Nachdem ich nun bereits seit einigen Jahren lerne zu deklarieren und zu programmieren, werde ich im folgenden beschreiben was ich bisher gelernt habe.
Kurz zu mir: Lars Moelleken |
> Assistent für Betriebsinformatik
> Fachinformatiker Systemintegration
> Informatik Studium (Abgebrochen)
> Fachinformatiker Anwendungsentwicklung
Was habe ich in meiner Ausbildung zum Fachinformatiker Systemintegration gelernt?
– Du lernst nur soviel, wie du lernen willst.
Im Gegensatz zur Schule / Fachhochschule konnte und musste ich mir vieles in der Ausbildung selber beibringen und erarbeiten. Und man erkennt schnell, dass man nur soviel lernt wie man möchte. Wenn man dies einmal verstanden hat, dann setzt man sich auch gerne hin und lernt z.B. Linux- / Shell-Befehle auswendig, besucht weitere Kurse (z.B. bei der VHS), geht zu Meetups oder Konferenzen. Krümmer dich um dein Können, denn wenn man etwas macht, sollte man es auch richtig machen.
“Eine Investition in Wissen bringt noch immer die besten Zinsen.” – Benjamin Franklin
– Keine Panik!
Was man ziemlich schnell als Sysadmin lernt ist „Ruhe bewahren“ and think first – then act. Überstürzter Aktionismus hilft nicht weiter und schadet meistens sogar. Bevor man handelt, sollte man zuvor selber einige Informationen einholen (Infos von Logfiles, Hardware Status, System Status, …) so dass man auch wirklich weiß was wie man den Fehler behene kann.
– Linux && Kommandozeile <3
Wer bisher noch nicht mit einem Unix Betriebssystem gearbeitet hat, weiß leider nicht was er verpasst. Wer aus welchen Gründen auch immer Windows nutzen möchten oder muss, kann trotzdem mit der Git-Bash [+ .dotfiles] einige Vorteile von Linux nutzen. Und seine eigene Komfortzone zu verlassen und neue Betriebssysteme auszuprobieren hilft dabei den Computer insgesamt besser zu verstehen. An dieser Stelle empfehle ich mal wieder “Arch Linux”.
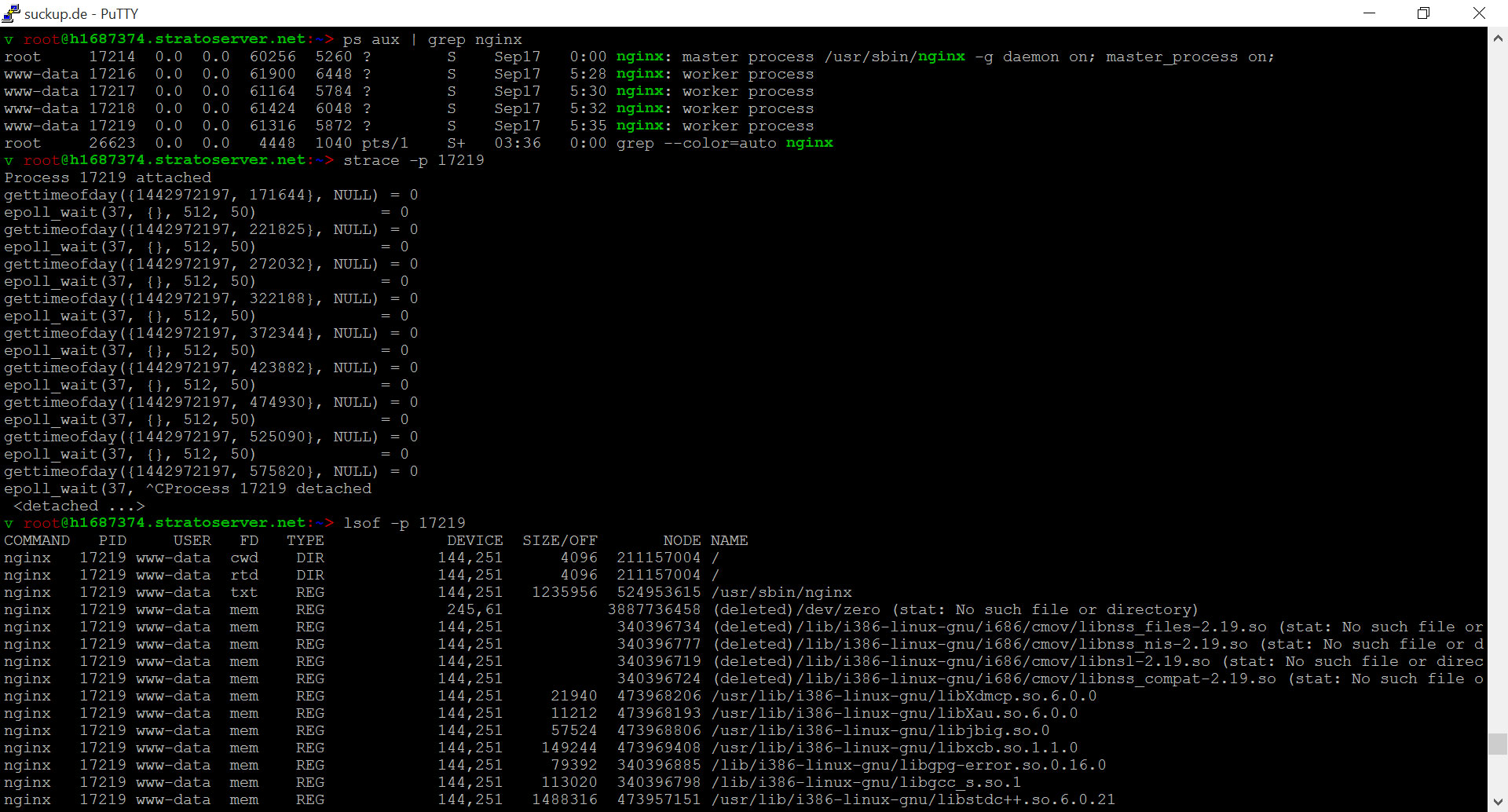
Man sollte sich außerdem mit der Kommandozeile vertraut machen, wenn du deine Produktivität rapide steigern möchtest. Zum Beispiel sollte man folgende Befehle man genauer ansehen: find / grep / lsof / strace
find – Linux
– Lies in der offizielle Dokumentation (und erst dann bei “Stack Overflow”).
