Ionic ist ein Frontend-Framework, mit welchem man via HTML5 / JavaScript und CSS native Apps bauen kann. Diese Apps können via “Apache Cordova” auf native Funktionen (Kamera, GPS, etc.) der Geräte zugreifen. Zudem wird Google’s JavaScript Framework “AnguarJS” genutzt und natürlich wird auch “SASS” unterstützt.
Vorbereitung
Man kann Multi-Platform Mobile Apps sowohl unter Windows, Linux oder Mac OS X entwickeln, jedoch ist die Vorbereitung unter Linux / Mac OS X um einiges einfacher.
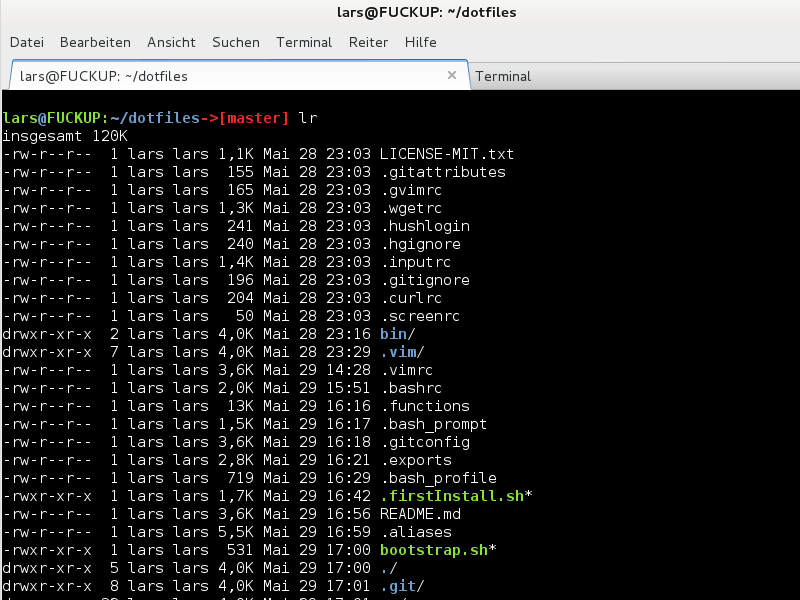
Ich empfehle an dieser Stelle mal wieder die “.dotfiles” zu installieren.
cd ~
git clone https://github.com/voku/dotfiles.git
cd dotfiles
source bootstrap.sh
Man kann die App nun im Browser (ionic serve), im Android Emulator (ionic emulate android) oder direkt auf seinem Android-Gerät (ionic run android) ausprobieren!!!
Links
Es folgen ein paar Links zur App / API / Dokumentation und zum Beispiel-Quellcode
Man kann über proprietäre Software denken was man will aber wenn Software wirklich gut ist und einem die Arbeit erleichtert / beschleunigt solle man sich diese zumindest einmal anschauen.
Installation
Es gibt unterschiedliche Wege Sublime Text zu installieren. Man kann das Paket direkt von der entsprechenden Webseite laden und mit folgendem Befehl installieren.
An dieser Stelle wollte ich einmal notieren wie ich in der täglichen Arbeit mit z.B. “grep” oder “find” etc. umgehe, um möglichst schnell in Verzeichnissen und Dateien zu suchen oder Text zu ersetzten.
Ich werde hier nicht alle Möglichkeiten der entsprechenden Befehle nennen können, daher beschränke ich mich auf das, was ich wirklich verwende. Falls du dich weiter in der Thematik einlesen möchtest, empfehle ich gerne den “man”-Befehl oder wie andere es ausdrücken RTFM!
Falls dir die Begriffe tail, cat, less nicht viel sagen, dann klick hier!!!
grep:
global regular expression print -> durchsucht Dateien und Verzeichnisse via RegEx bzw. nach Strings
Kurzform
Langform
Beschreibung
-H
--with-filename
gibt den Dateinamen vor jedem Treffer aus.
-i
--ignore-case
unterscheide nicht zwischen Groß- und Kleinschreibung.
-n
--line-number
gibt die Zeilennummer vor jedem Treffer aus.
-R
-r
--recursive
liest alle Dateien unter jedem Verzeichnis rekursiv.
-v
--invert-match
Invertiert die Suche und liefert alle Zeilen die nicht auf das gesuchte Muster passen.
z.B.:
grep -rHn test ~/php/
-> sucht im Verzeichnis “php”, welches sich wiederum im Home-Verzeichnis [~] befindet nach dem String “test”
PS: hier der selbe Befehl, jedoch eingeschränkt auf php-Dateien
grep -Hn test ~/php/**/*.php
Info: wenn man “git” im Einsatz hat, sollte man “git grep” verwenden ;)
ack:
Ack hat die selbe Aufgabe wie “grep” ist jedoch auf Entwickler zugeschnitten, so sucht “ack” im Standardmäßig rekursiv, ignoriert Binärdaten und Verzeichnisse von Versionkontrollsystemen (.svn, .git, etc.)
PS: unter Debian / Ubuntu findet man das entsprechende Paket unter “ack-grep”
find:
ist bei der Suche nach Dateien behilflich (“Alles ist eine Datei”)
Suchkriterien für find
Kriterium
Beschreibung
-name Datei
Es wird nach Dateien mit dem Namen “Datei” gesucht. Sollen bei der Suche Platzhalter Verwendung finden, so muss der ganze Ausdruck in Anführungszeichen gestellt werden, zum Beispiel
-name "*.txt"
-iname Datei
Es wird nach Dateien mit dem Namen “Datei” – ohne Beachtung der Groß und Kleinschreibung – gesucht.
-type f
Es wird nur nach regulären Dateien gesucht.
-type d
Es wird nur nach Verzeichnissen gesucht.
find -size +10M -20M -exec ls -lah {} \;
-> sucht alle Dateien welche eine Dateigröße zwischen 10 – 20 MB haben und zeigt diese an
WARNING: der “exec”-Parameter kann auch für jeden anderen Befehl auf die Ergebnismenge von “find” ausführen, dabei sollte man jedoch bei dem “rm”-Befehl besonders vorsichtig sein. Und ggf. kann man sich safe-rm anschauen. ;)
“sudo updatedb” nicht vergessen und schon kann man sehr schnell nach Dateien suchen, da die Dateien nicht im Filesystem, sondern in einer Datenbank (updatedb) gesucht werden.
z.B.:
locate Download | grep home
sed:
Es handelt sich hier um einen “nicht-interaktiver Texteditor” was eigentlich nur bedeutet, dass man damit String verarbeite kann. Zum Bespiel kann man ein bestimmtes Wort in einer Datei durch ein anderes ersetzten.
# WARNING -> replace: changes multiple files at once
replace()
{
if [ $3 ]; then
find $1 -type f -exec sed -i 's/$2/$3/g' {} \;
else
echo "Missing argument"
fi
}
replace *.php alt neu
-> dieser Befehl such im aktuellen (+ Unterverzeichnisse) nach Dateien, welche auf “.php” enden und ersetzt darin “alt” gegen “neu”
Dabei ist besonders praktisch, dass man diese Funktionalität auch im “vim” verwenden kann indem man z.B. folgendes eingibt …
:%s/alt/neu/g
diff:
Wie der Name schon vermuten lässt, kann man hiermit Dateien vergleichen. z.B.:
diff -u --ignore-all-space -r old/ new/
-> vergleicht alle Dateien rekursiv (-r) vom Verzeichnis “old/” und “new/” und ignoriert dabei Änderungen vom Leerräumen z.B. Leerzeichen oder Zeilenumbrüche (\r <-> \r\n)
Info: wenn man “git” im Einsatz hat, sollte man “git diff” verwenden ;)
wc:
word count kann Wörtern, Zeichen und Bytes (man ahnt es bereits) zählen. z.B.:
Habe soeben einen älteren Blog-Post aktualisiert und einen kleinen Tipp hinzugefügt, welchen ich hier an zwei Beispielen zeigen möchte: suckup.de/linux/ubuntu/aptitude-dpkg/
sudo aptitude search "^php5-[a-cA-C]+"
-> sucht alle Pakete welche mit “php5-” anfangen und darauf “a”, “b oder “c” in beliebiger Häufigkeit folgen
sudo aptitude search "(^bash|^git).*completion"
-> sucht Pakete welche entweder mit “bash” oder mit “git” anfangen gefolgt von beliebigen (auch beliebige Anzahl) von Zeichen, gefolgt von dem String “completion”
Die RegEx-Funktionalität funktioniert sowohl bei “apt-cache”, “apt-get” als auch bei “aptitude” und auch bei anderen Befehlen wie z.B.: “remove”, “install”, “search”, “purge” etc. Bei meinen Tests hat dies jedoch mit “aptitude” am besten funktioniert, da hier nur nach den Paketnamen gesucht wird, falls man jedoch nicht genau weiß wonach man eigentlich sucht, dann sollte man es wohl mit “apt-cache” versuchen.
