Die Fernsehserie folgt einem jungen Programmierer (Elliot), der von dem mysteriösen Mr. Robot für eine Hackergruppe rekrutiert wird und wer die Serie bisher noch nicht geschaut hat, sollte dies nachholen.
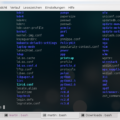
In Folge 1 muss Elliot einen Rootkit ausfindig machen, viel mehr werde ich an dieser Stelle nicht vorwegnehmen. Viele der folgenden Befehle sind nicht ohne weiteres auf jedem Linux System auszuführen oder es gibt diese gar nicht. Jedoch versteht bzw. sieht man was diese bewirken sollen.
1. Status

Um das Problem vom Büro aus zu analysieren, werden zunächst Netzwerk und Dienste geprüft.
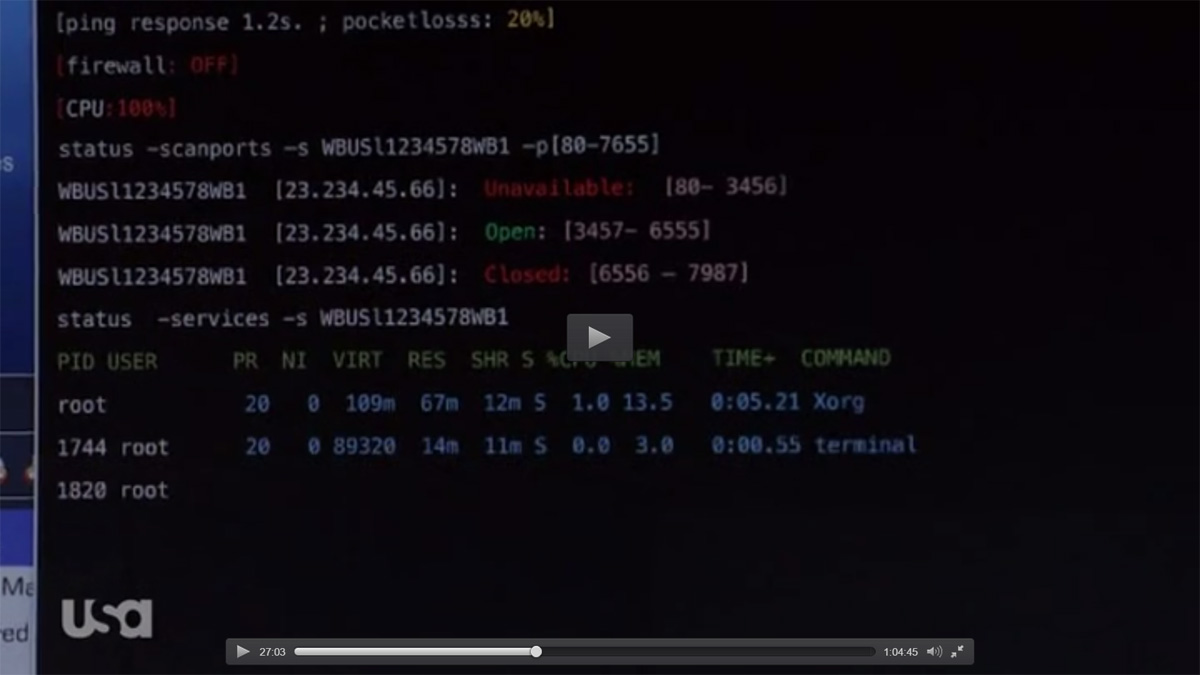
status -scanports -s WBUSl12345678WB1 -p[80-7655]
Hier hat Elliot sich anscheinend eine Shell-Funktion geschrieben, welche einen Portscan auf der Server “WBUSl12345678WB1” mit der Port-Range 80 bis 7655 durchführt.
