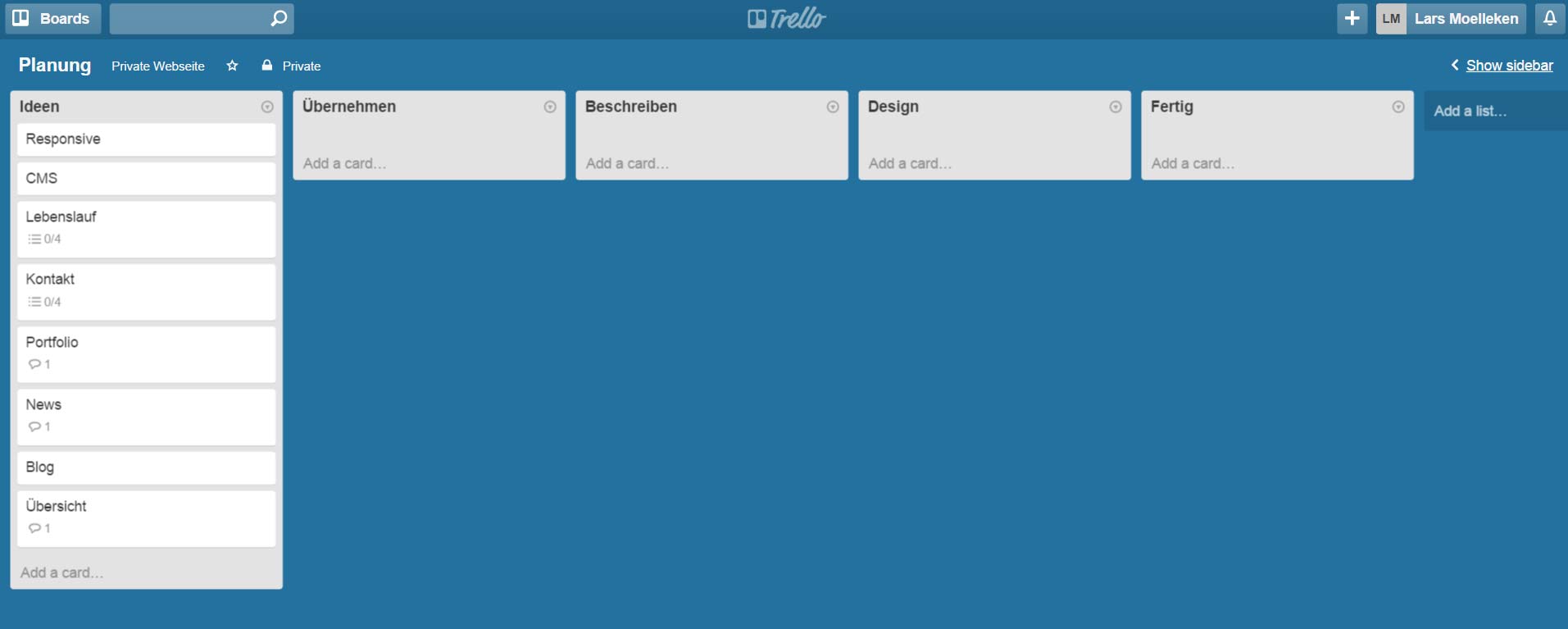
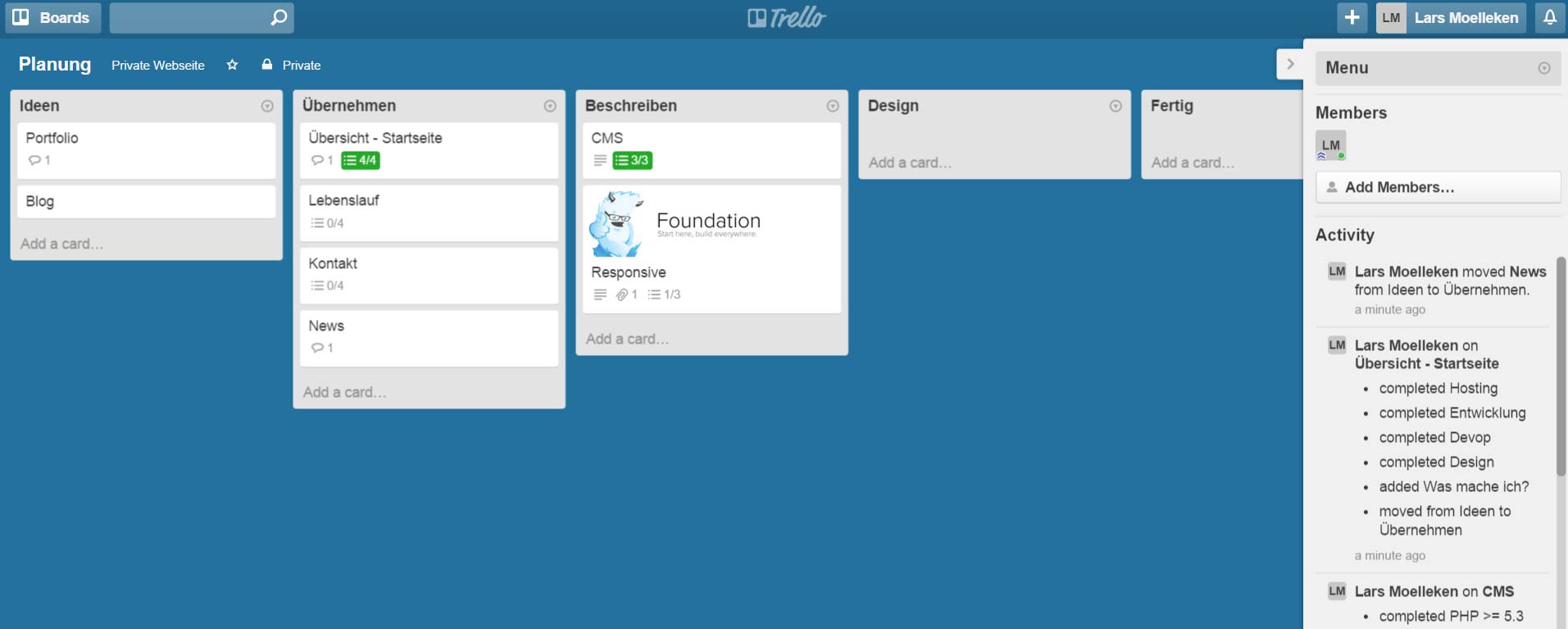
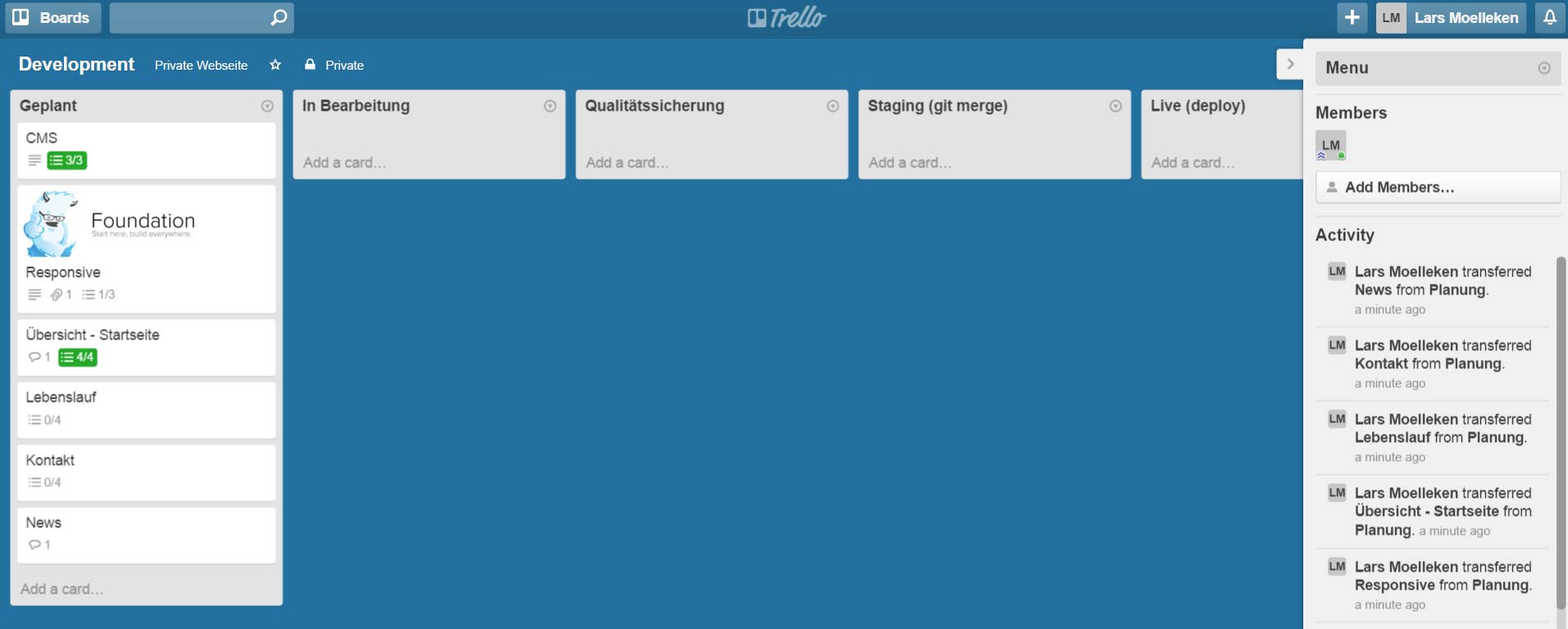