PS: wer sich RegEx noch nicht angeschaut hat, der sollte auch mal die Links in den Quellen anklicken, da man dies z.B. in so gut wie jeder Programmiersprache, in der Shell oder ansatzweise selbst bei der Google-Suche nutzen kann. Wer mehr über Tricks in der Google-Suche erfahren möchte, klickt hier! ;)
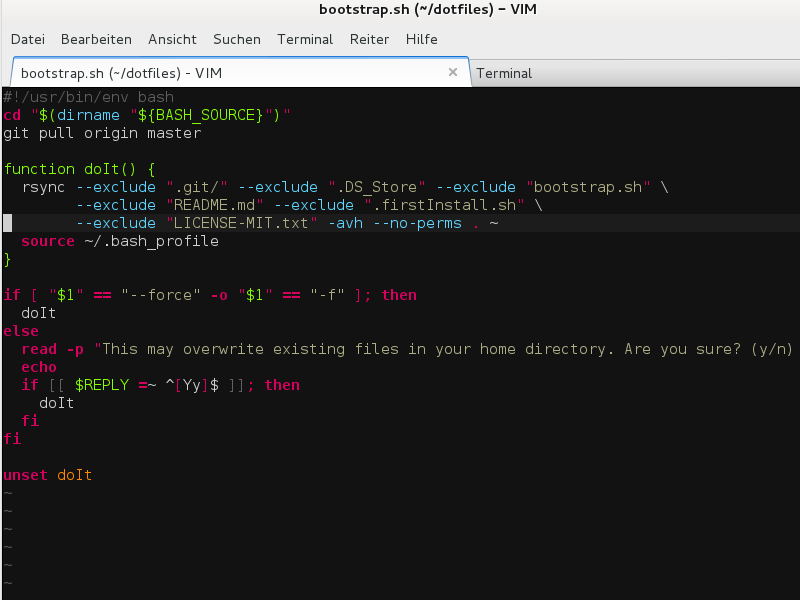
Habe meine dotfiles (Dateien im Home-Verzeichnis, welche mit einem “.” beginnen) mit anderen Quellen angereichert und diese auf github veröffentlicht. Wer möchte kann diese Einstellungen, Aliase, Funktionen für die “Linux-Shell” verwenden oder auch verbessern, indem man einen entsprechenden Fork von dem Projekt erstellt.
cd ~ && git clone https://github.com/voku/dotfiles.git && cd dotfiles && ./bootstrap.sh
… wenn gewünscht kann man mit diesem kleinen Skript entsprechende ggf. benötigte Pakete nachinstallieren:
./firstInstall.sh
Update:
./bootstrap.sh
Einstellungen:
Die Datei “~/.config_dotfiles” beinhaltet einige Einstellungen für die entsprechenden dotfiles. Wenn diese Datei nicht existiert wird diese automatisch beim ausführen der “bootstrap.sh”-Datei erzeugt.
Die Plugins sind von “bash-it“, “oh-my-zsh” und eigenen eigenen Anpassungen zusammengefügt. Außerdem wurden Plugins welche allgemeingültig sind in die globalen “.aliases” und “.functions” ausgelagert.
Wenn die Datei “~/.extra” existiert, wird diese zusammen mit den anderen Dateien verarbeitet. Man kann diese nutzen, um benutzerdefinierte Befehle ausführen zu lassen.
Vorwort: Ich arbeite in Düsseldorf bei der “menadwork GmbH” als Webentwickler und vor einigen Monaten habe ich mein Betriebssystem auf Linux (Debian) umgestellt, daher musste ich meine Toolchain / Programmierumgebung neu einrichten. Vorweg kann ich schon mal verraten, dass man sehr gut und effizient damit arbeiten kann. Nur drei, vier Programme (IE, Photoshop, Outlook, MS Office) musste ich per VIrtualBox (Win7) virtualisieren.
Im folgenden wird eine Toolchain / Programmierumgebung für Webprojekte (PHP, HTML, CSS, Sass, JavaScript) eingerichtet. Diese Anleitung werden ich im parallel für Windows und Linux beschreiben.
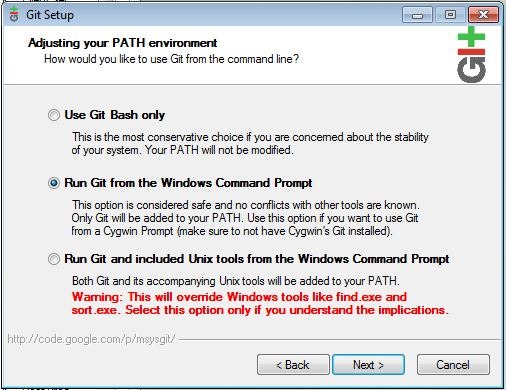
Als erstes Installieren / Konfigurieren wir “git” zur Versionskontrolle und um Quellcode von github.com laden zu können. Auch wenn du mit wenigen Leuten oder alleine an einem Projekt arbeitest ist der Einsatz von “git” sehr empfehlenswert. Da man so auch noch nach Wochen / Monaten nachvollziehen kann, warum man welche Änderung gemacht hat und diese zudem ganz einfach rückgängig machen kann.
Es wird wahrscheinlich zu Probleme (Änderung in jeder Zeile der gespeicherten Datei) bei der Zusammenarbeit von “git unter Windows” & “git unter Linux (Mac)” geben, da diese ein anderes “line ending” haben (\n bzw. \r\n). – http://git-scm.com/book/ch7-1.html#Formatting-and-Whitespace
# Windows – Diese wandelt “LF” (\n) in “CRLF” (\r\n) Endungen um, wenn der Befehl “git pull” ausgeführt wird und wandelt dies beim “git commit” wieder zurück
git config --global core.autocrlf true
# Linux (Mac) – Diese wandelt “CRLF” (\r\n) in “LF” (\n) Endungen um, wenn der Befehl “git commit” ausgeführt wird
git config --global core.autocrlf input
-> somit sind die Dateien auf dem Repository (z.B.: github oder gitlab) und in der lokalen git-history immer mit “LF” (\n) codiert.
1.2.2) “push”
git config --global push.default simple
-> der Befehl “git push” schiebt nur commits von der aktuellen “branch” zum Repository (branch mit dem selben Namen)
git config --global color.diff auto
git config --global color.ui auto
git config --global color.status auto
git config --global color.branch auto
2.) Webserver + PHP
Als Webserver installieren wir uns lokal den “Apache”-Webserver, da diese bei vielen Web-Projekten später auch im Live-System zum Einsatz kommt und wir bereits lokal Dinge wie “.htaccess“-Umleitungen etc. testen kann.