Der folgender Befehl würde wirklich funktionieren.
nmap WBUSl12345678WB1 -p80-7655
Als nächstes wird anscheinend geprüft welche Prozesse momentan auf dem Remote-Server ausgeführt werden.
status -services -s WBUSl12345678WB1
Dies könnte auch eine selbst programmiere Shell-Funktion sein, welche sich auf dem Remote-Server einloggt und die Prozesse z.B. via “ps aux” auflistet.
ssh user@WBUSl12345678WB1 ‘ps aux’
Resultat: Die Services sind nicht mehr erreichbar und anscheinend läuft auf dem Server ein Xorg. ;) Da der Fehler nicht einzugrenzen ist, wird Elliot (mit dem Jet) zum Rechenzentrum geflogen, um den infizierten Server zu lokalisieren und zu isolieren. *freu*
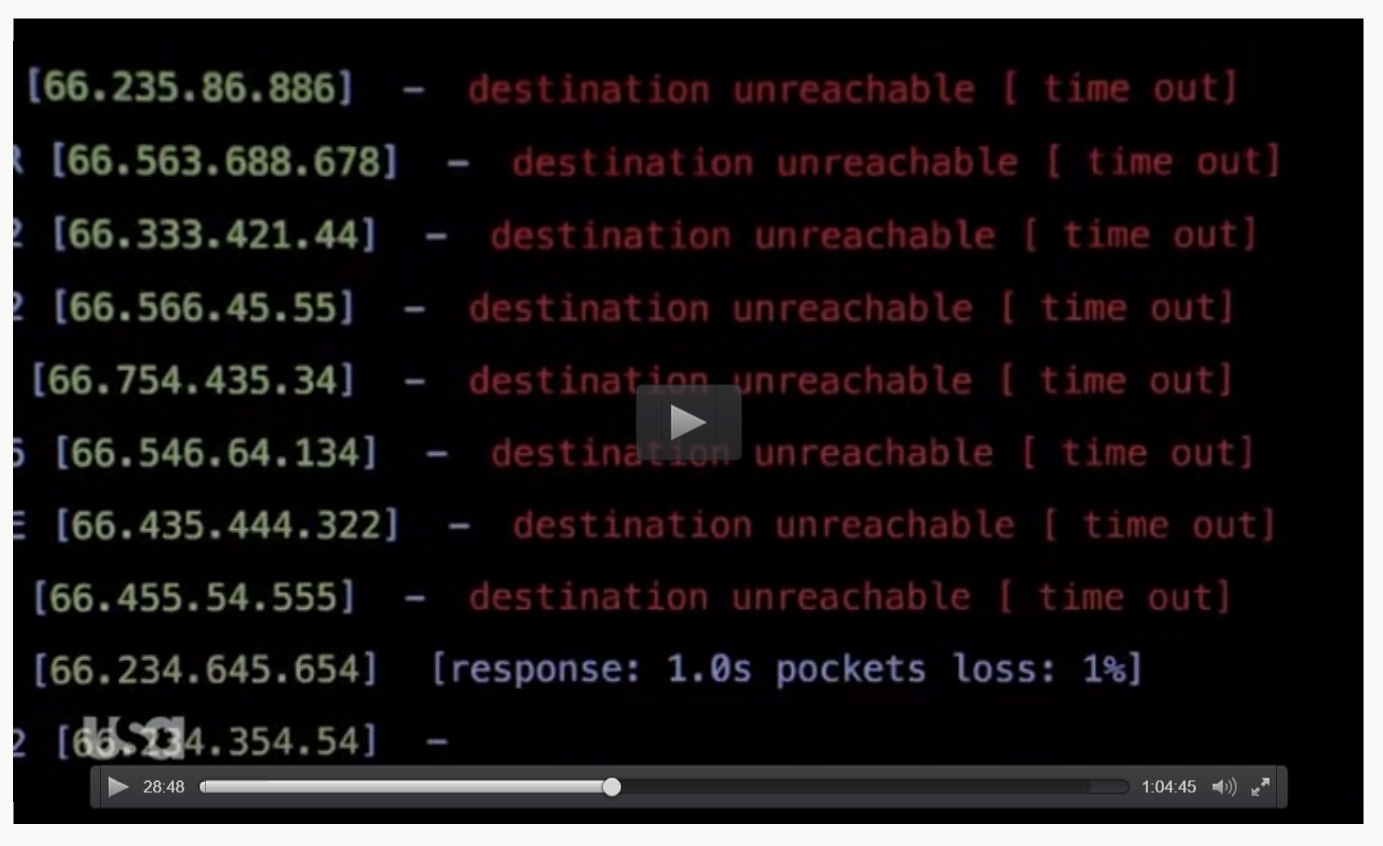
2. Ping

Der Befehl selbst ist in der Sequenz nicht zu sehen aber dies könnte so ähnlich aussehen.