Ob Cisco oder Manpages man liest am besten die offizielle Dokumentation zu der Programm-Version / Hardware-Version welche man gerade einsetzt. Beim programmieren nutzt man jedoch häufig stackoverflow.com und findet schnell Antworteten und Code-Beispiele, aber das “Warum” und “Wie” kommt dabei meistens zu kurz. Wenn man als erstes in die Spezifikation / Dokumentation schaut löst man nicht nur dieses Problem, sondern man versteht ggf. das Problem und weiß auch wie man ähnliche Probleme lösen kann.
– Mach immer ein Backup (benutze nieeemals betrunken “sudo”).
Manche Sachen muss man auf die hart Tour lernen, apt-get install safe-rm zu installieren gehörte für mich anscheinend dazu!
“Der Mensch hat dreierlei Wege klug zu handeln; erstens durch Nachdenken, das ist der edelste; zweitens durch Nachahmen, das ist der leichteste; und drittens durch Erfahrung, das ist der bitterest.” – (Konfuzius)
– Sei ehrlich zu Kunden, Mitarbeitern und dir selbst.
Sei ehrlich zu Kunden, insbesondere wenn etwas schief geht. Wenn das Produkt (z.B. Server) vom Kunden ausfällt, dann biete Lösungsvorschläge an und keine Ausreden und löse das Problem nicht die Schuldfrage. Niemandem ist damit geholfen, wenn man mit dem Finger auf den Kollegen oder Kunden zeigt, dem Server nicht, dem Kunden nicht und letztlich einem selbst nicht.
– Stelle Fragen, wenn du etwas nicht verstanden hast.
Rede mit Kunden nicht über etwas was du nicht verstehst, etwas nicht zu wissen (insbesondere in der Ausbildung) ist nicht schlimm, aber dann frage einen Kollegen bevor du mit einem Kunden darüber sprichst!
– Denke über dein Tun nach (nicht nur auf der Arbeit).
Wenn man Dinge hinterfragt und über seine Arbeit und sein Tun nachdenkt, dann kann man sich persönlich weiterentwickeln. Hinterfrag kritische zum Beispiel ob man wirklich bei Amazon bestellen sollte oder sollte man das Buch lieber direkt beim Verlag bestellt? Welchen Vorteil hat der Autor davon und habe ich Nachteile? Sollten wir Nagios3 oder besser direkt Icinga einsetzen? Hinterfrage deine Arbeit und bewerte kritisch ob dies wirklich eine gute / sichere / zukunftsorientierte Lösung ist.
Falls man sich selber nicht sicher ist oder eine zu eingeschränkte Sichtweise hat (weil man z.B. nur diese eine Lösung kennt), dann sollte man sich neues Wissen aneignen, ggf. andere Lösungen oder „best practices“ recherchieren und mit anderen über die Thematik diskutieren.
– Google korrekt nutzen …
Wenn man ein Problem recherchiert, dann sucht man nach der Fehlermeldung in Anführungszeichen. Und wenn man keine Fehlermeldung hat sucht man zusätzlich nach der Versionsnummer oder / und einer entsprechenden Jahreszahl.
https://suckup.de/2010/02/google-hacks-und-tricks/
Was habe ich in meiner Ausbildung zum Fachinformatiker Anwendungsentwicklung gelernt?
– Du lernst niemals aus …
Wenn man anfängt sich mit der Web-Programmierung (HTML, CSS, JS, Node.js, PHP, …) zu beschäftigen, weiß man zunächst gar nicht wo man anfangen soll! Es gibt so vieles zu lernen und dieses Gefühl begleitet einen einige Zeit (Jahre), bis man wiederkehrende Konzepte erkennt. Der Vorteil in der Web-Programmierung ist jedoch, dass viele unterschiedliche Dinge gemeinsame APIs haben oder zumindest kombiniert werden können. Ich kann in PHP eine Klasse schreiben, welche mir Data-Attribute für mein HTML erstellt, welche ich wiederum mit JavaScript auslesen kann, um diese entsprechend über CSS-Klassen zu gestalten. Aber es bleibt dabei, man lernt niemals aus und genau das ist das Spannende an diesem Job!
– Programmiere jeden Tag. (aber setzte dir selber ein LIMIT 1, x)
Auch wenn der Chef heute nicht im Büro ist und man als Azubi gerade keine Aufgabe hat, dann programmiere, wenn du Zuhause auf der Couch sitzt (und keine neue Serie auf Netflix läuft), dann programmiere und wenn du Urlaub hast, hast du Urlaub!
Hier ein interessanter Link von „John Resig“ (jQuery):
http://ejohn.org/blog/write-code-every-day/
– Denke in Modulen und Packages …
Wenn man jeden Tag Software schreibt, möchte man die selbe Funktionalität (z.B. Datenbankverbindung, E-Mail senden oder Error-Logging …) nicht mehrfach für verschiedene Projekte programmieren (und eigentlich will man Standard-Funktionen gar nicht selber programmieren). Daher sollte jeder Programmierer in Modulen denken und eine Applikation in verschiedenen, am besten austauschbaren Teilen konzipieren. In vielen Fällen kann man das System dann auch besser erweitern, da es bereits eine Schnittstelle für Module gibt, welche man nutzen kann. Die Unabhängigkeit und Entkopplung von Programmteilen hat auch den Vorteil, dass Seiteneffekte von unterschiedlichen Stellen im Quelltext weiter vermieden werden. Außerdem sollte man die Kopplung von den entsprechenden Modulen minimieren, da man ansonsten nichts durch Modulen gewinnt.
Für fast alle Dinge in der Web-Entwicklung gibt es bereits Paket-Manager:
– Frontend (css, js): bower (npm)
– Backend (Node.js): npm
– Backend (php): composer
– Backend (ruby): gem
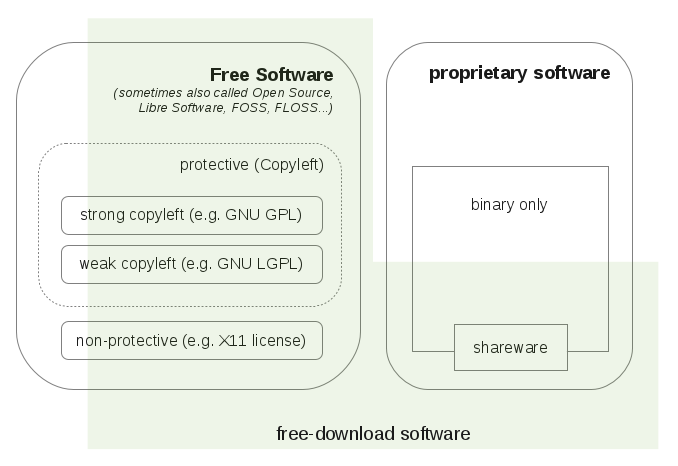
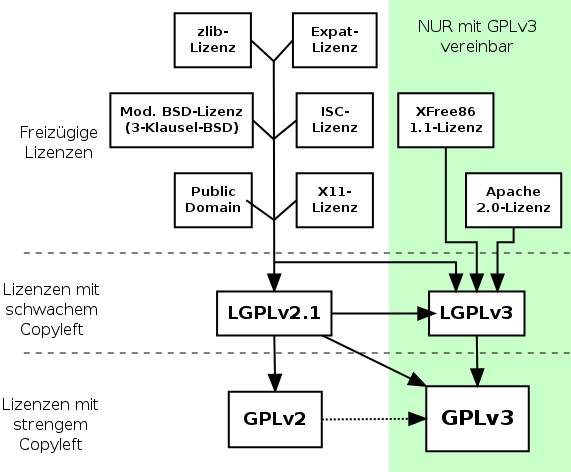
– Open Source <3
Wenn man bereits mit Modulen und Packages arbeitet, kann man diese auch gleich als Open Source Projekt veröffentlichen + Tests via Travis-CI + Code-Coverage anzeigen + zumindest einer kleinen Dokumentation und schon allein aus diesen Gründen lohnt sich die Veröffentlichung als Open Source. Auch die Code-Qualität steigt (nach meiner Erfahrung), da man den Quelltext der Öffentlichkeit freigibt und sich daher mehr oder weniger Bewusst auf die Code-Qualität achtet.
Der Moment, wenn man seinen ersten Pull-Request für seine Software erhält oder mit jemanden aus Israel, der Türkei und der USA zusammen programmiert, unbezahlbar.
– Git und Gut!
Ich weiß nicht wie Menschen ohne eine Versionskontrolle mit dem PC arbeiten können. Selbst bei privaten kleineren Projekten oder für Konfigurations-Dateien setze ich “git” ein. Es folgende einige Vorteile, aber die Liste kann man bestimmt noch um einige Punkte erweitern …
Vorteile:
– Änderungen können nachvollzogen werden (git log, git blame)
– Änderungen können rückgängig gemacht werden (git revert, git reset)
– Änderungen können von anderen Mitarbeitern gereviewed werden
– Mitarbeiter können gleichzeitig an einem Projekt arbeiten (git commit, git pull, git push)
– Entwicklungszweige (Forks) können gleichzeitig entwickelt werden (git checkout -b , git branches)
– Nutze “github.com” und lerne von den besten.
Github ist noch einmal was ganz anders als zum Beispiel ein privater (kostenloses / freies) „gitlab“-Server, da man sich indirekt darauf geeinigt hat, dass man die Plattform für Open Source Projekte verwendet, obwohl github selbst nicht Open Source ist. Man findet daher wirklich viele gute Entwickler und Projekte auf github.com und man kann bereits durch das lesen von Quelltext / Quelltextänderungen vieles lernen. Insbesondere weil man die Entwicklung der Projekte nachvollziehen und verfolgen kann: Wie strukturieren andere Ihren Code? Wie schreiben andere Ihre “commit”-messages? Wie viel Code sollte eine Methoden beinhalten? Wie viel Code sollte eine Klasse beinhalten? Welche Variablen-Namen sollte man besser vermeiden? …
https://github.com/trending
https://twitter.com/trendinggithub
– Tests ausprobieren.
Gerade wenn man Tests für seine eigenen Funktionen und Klassen schreibt, erwischt man sich dabei genau die Fällte zu testen, welche man bereits bedacht hat, daher sollte man die entsprechende Funktionalität mit unterschiedlichen (noch nicht bedachten) Daten testen. Außerdem ist es manchmal hilfreich den Quelltext absichtlich (temporär) zu sabotieren, so dass man seine Tests ebenfalls einmal testen kann. Hier einige Listen mit Eingaben welche man testen könnte: https://github.com/minimaxir/big-list-of-naughty-strings
PS: außerdem sollte man einen zusätzlichen Test hinzufügen, wenn ein Fehler bereits aufgetreten ist, so dass man Fehler nur einmal finden muss. Hier ein Beispiel: https://github.com/swiftmailer/swiftmailer/tree/5.x/tests/bug/Swift
– Automatisiere deine Tests.
Unit-Tests, Integrationstest und Frontend-Tests helfen nur, wenn diese auch ausgeführt werden, daher sollte man sich frühzeitig mit automatisierten Tests beschäftigen und diese bei Quelltextänderungen auch automatisch ausführen. Wo und wann diese Tests ausgeführt werden entscheidet gleichermaßen darüber, wie effektiv diese Tests letztendlich sind. Sobald man einige Tests geschrieben hat, versteht man auch warum man auf zusätzliche Parameter bei Methoden und Funktionen besser verzichten sollte, da die Anzahl der Tests exponentiell ansteigt.
https://en.wikipedia.org/wiki/Software_testing
– Deployment ist wichtig …
Sobald man mit mehr als einem Entwickler an einem Projekte arbeitet, möchte man irgendeine Art von Deployment einsetzten, weil man seine Änderungen sonst gegenseitig überschreibt. Außerdem möchte man, dass der Quelltext aus dem Versionskontroll-System auf dem Server liegt, ansonsten kann man eine Applikation nicht warten bzw. erweitern!
– Konzepte zu verstehen ist wichtiger als dessen Implementierung.
Design-Patterns (Programmier-Konzepte) zu verstehen hilft einem nicht nur in der aktuellen Programmiersprache, sondern kann meistens auch auf andere Programmiersprachen angewendet werden.
Grundlegende Konzepte (Klassen, Objekte, OOP, Funktionen, ORM, MVC, DDD, Unit-Tests, Data-Binding, Hooks, Template-Engine, …) findet man in vielen Frameworks / Programmiersprechen und sobald man die Begriffe und Konzepte einmal verstanden hat, ist es gar nicht mehr so schwer neue / unterschiedliche Frameworks einzusetzen. Und man erkennt unterschiedliche stärken und schwächen von diesen Frameworks / Werkzeugen: „Wer als Werkzeug nur einen Hammer hat, sieht in jedem Problem einen Nagel.“
– Probleme lösen heißt auch Kunden verstehen.
Design-Patterns gehören zur Grundausstattung, aber man sollte sich auch immer wieder die Frage stellen: Welches Problem mit der gegebenen Lösung eigentlich gelöst werden soll? Ggf. findet man eine noch eleganterer / einfacherer Lösung. Und manchmal will der Kunde eigentlich auch was ganz anders, er weiß es nur noch nicht oder jemand hat den Kunden falsch verstanden.
– Probleme lösen heißt auch Prozesse verstehen.
Es ist aber ebenso wichtig zu verstehen warum ein bestimmtes Feature implementiert wird, da man ansonsten etwas programmiert was entweder gar nicht gebraucht bzw. genutzt wird. Man sollte daher die entsprechende Aufgabenstellung vor der Implementierung und noch vor der Planung im Gesamtkontext verstehen.

– Verteile auf mehreren Dateien.
Nutze eine Datei für eine Klasse, nutze eine Datei für CSS-Eigenschaften eines Modules oder einer speziellen Seite, nutze eine neue Datei für jeden neuen View. Den Quelltext auf verschiedene Dateien / Verzeichnisse aufzuteilen bietet viele Vorteile, so weiß der nächste Entwickler wo neuer Quelltext abgelegt werden soll und man findet sich schneller im Quelltext zurecht. So geben viele Frameworks bereits eine vordefinierte Verzeichnisstruktur für z.B. Model / View / Controller vor.
– Lesbarkeit geht vor!
Die Lesbarkeit von Quelltext sollte immer an erster Stelle stehen, da man selber oder Arbeitskollegen diesen Code in Zukunft warten bzw. erweitern müssen.
YouTube Videos zum Thema “Clean Code”: https://www.youtube.com/results?search_query=%22Clean+Code%22&search_sort=video_view_count
Best Practices: http://code.tutsplus.com/tutorials/top-15-best-practices-for-writing-super-readable-code–net-8118
– Gute Namensgebung ist eine der schwierigsten Aufgaben in der Programmierung.
Es fängt beim Domainnamen / Projektnamen an, geht über Dateinamen zu Namen von Verzeichnissen, Klassennamen, Methodennamen, Variablennamen, CSS-Klassennamen. Mache dir immer bewusst, dass andere dies lesen werden und verstehen müssen. Daher sollte man auch auf unnötige Abkürzungen verzichten und schreiben, was man beschreiben möchte.
Wir wollen beschreiben was die Funktion macht und nicht wie diese implementiert ist.
-> Falsch: farbeBlack(), nutzeFarbe(), …
-> Richtig: $page->setColor(‘black’), $page->getColor(), …
Variablen sollten beschreiben was diese beinhalten und nicht wie diese gespeichert sind.
-> Falsch: $array2use, $personenArray, …
-> Richtig: $pages, $persons, …
Zusammenfassung: Beschreibe was die Variable / Methode / Funktion / Klasse ist, nicht wie diese implementiert ist.
Weniger schlecht PHP programmieren
– An Kommentare sparen (zumindest inline) …
Gute Kommentare erklären “Warum” und nicht “Was” gemacht wird und sollten dem Leser einem Mehrwert bieten, welcher nicht bereits im Quelltext (Stichwort: Namensgebung) beschrieben ist.
Beschreibungen für Methoden, Funktionen und Klassen (javadoc, phpdoc, …) sollte meiner Meinung nach immer hinterlegt werden, so dass man seine Dokumentation im Quelltext abbildet. Moderne IDEs können zudem prüfen, ob die Parameter und Rückgaben korrekt hinterlegt wurden.
https://de.wikipedia.org/wiki/PHPDoc
https://en.wikipedia.org/wiki/JSDoc
https://de.wikipedia.org/wiki/Javadoc
Beispiele für inline Kommentare:
schlechter Code:
// Prüfen ob der User bereits einloggt ist
if (isset($_SESSION['user_loggedin']) && $_SESSION['user_loggedin'] > 1) { ... }
etwas besserer Code:
// check if the user is already logged-in
if (session('user_loggedin') > 1) { ... }
besserer Code:
if ($user->isLoggedin === true) { ... }
… und noch ein Beispiel …
schlechter Code:
// regex: email
if (!preg_match('/^(.*<?)(.*)@(.*)(>?)$/', $email) { ... }
besserer Code:
define('EMAIL_REGEX_SIMPLE', '/^(.*<?)(.*)@(.*)(>?)$/');
if (!preg_match(EMAIL_REGEX_SIMPLE, $email) { ... }
– Konsistenz in einem Projekt, ist wichtiger als persönliche Präferenzen!
Nutze den bestehenden Code und nutze gegebene Funktionen. Wenn es Vorteile bringt, dann ändern / refactor den entsprechenden Code aber refactor dann alle Stellen im Projekt welche auf diese Weise implementiert sind.
Beispiel: Wenn man bisher ohne Template-System gearbeitet hat und aus „Gründen“ eines einsetzten möchte, dann nutze dies für alle Templates im Projekt und nicht nur für deinen aktuellen Use-Case, da ansonsten inkonsistenten im Projekt entstehen. Wenn man z.B. eine neue „Email→isValid()“ Methode, dann sollte man auch alle bisherigen RegEx-Versuche im aktuellen Projekt durch die „Email“-Klasse ersetzten, weil ansonsten wieder inkonsistenten entstehen.
– Ein einheitlicher Code-Style wirkt sich sehr positiv auf die Qualität aus!
Wie im echten Leben gilt auch hier, wenn irgendwo bereits Müll liegt, sinkt die Hemmschwelle seinen einen Müll dort abzuladen extrem an. Wenn aber alles schön ordentlich aussieht, wirft man nicht einfach eine “randumInt() { return 4; } “-Funktion hinzu.
Man sollte sich im Team einen Code-Style überlegen und diesen in neuen Projekten einsetzten. In bestehenden Projekten gibt wieder Konsistent geht vor.
– Nutze Funktionale-Prinzipien && Objekt-Orientierte-Konzepte.
Eine reine Funktion (“Pure Functions”) ist nur von ihren Parametern abhängig und mit den selben Parametern liefert diese immer das selbe Ergebnis. Diese Prinzipien kann man auch in OOP berücksichtigen und sogenannte Unveränderbare Klassen erstellen (immutable class).
https://en.wikipedia.org/wiki/Pure_function
https://de.wikipedia.org/wiki/Objektorientierte_Programmierung
https://en.wikipedia.org/wiki/Immutable_object
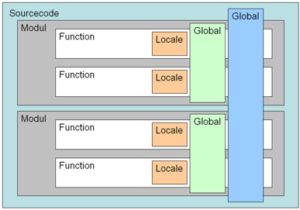
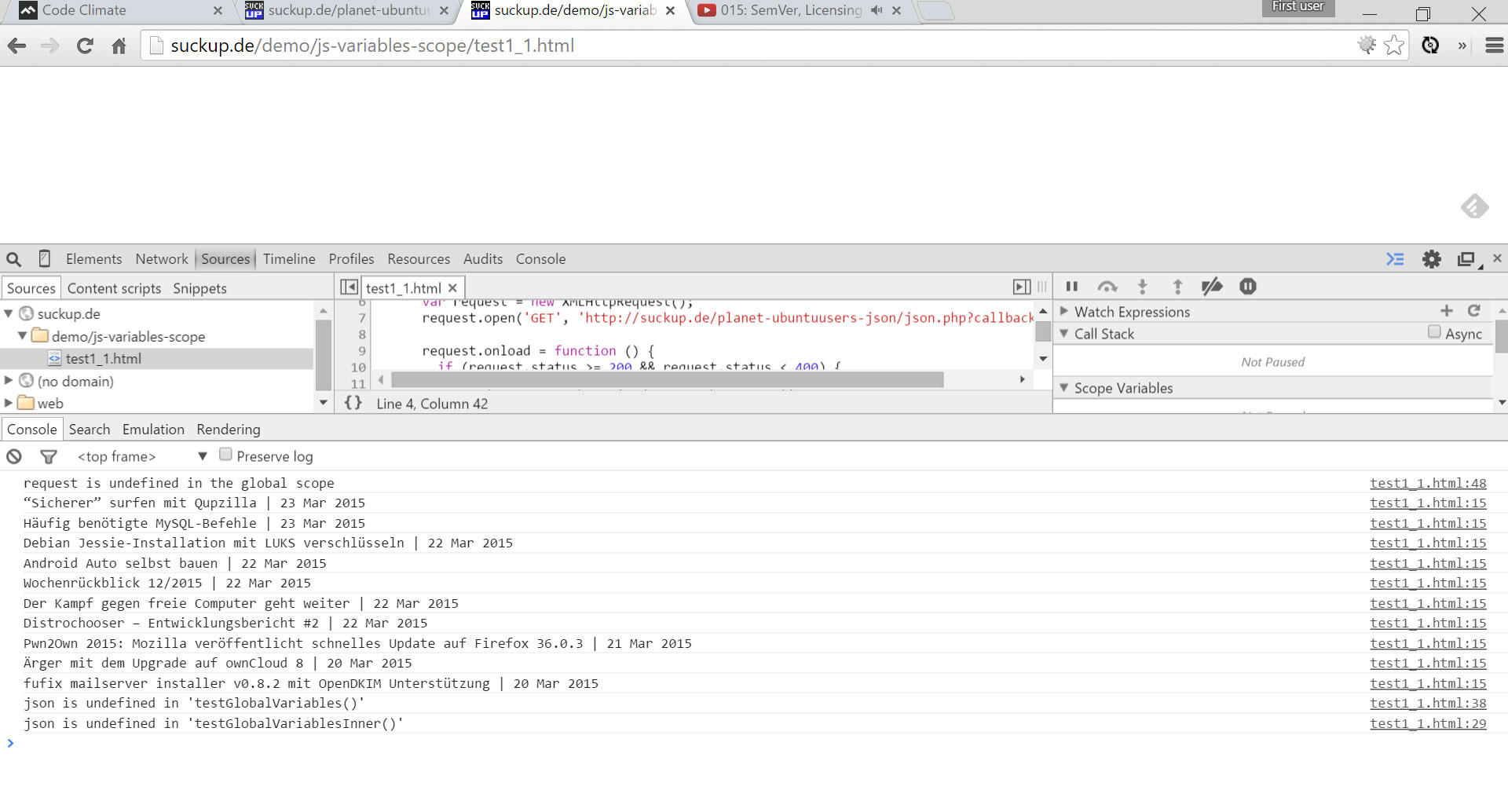
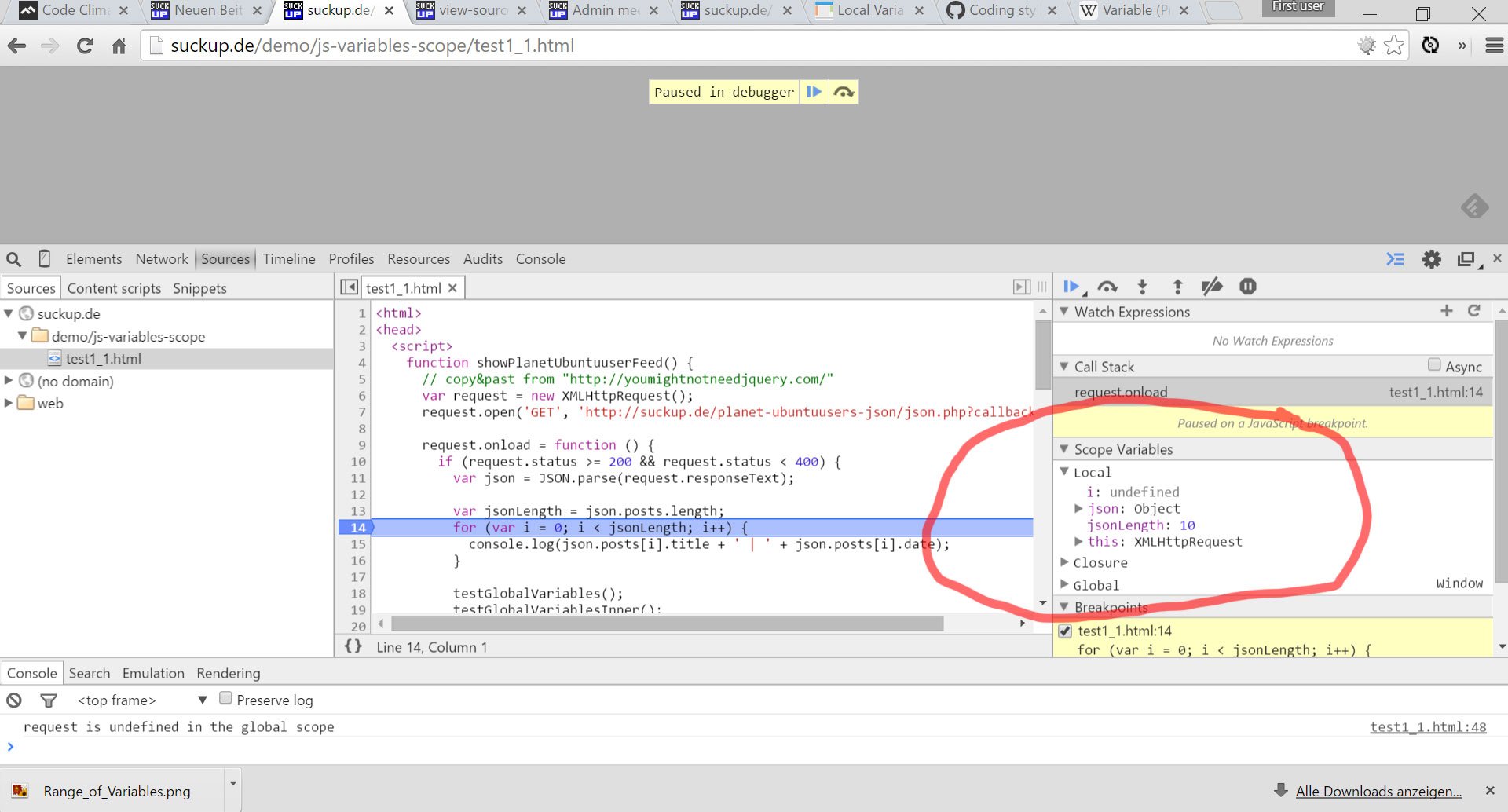
– Bitte keine globalen Variablen verwenden!
Globale Variablen erschweren das Testen, da diese Seiteneffekte verursachen können. Außerdem kann man Quelltext mit globalen Variablen nur schwer refactoren, da man nicht weiß welche Effekte diese Änderungen auf andere Teile des Systems haben.
In einigen Programmiersprachen (z.B. JavaScript, Shell) sind alle Variablen global und werden erst durch eine bestimmtes Schlüsselwort lokal (z.B. im Scope einer Funktion oder einer Klasse).
Admin meets Frontend
– Lerne deine Werkzeuge richtig einzusetzen!
Wenn man z.B. mit Notepad Quelltext schreibt kann man auch mit einem Löffel ein Loch graben, denn dies ist ähnlich effizient. Lerne Tastatur-Shortcuts für deine Programme und dein Betriebssystem! Nutze eine IDE z.B. von JetBrains (https://www.jetbrains.com/products.html) und nutze zusätzliche Plugins und Einstellungen.
Moderne IDEs geben auch Hinweise / Vorschläge, wie man seinen Code verbessern kann. Für PHP kann man z.B. PhpStorm + Php Inspections (EA Extended) einsetzten und die globalen IDE- Inspections-Einstellungen im Team teilen.
– Performance?
In vielen Situationen muss man sich um die Performance gar nicht so viele Gedanken machen, da uns dabei moderne Programmiersprachen / Frameworks unterstützen und mit einem gesunden Menschenverstand kann man bereits vieles abschätzen, ansonsten heißt die Devise „Profiling, Profiling… Profiling“!
– Exceptions === Ausnahmen
Man sollte Ausnahmebehandlungen niemals zur Behandlung normaler (d.h. häufig auftretender) Fehler einsetzen. Ausnahmen sind Ausnahmen und sollten aus Ausnahmen bleiben. Regulärer Code behandelt die regulären Fälle! „Verwenden Sie Ausnahmen nur ausnahmsweise“ (Pragmatische Programmierer). Und auf keinen Fall sollte man Ausnahmen “abwürgen”, z.B. durch triviale Abfangen mehreren Exceptions.
– Führe deine Arbeit zu Ende
Man sollte in einer Funktion zu Ende führen, was man begonnen hat. So sollte man z.B. „fopen()“ und „fclose()“ immer in einem Code-Block (Methode || Funktion) nutzen, weil man ansonsten darauf vertrauen müsste, dass jemand anders die entsprechende Ressourcen wieder frei gibt.
– Quelltext sollte durchsuchbar sein [Strg + F] …
Der Quelltext sollte einfach zu durchsuchen sein, daher sollte man z.B. auf String-Nesting + „&” bei Sass verzichten und auch bei PHP-Funktionen wie “extract()” vermeiden. Immer wenn Variablen nicht deklariert, sondern wie von Zauberhand (z.B.: bei PHP durch Magic-Methoden) erzeugt werden, kann man den Quelltext anschließend nicht mehr so einfach ändern.
Beispiel in PHP: (schlecht)
extract(array('bar' => 'bar', 'lall' => 1));
var_dump($bar); // string 'bar' (length=3)
Beispiel in Sass: (schlecht)
.teaser {
font-size: 12px;
&__link {
color: rgb(210,210,22);
}
}
Sass Nesting (Code-Style): https://github.com/grvcoelho/css#nesting
– Programmiere für deinen Use-Case!
Ein großes Problem in der Programmierung ist, dass man versuchen muss generalisiert zu denken und zu programmieren, so dass man den Quelltext entsprechende (einfach) erweitern kann, wenn neue Anforderungen hinzukommen bzw. auch (einfach) ändern kann.
Wie sehen IT-Projekte manchmal aus? → Ein Kunde bestellt bei einem Bauernhof 10.000 grüne Äpfel, ändert seine Bestellung am morgen vor der Lieferung auf 10.000 rote Äpfel und als diese geliefert werden möchte der Kunde aber doch lieber 10.000 Birnen und möchte diese gerne erst in 6 Monaten bezahlen.
Und gerade aus diesem Grund sollte man nur den Quelltext schreiben, der wirklich für den aktuellen Use-Case benötigt ist, denn alle Eventualitäten kann man sowieso nicht abbilden und der Quelltext wird unnötig verkompliziert.
– KISS – Keep it simple, stupid.
Man sollte immer beachten, dass der Quelltext selber gar nicht so viel Wert besitzt. Der Wert entsteht erst dadurch, dass andere Entwickler diesen verstehen und für den Kunden oder sich selbst anpassen / konfigurieren / nutzen können. Dies sollte man während der Programmierung im Hinterkopf behalten, so dass man eine Lösung möglichst nachvollziehbar und „einfach“ implementiert. Und wenn ich keine neue Klasse oder schönes Design-Pattern für das aktuelle Problem verwenden muss, sollte ich dies ggf. auch nicht tun. Was jedoch auch nicht heißt, dass man alle guten Absichten über Board werfen und überall global Variablen / Singletons einsetzten sollte. Wenn jedoch eine einfache Lösung die Aufgabe bereits erfüllt, entscheide dich für diese.
Ein gutes Beispiel wie man es nicht machen sollte, stellt die JavaScript Dom Selector API da. Nicht gerade schön zu lesen oder zu schreiben …
Schlecht: (DOM Selector via JS)
document.getElementsByTagName("div")
document.getElementById("foo")
document.getElementsByClassName("bar")
document.querySelector(".foo")
document.querySelectorAll("div.bar")
Besser: (DOM Selector via jQuery)
$("div")
$("#foo")
$(".bar")
$(".foo")
$("div.bar")
(Ich weiß welche Schreibweise ich bevorzugen würde!)
– DRY – Don’t Reapeat Yourself.
Wiederholungen / Redundanzen im Quelltext oder auch in wiederkehrenden Arbeiten, entsteht relativ schnell wenn die Leute z.B. nicht miteinander kommunizieren. Aber auch unbeabsichtigt durch Fehler im Software-Entwurf, weil man es gerade keine bessere Idee hat oder meint dafür keine Zeit zu haben.

Um Wiederholungen zu vermeiden, sollte man den Quelltext bzw. den Task so ablegen, dass dieser einfach zu finden und einfach wiederzuverwenden ist, denn wenn es nicht einfach zu verwenden ist, werden die Leute es nicht nutzen.
– Der Wille etwas neues zu lernen und zu verstehen ist wichtiger als Vorkenntnisse.
Wenn man bereits z.B. ActionScript (Flash) programmieren kann, aber nicht willens ist etwas neues zu lernen dann bringt einem das vorherige Wissen nichts, denn „Die einzige Konstante im Universum ist die Veränderung.“ – Heraklit von Ephesus (etwa 540 – 480 v. Chr.)
– Lese gute Bücher und Zeitschriften.
Habe mir letztes Jahr das Ziel gesetzt mehr Fachbücher zu lesen. Dafür habe ich mir folgendes auferlegt: bevor ich ein “normales” Buch lesen darf, muss ich ein Fachbuch lesen und anschließend darf ich erst ein normales lesen …
Bücher die ich gelsen habe: https://www.goodreads.com/user/show/3949219-lars-moelleken
Free Books: https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
Bücher für Programmierer: http://stackoverflow.com/questions/1711/what-is-the-single-most-influential-book-every-programmer-should-read
– Infos: folge anderen Programmieren auf Twitter / Github / Google+ / Medium / Pocket …
http://programmers.stackexchange.com/questions/135/as-a-software-engineer-who-should-i-be-following-on-twitter
– Infos: höre Podcast & abonniere RSS-Feeds / Newsletter & schaue Videos z.B. von Web-Konferenzen
Um sich über neue Technologien, Techniken, Standards, Pattern etc. zu informieren nutzt man am besten verschiedene Medien, welche man in unterschiedlichen Situationen konsumieren kann. Ein interessanten Podcast zum Thema “Frontend Architektur” vor dem einschlafen oder ein Video zum Thema “DevOp” beim zubereiten vom Mittagessen, morgens in der Straßenbahn ein Buch lesen mit dem Titel “Weniger schlecht programmieren” … um nur ein paar Beispiele zu nennen.
Podcasts: https://github.com/voku/awesome-web/blob/master/README.md#-audio-podcast
Newsletter: https://github.com/Freizeitler/Awesome-WebDev-Newsletters
github is awesome: https://github.com/sindresorhus/awesome
and there is more: https://github.com/jnv/lists
– Besuche Meetup’s & Web-Konferenzen und rede mit anderen Entwicklern.
Meetup’s sind Gruppen von Leuten die sich regelmäßig treffen und über z.B. Python, Scala, PHP, etc. austauschen. Meistens hält jemand einen Vortrag zu einem vorher abgestimmten Thema.
-> http://www.meetup.com/de-DE/members/136733532/
Web-Konferenzen machen Spaß. Punkt. Und jeder Entwickler / Administrator sollte diese besuchen, da man neue Eindrücke gewinnt und wirklich gute Leute trifft. Einige Konferenzen sind wirklich teuer, aber hier sollte man sich an seinen Arbeitgeber wenden, ggf. wird dies von der Firma übernommen. Außerdem gibt es auch wirklich günstige Konferenzen.
– Schreibe Antworten bei quora.com || stackoverflow.com || in Foren || deinem Blog …
Um sich selber mit einer bestimmten Thematik auseinander zu setzten und
wirklich zu verstehen, lohnt es sich zu recherchieren und einen Text (ggf. sogar einen Vortrag) zu verfassen, welchen andere lesen und kritisieren und somit verbessern können.
– Bleib nicht jeden Tag so lange auf der Arbeit, ansonsten wartet Zuhause irgendwann keiner mehr auf dich!!!
Bei all der Begeisterung für den “Job” (auch wenn es Spaß macht) sollte man die wirklich wichtigen Dinge nicht aus den Augen verlieren. Wieder etwas was ich auf die hart Tour lernen musste. :/





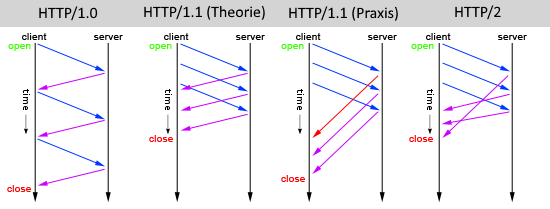
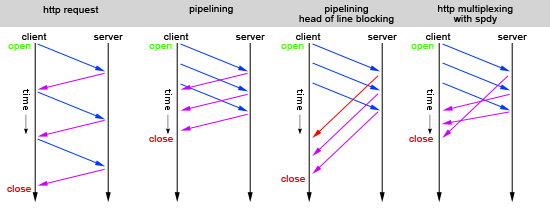
 ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.
ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.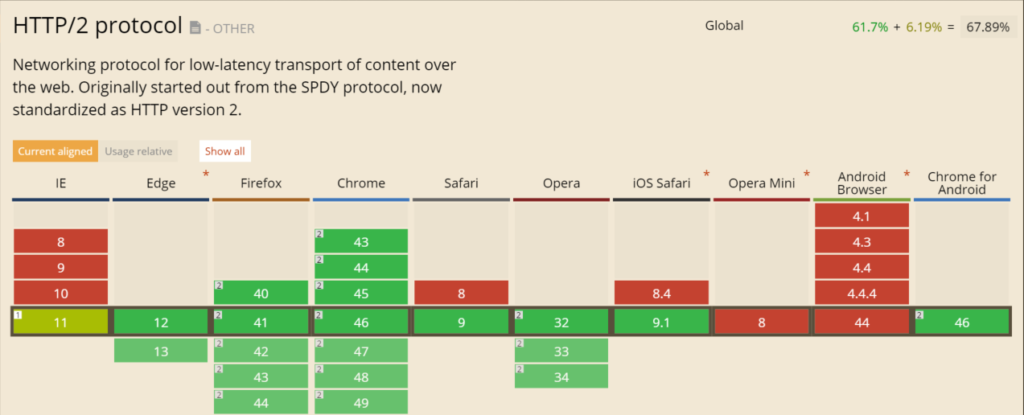

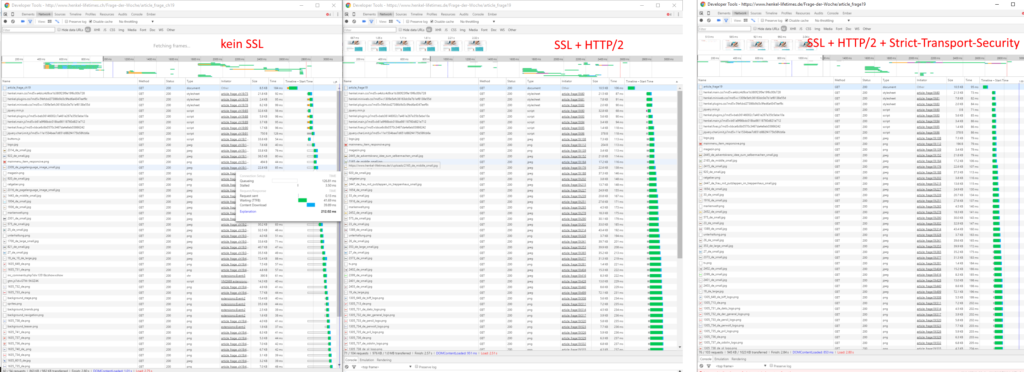


![[Update] Top Chrome Erweiterungen für Webdeveloper](http://suckup.de/wp-content/uploads//2010/11/google-chrome.jpg)