Wenn man unter Linux bzw. Mac arbeitet, sollte man den Webserver bzw. PHP so konfigurieren, dass die entsprechenden PHP-Skript-Prozesse mit dem User des Webs laufen. Dies kann man z.B. via suphp oder via php-fpm bewerkstelligen. (Quick & Dirty: die Skripte mit dem eigenen User laufen lassen und das htdocs-Verzeichnis in das eigene Home-Verzeichnis legen)
Unter Windows braucht man sich an dieser Stelle noch keine Gedanken über User-Rechte machen, jedoch spätestens wenn man das Projekte zum ersten mal auf dem Server deployed muss man diesen Schritt auf dem Server wiederholen.
Tipp: hier findet man viele Anleitungen für die Installation von Linux-Servern -> http://www.howtoforge.de/
Unter Windows (XAMPP) ist xDebug bereits vorinstalliert und muss nur noch in der “php.ini”-Datei aktiviert werden. Unter Linux befinden sich die Konfigurationen für PHP-Erweiterungen unter “/etc/php5/config.d/”.
z.B.: für Windows, wenn xampp unter “D:\xampp\” installiert ist
Als nächsten großen Schritt werden wir uns nun eine IDE installieren hier würde ich für größere PHP-Projekte “Netbeans” bzw. “PhpStorm” empfehlen, obwohl “Sublime Text” auch seine Stärken hat und jeder der das Programm noch nicht ausprobiert hat, sollte es einmal testen!!!
3.1) Konfiguration
3.1.1) Netbeans
3.1.1.1) PHPUnit
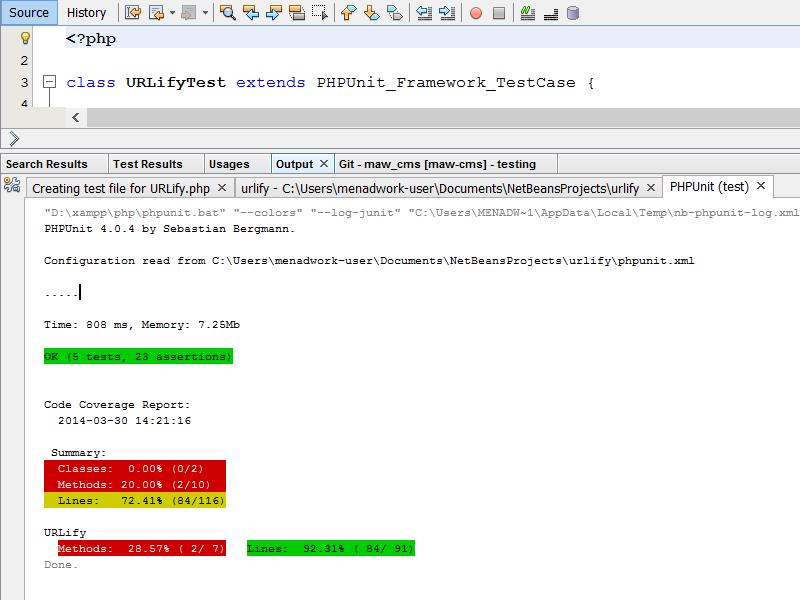
Unter den Tools -> Options -> PHP -> PHPUnit-> kann man automatisch nach dem bereits installiertem PHPUnit und dem Skeleton-Generator suchen lassen und anschließend aus jeder PHP-Klasse ein PHPUnit-Template erstellen lassen.
3.1.1.2) xDebug
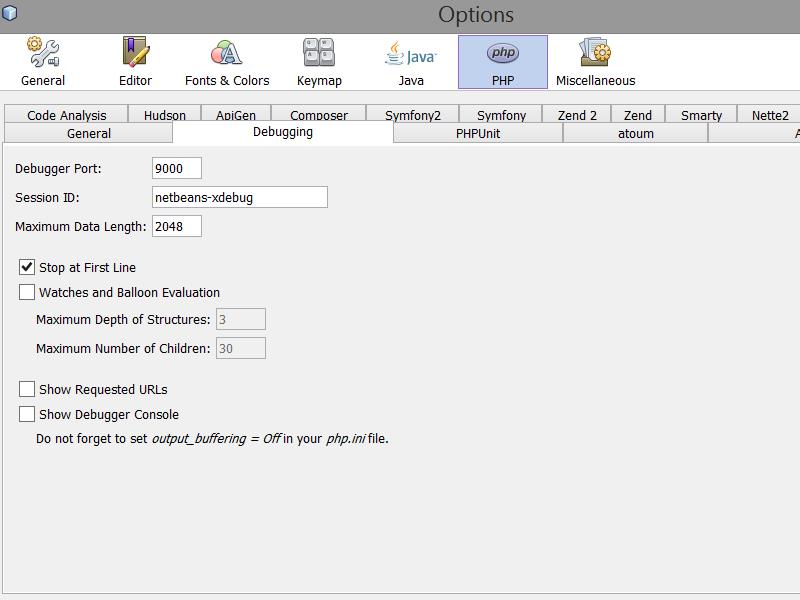
Auch dieses Tool müssen wir einmal konfigurieren unter Tools -> Options -> PHP -> Debugging
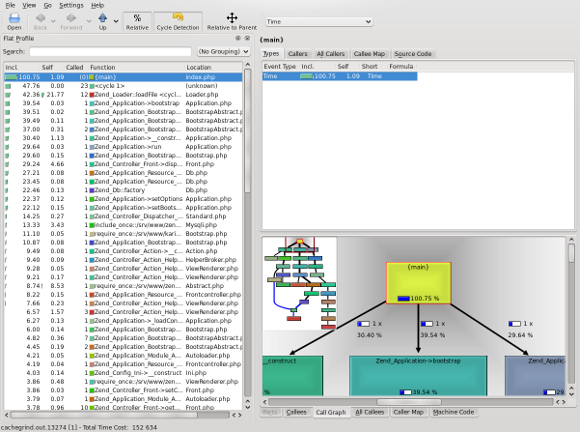
Tipp: Wir können unser PHP-Projekt nun nicht nur Debuggen, sondern auch Profilen. Indem wir den Parameter “XDEBUG_PROFILE=1” per GET oder POST übermitteln und den Output anschließend z.B.: via KCachegrind visualisieren lassen.
Auf der Webseite Packagist.org findet man alle Projekte, welche man ohne weitere Anpassungen in seinem Projekt verwenden kann und man kann seine eigenen Projekte einstellen (oder auch eigene Repositories verwenden, falls man diese nicht öffentlich machen will). z.B.: mein Profil -> packagist.org/users/voku/
4.3) Konfiguration
Man lege eine Datei mit dem Namen “composer.json” an und sucht sich seine zu installieren Bibliotheken aus, anschließend ein “composer install –optimize-autoloader” bzw. “composer update” und schon kann man die Bibliotheken verwenden (include von “vendor/composer/autoload.php” nicht vergessen).
5.) Ruby && Node.js
Bower ist auch ein Manager für externe Bibliotheken, jedoch auf JavaScript, jQuery, SASS, LESS, CSS etc. (A package manager for the web) ausgerichtet. Für die Installation muss man auch Ruby und Node.js installieren, jedoch benötigen noch andere wichtige Tools in unserer Toolchain diese Programme, daher folgt nun zuerst die kurze Installation unter Linux und die etwas ausführlichere für Windows. :P
Nachdem wir Ruby Installiert haben müssen wir noch das “DevKit” für Ruby herunterladen und in das Verzeichnis in welchem du Ruby installiert hat in das Unterverzeichnis “\DevKit” entpacken. – z.B.: “D:\xampp\Ruby200-x64\DevKit” und dann folgenden Befehl auf der Kommandozeile (ggf. muss man ruby noch zum PATH hinzufügen oder Windows mal wieder neu-starten)
ruby dk.rb init
Anschließend müssen wir die Datei “dk.rb” noch wie folgt anpassen:
# This configuration file contains the absolute path locations of all
# installed Rubies to be enhanced to work with the DevKit. This config
# file is generated by the 'ruby dk.rb init' step and may be modified
# before running the 'ruby dk.rb install' step. To include any installed
# Rubies that were not automagically discovered, simply add a line below
# the triple hyphens with the absolute path to the Ruby root directory.
#
# Example:
#
# ---
# - C:/ruby19trunk
# - C:/ruby192dev
#
---
- D:/xampp/Ruby200-x64
… und können die Installation mit folgenden Befehlen abschließen:
ruby dk.rb review
ruby dk.rb install
6.) “Bower” – bower.io
Zurück zu Bower, nachdem wir nun Ruby && Node.js installiert haben, können wir nun weiter Tools sehe einfach über die Kommandozeile via npm installieren lassen.
Sass ist ein Preprocessor für CSS, so dass man Variablen, Schleifen, Funktionen etc. in CSS nutzten kann. Große Projekte wie z.B.: Bootstrap bieten Ihren Quellcode als scss-Version an. Der Code-Style unterscheidet sich nur minimal von “normalem” CSS, wobei hier normal in Anführungszeichen stehen, da man die verschiedenen CSS-Selektoren nicht zwingend verschachteln muss. Man kann auch einfach seine bestehende CSS-Datei in eine SCSS-Datei umbenennen und per “sass” kompilieren oder eine bestehen CSS-Datei (z.B.: test.css) per “sass-convert” Konvertieren.
compass ist ein Framework, welches auf sass aufbaut und dieses um CSS3-Funktionen und z.B. automatisches erstellen und aktualisieren von CSS-Sprites bietet.
8.1) Installation
gem install compass [--pre]
Tipp: wenn man noch Browser unterstützen muss, welche keine Transparenzen via CSS (opacity) können, dann sollte man sich mal “compass-rgbapng” anschauen. Damit werden automatisch Fallback-Bilder (png’s) in der entsprechenden Farbe / Transparenz erstellt und im CSS eingebaut.
8.2) Konfiguration
Wir starten indem wir folgende Datei anlegen -> “config.rb”
# Require any additional compass plugins here.
#require "rgbapng"
#add_import_path "vendor/bower/foundation/scss/"
#add_import_path "vendor/bower/normalize-scss/"
# Set this to the root of your project when deployed:
http_path = "/"
css_dir = "css"
sass_dir = "scss"
images_dir = "images"
javascripts_dir = "js"
# You can select your preferred output style here (can be overridden via the command line):
# output_style = :expanded or :nested or :compact or :compressed
output_style = :expanded
# To enable relative paths to assets via compass helper functions. Uncomment:
# relative_assets = true
# To disable debugging comments that display the original location of your selectors. Uncomment:
# line_comments = false
line_comments = true
# If you prefer the indented syntax, you might want to regenerate this
# project again passing --syntax sass, or you can uncomment this:
# preferred_syntax = :sass
# and then run:
# sass-convert -R --from scss --to sass sass scss && rm -rf sass && mv scss sass
8.3) HowTo
Nachdem wir die Konfiguration angelegt und ggf. angepasst haben, wird mit dem folgendem Befehl automatisch (bei Änderungen) die entsprechende scss-Datei in eine css-Datei kompeliert.
Anstatt die entsprechenden CSS3-Funktionen von compass zu verwernden, erscheint es mir einfacher und Sinnvoller entsprechende Vendor-Prefixes automatisch zu erstellen und genau das macht dieses Tool! Man kann es entweder selber aufrufen, in compass oder via “grunt” (dazu kommen wir gleich) integrieren.
9.1) Installation
gem install autoprefixer-rails [--pre]
9.2.1) HowTo: Grunt + autoprefixer
(Auch wenn ich noch gar nicht zu grunt geschrieben habe, zeige ich schon mal wie, man dies nutzten kann.)
Als erstes wird das Plugin “grunt-autoprefixer” installiert und dann folgender Task in der Datei “Gruntfile.js” angelegt:
Folgendes in die compass-Konfiguration “config.rb” einfügen:
require 'autoprefixer-rails'
on_stylesheet_saved do |file|
css = File.read(file)
File.open(file, 'w') do |io|
io << AutoprefixerRails.process(css)
end
end
Grunt ist ein Task-Runner, dass heißt das Programme automatisch z.B. nach dem Speichern einer Datei ausgeführt werden können. Falls jemand das Tool noch nicht im Einsatz hat -> einfach mal Testen!!! Erst dieses Tool verknüpft alle hier vorgestellten Tools zu einer “Toolchain”. Und man ist nur noch einen Schritt davon entfernt automatisierte Tests im Browser, Live-Reload im Brower etc. zu nutzen.
Entweder man legt sich selber ein entsprechendes “Gruntfile.js” (Konfiguration) und “package.json”- Datei an oder man nutzt den Befehl:
grunt-init TEMPLATE_NAME
10.3) Video
Wie im Video erklärt wird, kann man gunt, nachdem man dies einstellt hat, mit dem Befehl “grunt watch” auf Änderungen von beliebigen Dateien, beliebige Tasks ausführen lasse. In meinem Fall lasse ich z.B. bei Änderungen von “*.scss”-Dateien diese via compass in CSS compilieren, anschließend per “autoprefixer” überarbeiten, minifizieren und zum Schluss wird automatisch ein reload von dem entsprechendem Brower-Tab durchgeführt. :)
Google hat “pagespeed” für nginx veröffentliche, die nginx Äquivalent vom “mod_pagespeed” für Apache. Dieses Modul kann die Performance von Webseiten optimieren, indem z.B. die zugehörigen Assets (CSS, JavaScript, Bilder) verkleiner bzw. kombiniert werden, um die Ladezeiten zu reduzieren. Dieses Tutorial erklärt wie nginx + pagespeed auf Debian kompiliert/installiert werden kann.
Bevor wie starten können müssen wir ggf. einige Pakete nachinstallieren und “deb-src” in der “/etc/apt/sources.list” einfügen / auskommentieren.
Wir sollten PHP-Skript nicht alle mit dem selben User-Berechtigungen (z.B. apache) laufen lassen, daher empfiehlt es sich auf kleinen Webservern suPHP und auf Webseiten mit mehr Traffic “Fast CGI” zu installieren. Alternativ kann man PHP mit “PHP-FPM” (FastCGI Process Manager) auch jeweils als eigenständigen Prozess laufen lassen.
Da einige PHP-Projekte nicht wirklich für Ihre Sicherheit bekannt sind, empfiehlt es sich zudem die “Suhosin” Erweiterung für PHP zu installieren. “Es wurde entworfen, um den Server und die Benutzer vor bekannten und unbekannten Fehlern in PHP-Anwendungen und im PHP-Kern zu schützen.” – Wiki
PS: auf der Webseite -> http://www.dotdeb.org <- findet man einfach zu installierende .deb-Pakete für Debian / Ubuntu in welchen die Suhosin-Erweiterung bereits integriert ist und liegt zudem als “php5-fpm” Version zur Verfügung. ;)
Wenn man auf seinem Android beispielsweise einen Kernel mit 24bpp Unterstützung installiert, kann man auch wenn man root-Rechte hat, keine Screenshot via App machen. Um dies zu umgehen kann man die “Android Debug Bridge (adb)” verwenden.
In dem “CyanogenMod” (CM) ist bereits ein SSH-Server eingebaut (Dropbear), dieser ist jedoch standardmäßig abgeschaltet. Hier zeige ich kurz wie du diesen unter Linux / Windows nutzen kannst und dich somit ohne Kabel mit deinem Android (funktioniert nach meinen Tests, nur im lokalen W-Lan) verbinden kannst … ;-)
Klick auf “Generate” und füge die Zeichenkette, welche du nun im Fenster von puttygen siehst (Beispiel: “ssh-rsa AAAAB3…hclQ==rsa-key-20100227”) in eine Text-Datei auf deinem Desktop ein -> “id_rsa.pub” und speichere (beschütze) deinen “private key”!!!
2.2.3) Übertrage den SSH-Schlüssel (öffentlich / public) zu Android
In order to optimize the website and to continuously improve it, this site uses cookies. By continuing to use the website, you consent to the use of cookies.