fping -g 194.122.82.0/24
Resultat: Ein Server ist noch aktiv, dies muss der Übeltäter sein …
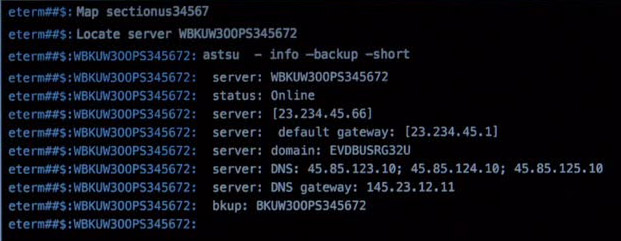
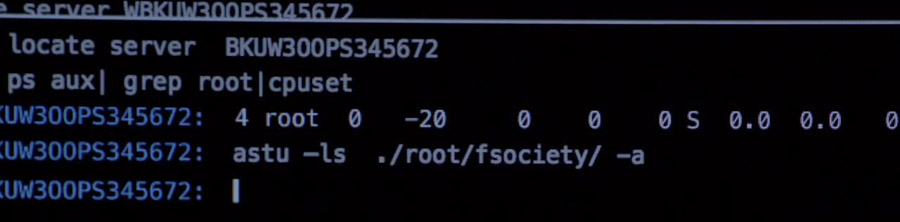
3. Locate WBKUW300PS345672

Der gehackte Server soll in der nächsten Szene manuell durch den Backup-Server ersetzt werden. Es wird der Befehl “Locate” ausgeführt, um sich zunächst an dem gehacktem Server anzumelden.
Der “locate” Befehl ist eigentlich zum suchen von Dateien gedacht, aber diese wird ja auch klein geschrieben.
4. astsu
Hier wird außerdem der fiktive Befehl “astsu” ausgeführt, um Informationen vom Netzwerk-Informationen vom Server zu erhalten.
Folgende Befehle funktionieren tatsächlich…
DNS:
cat /etc/resolv.conf
IP:
ifconfig
ROUTING:
route

In der nächsten Szene sehen wir sowohl die vorherigen aus auch die nächsten Befehle welche auf der Konsole eingegeben wurden.