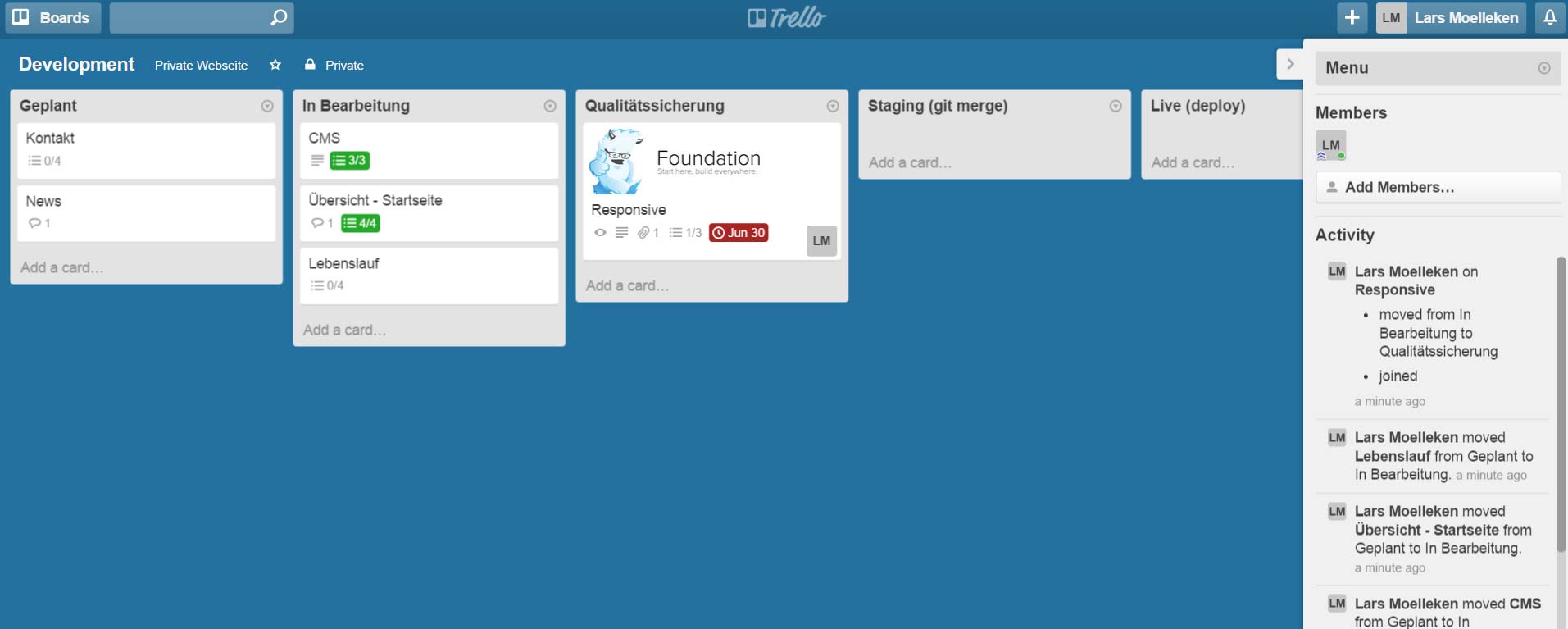
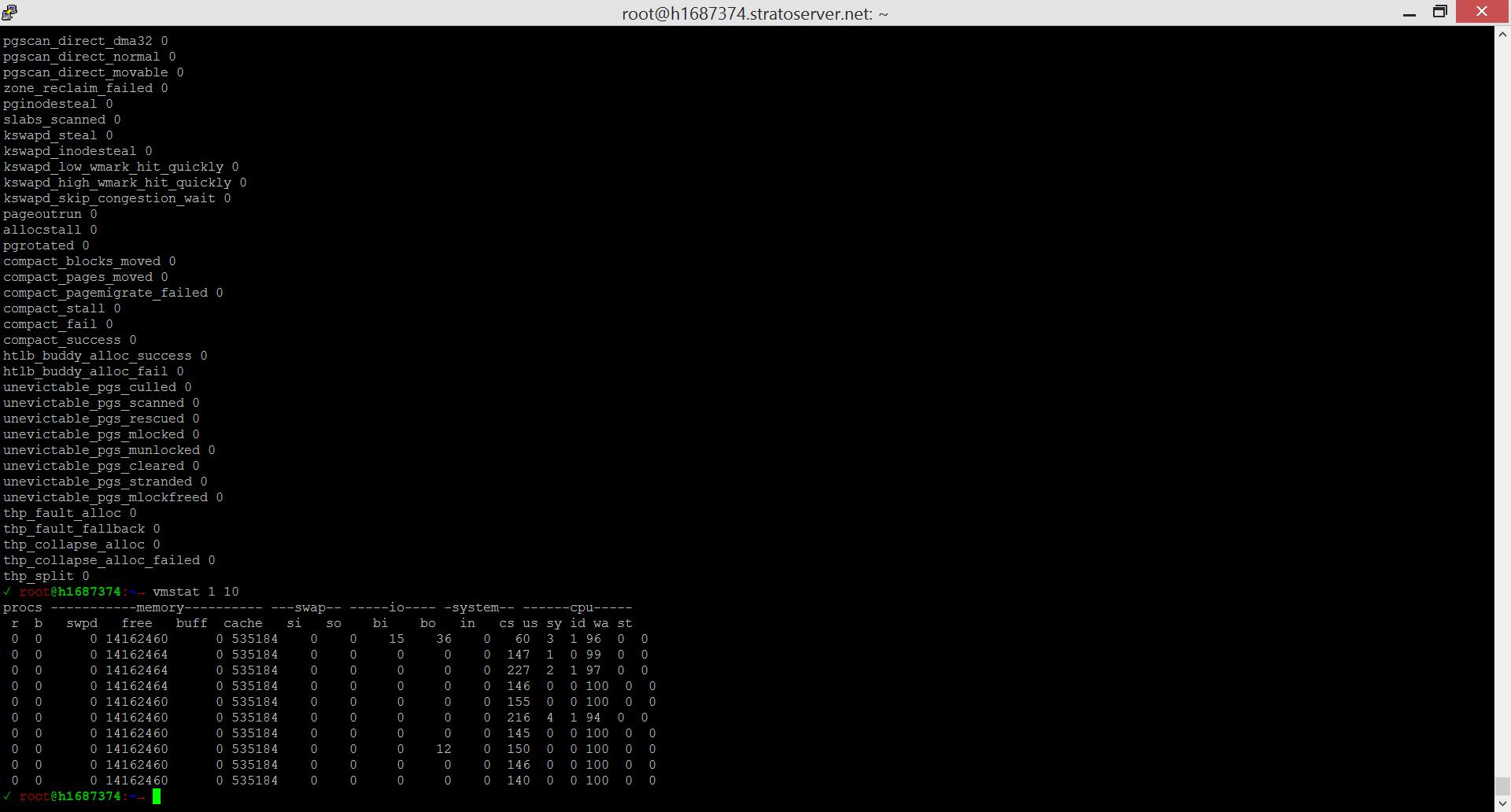
Um das Verhalten von “gzip / deflate” besser zu verstehen, möchte ich als erstes ganz kurz auf den Algorithmus hinter der Komprimierung eingehen. Dafür muss man zumindest zwei Grundlegende Theorien verstehen. Zum einen die sogenannte Huffman-Kodierung, dabei geht darum Text mit möglichst wenig Bits (0 || 1) zu übersetzen.
Es folgt ein einfaches Beispiel:
String: “im westen nichts neues”
Die Länge des Strings beträgt 22 Zeichen, was bei einem 4-Bit-Code (0000, 0001 …) eine Anzahl von 22 * 4 Bit = 88 Bit ergeben würde.
Berücksichtigt man jedoch die Häufigkeit der wiederkehrenden Zeichen, kann man für bestimmte Zeichen, welche oft im String vorkommen, kürzere Bit-Codes nutzen.
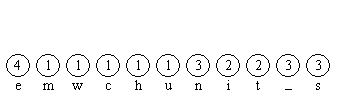
Als erstes Zählen wir die Anzahl der vorkommenden Zeichen. Die Zeichen welche die geringste Häufigkeit aufweisen werden anschließend als erstes miteinander Verknüpft und jeweils addiert.
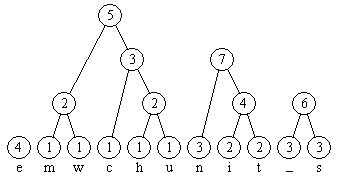
Wie man bereits erkennt bekommen die Zeichen welche nicht so häufig auftreten längere Strecken und somit gleich auch längere Bit-Codes.
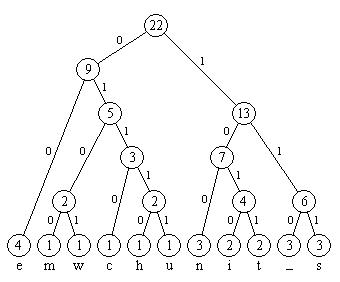
Wenn man alle Zweige verknüpft hat, entsteht daraus dann ein Binär-Baum, welcher von oben nach unten gelesen wird.
Die eindeutigen Bit-Codes sind nun z.B.: 00 für e, 100 für n, 1011 für t und so weiter. Nun benötigen wir nur noch 73 Bit anstatt 88 Bit, um den String binär darzustellen. ;)
Das zweite Prinzip hat auch mit Wiederholung von Zeichen zu tun. Die sogenannte “LZ77″ Kompression, welche wiederkehrende Muster in Strings erkennt und durch Referenzen von vorherigen Strings ersetzt.
Es Folgt ein einfaches Beispiel:
String: “Blah blah blah blah blah!”
vvvvv vvvvv vvv Blah blah blah blah blah! ^^^^^ ^^^^^
Wenn man nun die Wiederholung durch eine Referenz angibt, welche aus der Länge des Wortes (” blah” = 5) und Länge der Wiederholungen. (“lah blah blah blah” = 18). Daraus ergibt sich anschließend der folgende komprimierte Text.
Blah b(5,18)!
… aber nun endlich zum praktischen Teil! Es folgen ein paar Beispiele und Überlegungen im Zusammenhang mit Webseiten / Webservern.
1.) “gzip”, ABER weniger ist manchmal mehr
Bei kleinen Webseiten und schwachen V-Servern kann es vorkommen, dass die serverseitige Komprimierung im Gesamtkontext keinen Geschwindigkeitsvorteil bietet, da die Komprimierung ggf. mehr Overhead (Payload, CPU-Rechenzeit, Verzögerung der Auslieferung) mit sich bringt als es Vorteile (geringere Dateigröße) bietet. Zumal viele Dateien (Bilder, CSS, JS) nach dem ersten Seitenaufruf im Cache sind und nicht wieder vom Server ausgeliefert werden müssen. Gerade für mobile Geräte macht die Komprimierung jedoch fast immer Sinn, daher würde ich die Komprimierung immer aktivieren!
PS: hier noch ein Blog-Post zum Thema Webseiten Beschleunigen
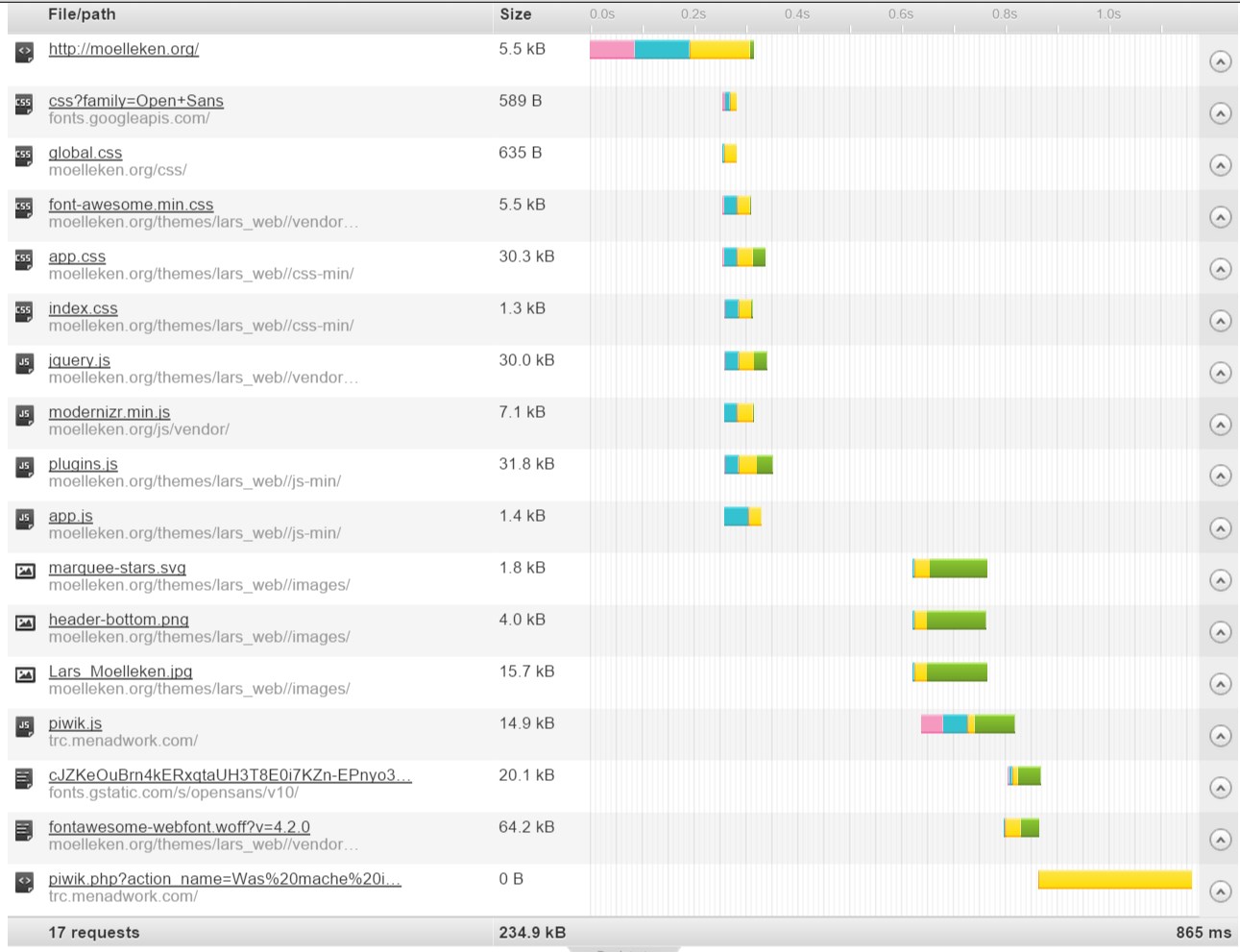
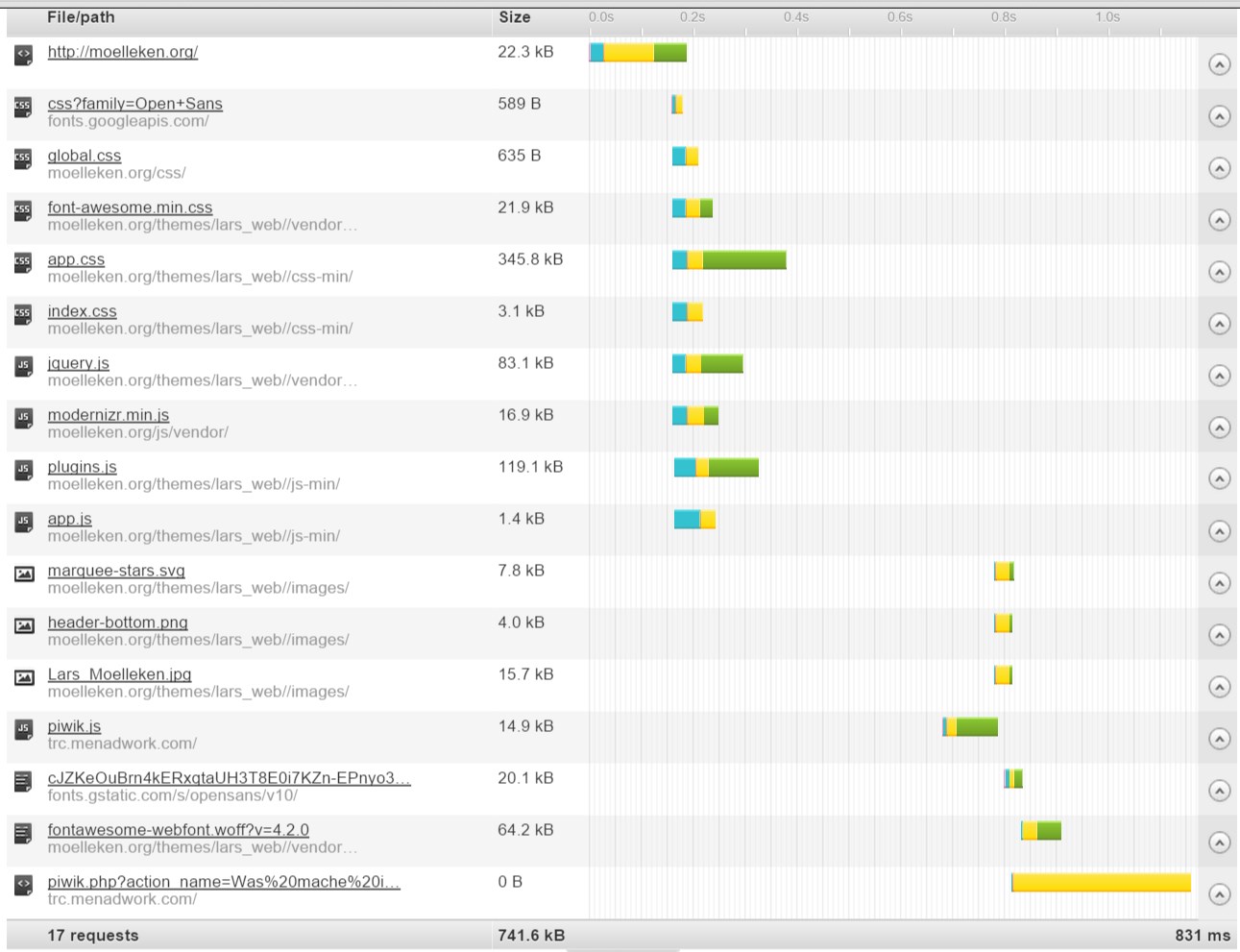
GRÜN = Download
GELB = Wartet
BLAU = Verbindung zum / vom Server
Bei “nginx” gibt es zudem ein Modul (HttpGzipStaticModule) welches direkt vorkomprimierte Dateien ausliefert, anstatt diese bei Anfrage zu komprimieren. Jedoch muss man bisher selber dafür sorgen, dass eine entsprechende Datei mit dem selben Timestamp vorhanden ist. (z.B.: main.css & main.css.gz) Falls jemand hier eine Alternative oder ein einfaches Script zum erstellen der zu komprimierenden Dateien hat, meldet euch bitte bei mir oder einfach in den Kommentaren.
2.) “gzip”, ABER nicht für alles
Zunächst sollte man bereits komprimierte Dateien (z.B. JPEG, PNG, zip etc.) nicht noch zusätzlich via „gzip“ ausliefern, da die Dateigröße im schlimmsten Fall noch steigen kann oder zumindest wird für sehr wenig Dateigröße, sehr viel CPU-Zeit auf der Server (Komprimierung) und auf dem Client (Dekomprimierung) verbraucht.
Ich empfehle an dieser Stelle mal wieder die “.htaccess“-Datei vom HTML5-Boilerplate, welche bereits viele Einstellungen für den Apache-Webserver liefert. Außerdem gibt es dort auch eine optimierte Konfiguration “nginx.conf” für den nginx-Webserver.
3.) “gzip”, ABER nicht immer
Die “gzip”-Komprimierung kann Ihre Stärken bei größeren Dateien viel besser ausspielen, da wir ja bereits im theoretischen Teil gelernt haben, dass die Komprimierung auf Wiederholungen aufbaut und wenn wenig wiederkehrende Zeichen und Muster vorhanden sind lässt es sich schlecht komprimieren.
Beim “nginx”-Webserver kann man die minimale zu bearbeitende Dateigröße angeben, sodass eine 6 Byte große Datei mit dem Inhalt “foobar” bei schwacher „gzip“ nicht auf 40 Byte vergrößert wird.
![]()
4.) “gzip”, ABER nicht so hoch
Zudem sollte man nicht mit der höchsten Komprimierungsstufe komprimieren, da man pro Komprimierungsstufe immer weniger Erfolg bei immer mehr CPU-Zeit bekommt. Man sollte weniger stark komprimieren und dadurch Rechenleistung /-zeit einsparen, um die Webseite schneller ausliefern zu können.
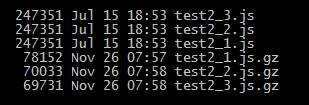
test2_1.js.gz (schwache Komprimierung)
test2_2.js.gz (normale Komprimierung)
test2_3.js.gz (starke Komprimierung)
5.) „gzip“ + Minifizierung
Durch Minifizierung von CSS und JS kann man die Dateigröße ebenfalls reduzieren, auch wenn man nicht an die Dateigröße von komprimierten Dateien herankommt, außerdem sinkt der Erfolg der Komprimierung, da wir durch die Minifizierung bereits einige Wiederholungen minimiert haben.
Es folgt ein Beispiel mit „jquery.js / jquery.min.js“:
|
Zustand |
Größe der Datei |
gewonnene Größe durch die Komprimierung |
|
nicht minifiziert + nicht komprimiert Datei |
250 kB (¼ MB) |
– |
|
nicht minifiziert + schnelle Komprimierung |
76,3 kB |
173,7 kB |
|
nicht minifiziert + normale Komprimierung |
68,3 kB |
181,7 kB |
|
nicht minifiziert + hohe Komprimierung |
68 kB |
182 kB |
|
minifiziert + nicht komprimiert Datei |
82,3 kB |
– |
|
minifiziert + schnelle Komprimierung |
30,8 kB |
51,5 kB |
6.) “gzip” + