den Befehlen auch “–help” (mkdir –help) schreiben
Achtung
Achtung: Vorsicht der Befehl “rm -r” löscht rekursiv, am Anfang sollte man diesen Parameter ggf. mit -i kombinieren, so dass vor dem löschen einer Datei noch einmal nachgefragt wird, ob diese wirklich gelöscht werden soll. (z.B.: rm -ri lall/) -> safe-rm can save your life
Die Navigation
Ebenfalls ein sehr großes Themenfeld ist die Navigation in der Shell, angefangen von der Navigation durch die Verzeichnisse / Dateien … über die Verwendung der History (bereits eingegebene Befehle in der Shell) … bis hin zur Navigation innerhalb der Shell.
Navigation in Verzeichnissen
Befehl
BEDEUTUNG
cd ..
wechselt ein Verzeichnis nach oben
cd ../..
wechselt zwei Verzeichnise nach oben
cd ~
wechselt in dein home-Verzeichnis
TAB
durch das drücken der Tabulator-Taste, wird deine Eingabe vervollständigt -> ggf. 2x hintereinander TAB drücken !!!
».«
jedes Verzeichnis enthält eine Referenz auf sich selbst, diesen Punkt benötigt man vor allem,wenn man eine ausführbare Datei starten möchte… (z.b: cd /bin/; ./bash;)
pwd
zeigt an wo du dich befindest
Durch das drücken der TAB-Taste kann man sich viel Tipparbeit ersparen… :-)
Navigation in der Shell
BEFEHL / Tastenkürzel
BEDEUTUNG
<Strg> + d
Logout aus der Shell (logout bzw. exit)
<Strg> + c
laufender Prozesse (im Vordergrund) wird beendet
<Strg> + l
räumt die Ausgabe auf (clear)
fc -l
zeigt die letzten Befehle in einer Liste an
Pfeiltasten (noch oben / unten)
letzte Befehle durchblättern
Pfeiltasten (noch rechts / links)
Cursor auf der Konsole (rechts / links) bewegen
<Strg> + r
sucht einen Befehl in der Bash-History (mehrmaliges drücken von Strg+r geht weiter in der History zurück)
Alt + .
schreibt den letzten Parameter des letzen Befehls auf die Konsole
!$
schreibt den letzten Parameter des letzen Befehls auf die Konsole (Alt + .)
!!
führt den letzten Befehl noch einmal aus
!string
startet den letzten Befehl, der mit sting anfängt
!?string
startet den letzten Befehl, der string enthält
^sting1^string2
wiederholt den letzten Befehl, wobei sting1 doch string2 ersetzt wird
<Strg> + a
Cursor am Anfang der Zeile
<Strg> + e
Cursor am Ende der Zeile
<Strg> + w
schneidet das letzte Wort aus
<Strg> + u
scheidet alles vor dem Cursor aus
<Strg> + k
scheidet alles hinter dem Cursor aus
<Strg> + y
fügt die zuletzt ausgeschnittenen Daten ein
PS: wie bereits erwähnt entfaltet die Shell ihr volles Potenzial erst, wenn man diese ein wenig an seine Wünsche anpasst, daher hier noch einmal der Verweiß auf die .bashrc und .zshrc …
Kommandos hintereinander ausführen
Wie bereits kurz zuvor gezeigt, kann man Befehle auch hintereinander ausführen… z.B.:
cd /bin/; ./bash;
Hier werden die Befehle “cd /bin/” und “./bash” einfach nacheinander ausgeführt. Wenn man den zweiten Befehl jedoch nur ausführen möchte, wenn der erste Befehl ohne Probleme funktioniert hat, kann man && zwischen den beiden Befehlen verwenden… z.B.:
cd /bin_lall/ && ./bash;
Und wenn man den zweiten Befehl nur ausführen möchte, wenn der erste Befehl nicht funktioniert hat, nimmt man “||“… z.B.:
cd /bin_lall/ || echo "ggf. existiert /bin_lall nicht";
PS: Natürlich muss man nicht jedesmal in das Verzeichnis /bin wechseln, wenn man ein Programm aus diesem Verzeichnis öffnen möchte, dazu wird in der Shell die Variable “$PATH” verwendet. z.B.:
Wer direkt in der Shell Dateien verändern möchte, sollte sich den “vim”-Editor anschauen, wie die Shell ist dieser Editor gewöhnungsbedürftig aber man gewinnt Ihn mit der Zeit lieb… ;-) In diesem HowTo habe ich versucht die wichtigsten Funktionen von vim zusammenzufassen. Und hier noch eine Schnellübersicht:
BEFEHL / TASTENKÜRZEL
BEDEUTUNG
i
Text einfügen, vor dem Cursor
R
Text ab Cursor-Position überschreiben
<Strg> + v
Bereich markieren
<ESC>
Bearbeitungsmodus beenden
y
kopieren
p
einfügen
:q
vi/vim beenden
:w
Datei speichern
vi-vim-cheat-sheet_de_layout
Es gibt unter Linux noch etliche Programme, welche einem beim bearbeiten von Dateien hilfreich sein können z.B.: sed
sed -i 's/Ubuntu/Windows/g' test.txt
Dieser Befehl ersetzt das Wort “Ubuntu” durch “Windows” in der ganzen Datei “test.txt” im aktuellen Verzeichnis. Weitere Infos zu sed findest du hier -> streameditor-sed und hier noch ein alter Beitrag zum Thema -> Dateien-in-der-shell-bearbeiten
Programme im Hintergrund verschieben
Man kann Programme und Befehle auch im Hintergrund ausführen bzw. diese in den Hintergrund verschieben…
kommando1 und kommando2 wurden beide im Hintergrund ausgeführt, dann wurde kommando2 mittels dem Befehl “fg” wieder in den Vordergrund geholt. Wenn man kommando2 wieder in den Hintergrund verschieben möchte drücken wir: <Strg> + z
In order to optimize the website and to continuously improve it, this site uses cookies. By continuing to use the website, you consent to the use of cookies.