astsu -close port: * -persistent
Und wie wir sehen übernimmt der Befehl “astsu” auch noch die Funktionalität von “iptables“. ;)
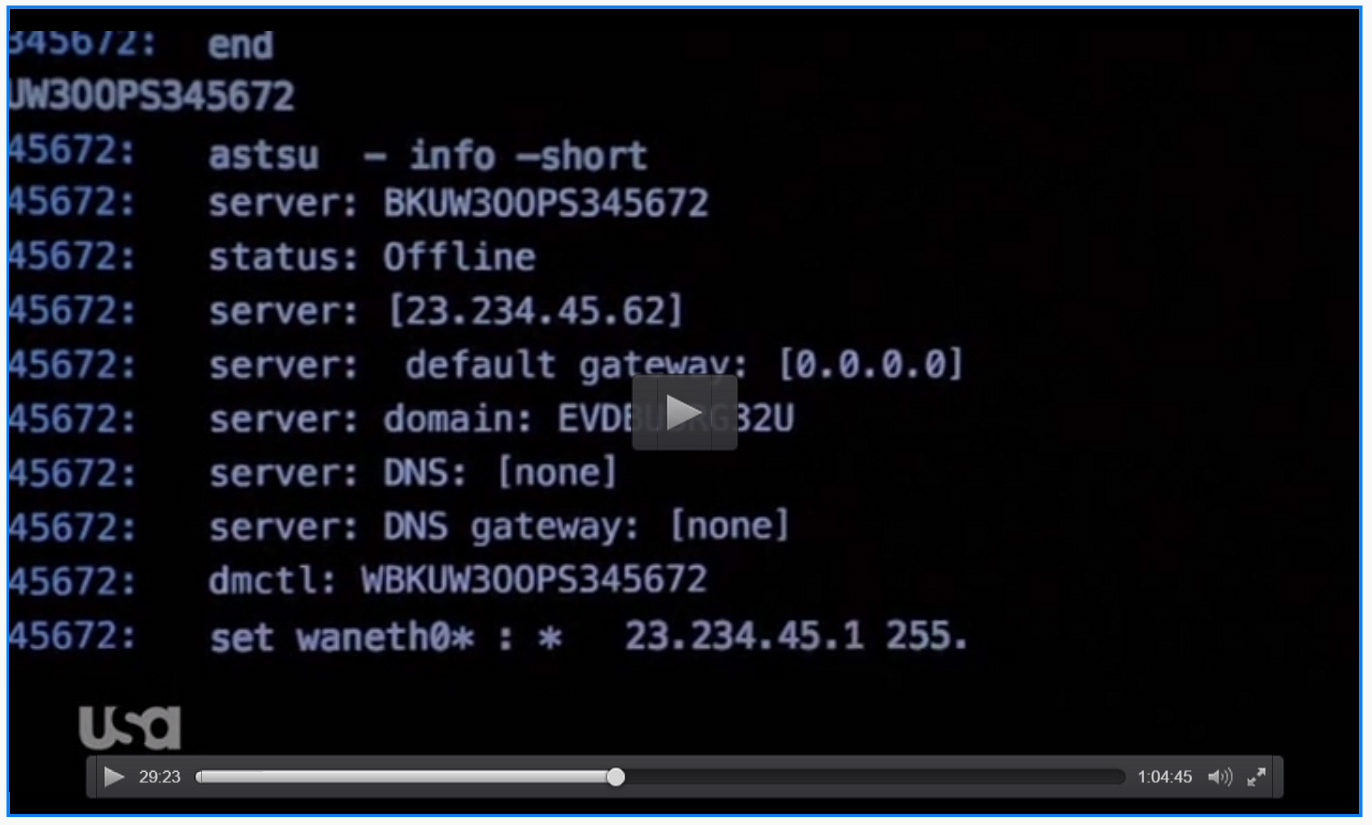
Locate BKUW300PS345672
Hier kommt nocheinmal der “Locate” Befehl zum Einsatz, um sich auf den Backup-Server einzuloggen.

set waneth0* : * 23.234.45.1 255.255.255.0 [45.85.123.10; 45.85.124.10; 45.85.125.10]
Im Output kann man ein “false” sehen, aber Elliot verwendet “-force” um dieses Problem zu lösen. Natürlich ist auch diese Befehl ausgedacht, aber viele andere Linux Kommandos akzepieren ebenfalls einen “–force” Parameter, daher ist dies gar nicht so abwegig.
set -force -ovr02 waneth04 : 23.234.45.62:441 23.234.45.1 255.255.255.0 [45.85.123.10; 45.85.124.10;
Um die IP-Adresse wirklich zu konfigurieren kann man z.B. “ifconfig & route” oder “ip” verwenden.
ip addr add 45.85.123.10/24 dev eth0
ip addr add 45.85.124.10/24 dev eth0
ip addr add 45.85.125.10/24 dev eth0
ip route add default via 23.234.45.1
Resultat: Der gehacket Server ist offline und der Backup-Server hat dessen Funktion übernommen.
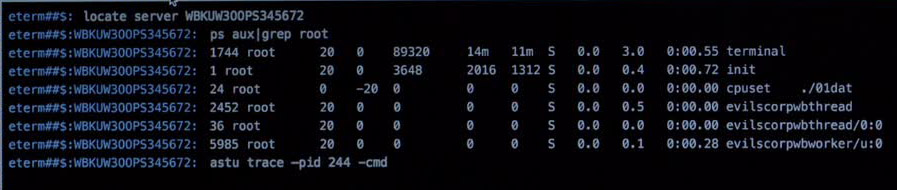
5. ps aux | grep root

ps aux | grep root
Nachdem die Gefahr gebannt ist, schau Elliot sich den gehackten Server noch einmal genauer an und findet einen Prozess (pid: 24) welcher mit höchster Priorität (-20) läuft.
astu trace -pid 244 -cmd
Hier tauch eine abgewandelte Version vom fiktiven Befehl “astsu” auf, warum die pid 244 und nicht die 24 weiter untersucht wird, bleibt ungeklärt.
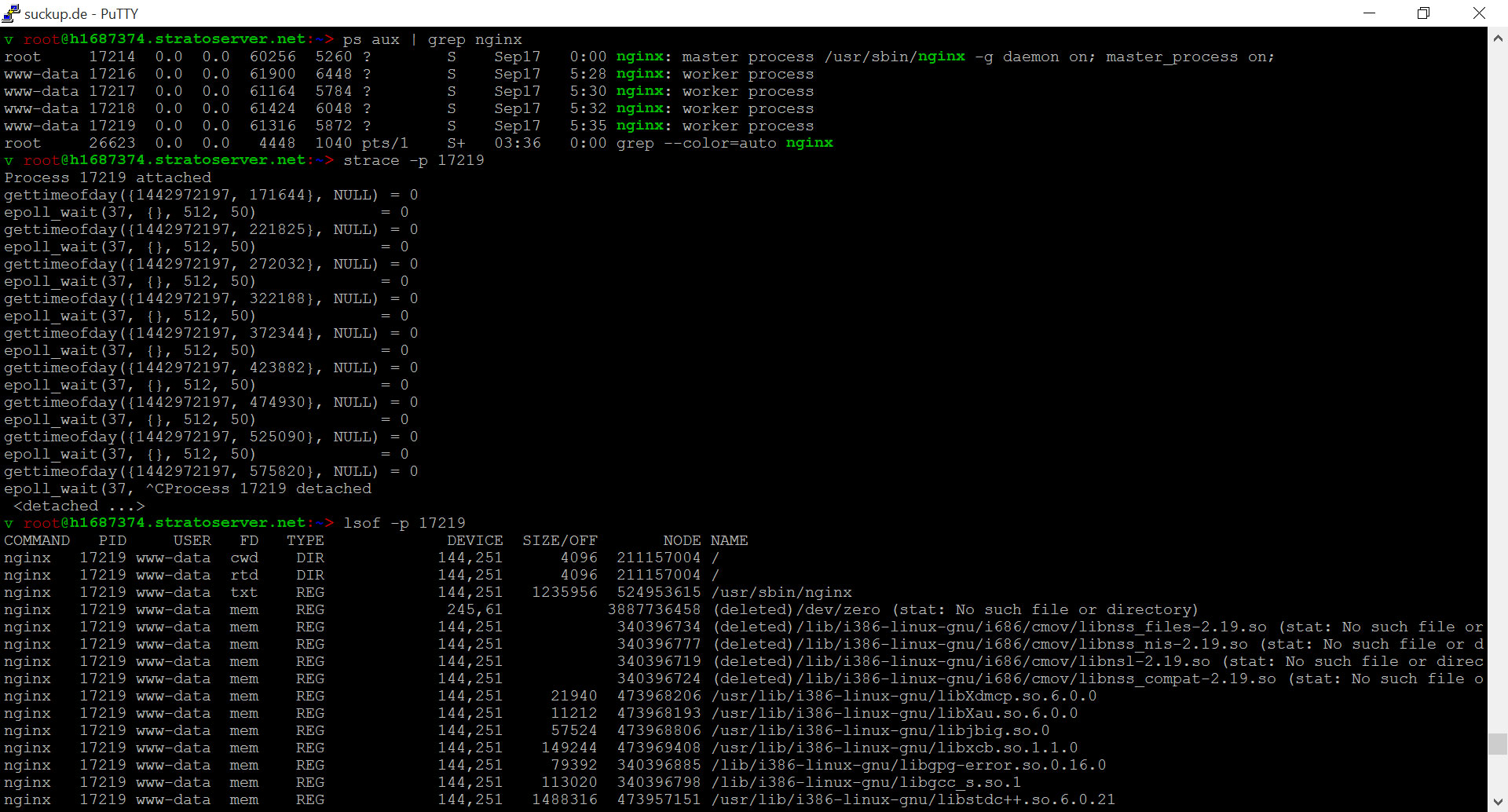
Um einen Prozess tatsächlich näher zu untersuch, würde ich zunächst folgende Befehle nutzen.
strace -p 24
lsof -p 24

Beispiel für “strace” & “lsof”
6. ps aux | grep root | cpuset

ps aux| grep root | cpuset
“cpuset” würde hier nicht funktionieren und ich bin mir nicht ganz sicher was “cpuset” überhaupt macht?!
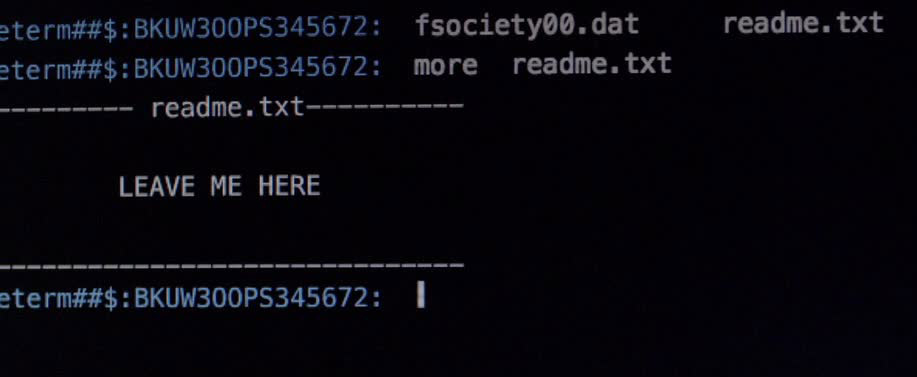
astu -ls ./root/fsociety/ -a
Nun wird der Inhalt vom Verzeichnis “/root/fsociety/” angezeigt, folgender Befehl würde funktionieren.
ls -la /root/fsociety/

Elliot schau sich nun die README Datei der Hacker an und möchte den Rootkit zunächst im folgenden löschen.
more readme.txt
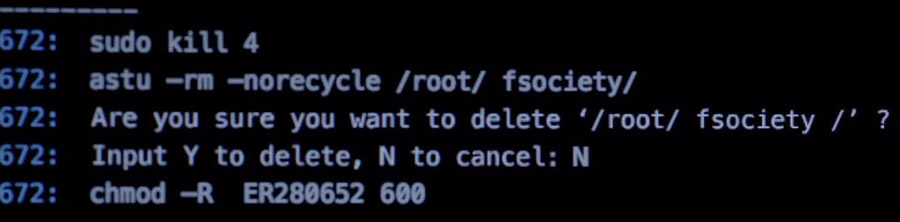
astu -rm -norecycle /root/ fsociety/
Um das Verzeichnis wirklich zu löschen, müsste der folgende Befehl ausgeführt werden.
rm -rf /root/fsociety/

Aber er entscheidet sich dagegen und ändert stattdessen die Berechtigungen der Datei, so dass nur noch er selber Zugriff darauf hat.
chmod -R ER280652 600
Auch dieser Befehl wird so nicht funktionieren, da man “chmod” und “chown” unterscheidet. Folgende Befehle würden funktionieren.
chmod -R 600 /root/fsociety/
chown -R ER280652 /root/fsociety/
Resultat: Der ursprüngliche Server ist offline, der Backup-Server ist online und der Rootkit ist noch immer im System.
Fazit: echo “Ich mag diese Serie.” | sed ‘s/Serie/Nerd-Serie/’







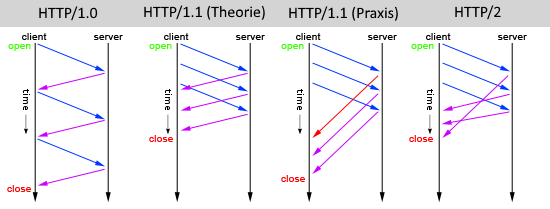
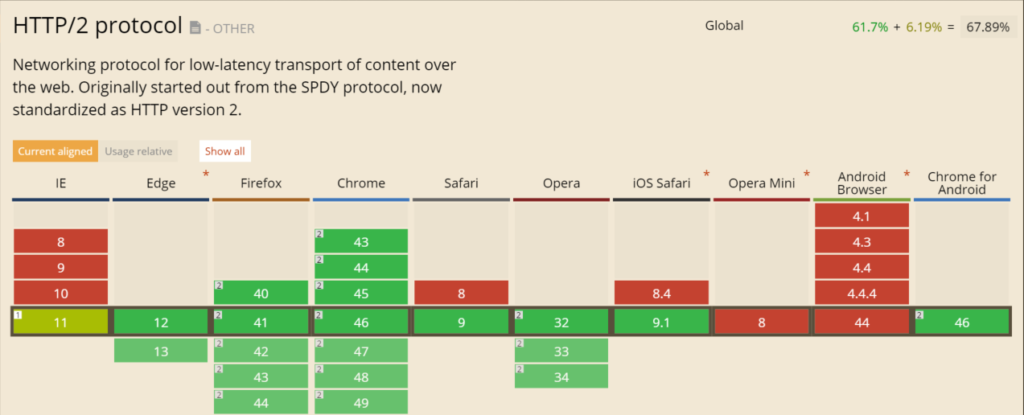
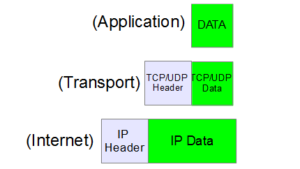
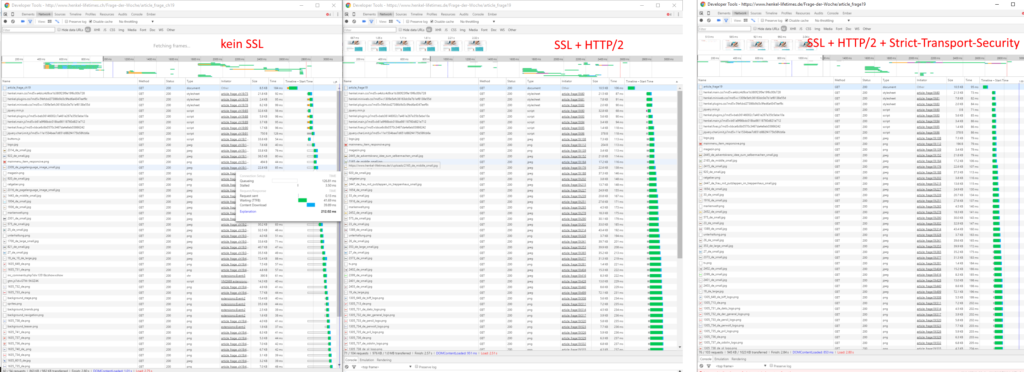
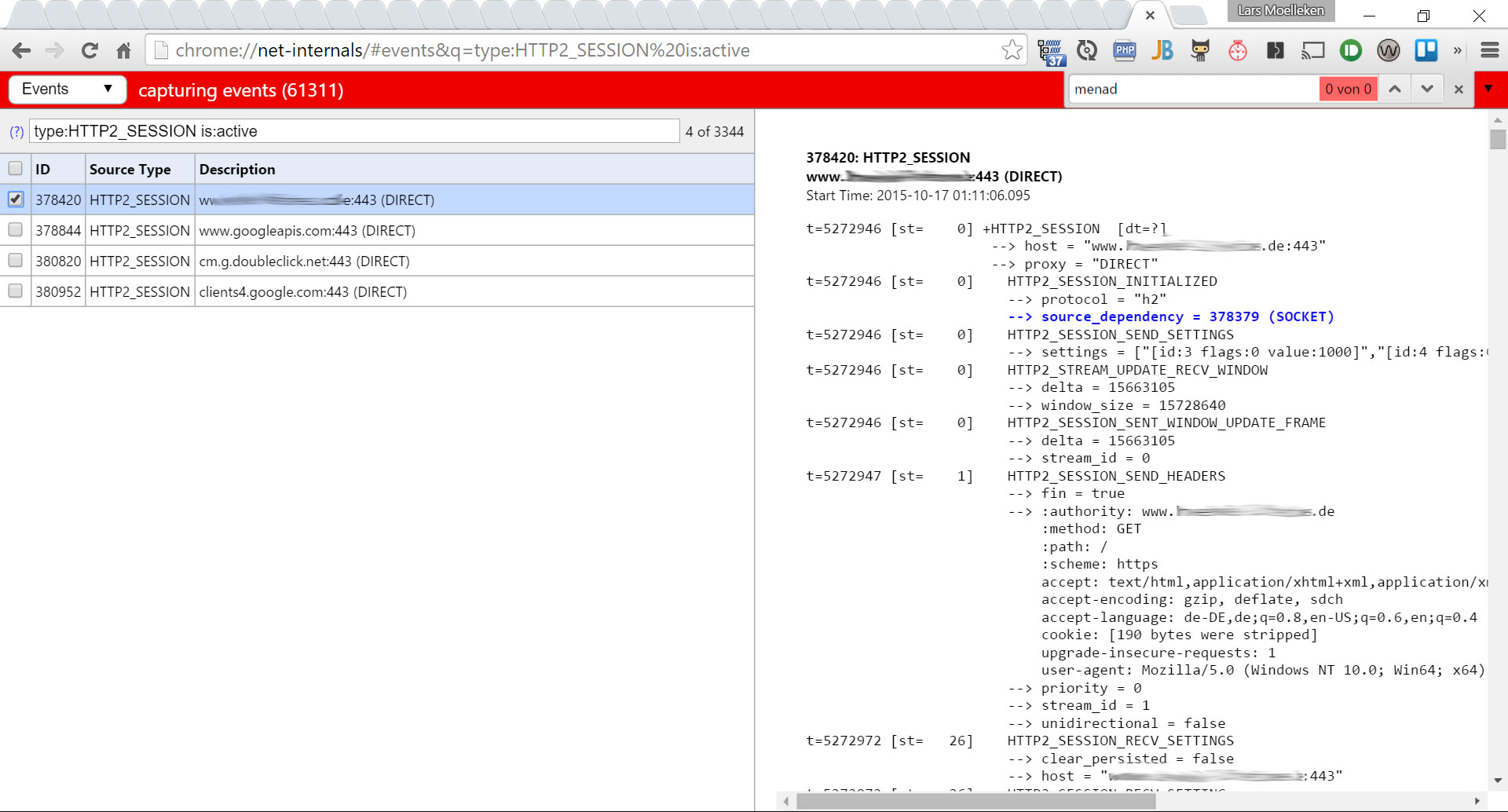
 ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.
ver im vorherigen HTTP/1.x Standard aus dem Jahr 1996 noch sehr viel Zeit mit „Warten“ verbracht, können durch den neuen Webstandard HTTP2 Webseiten schneller angezeigt werden.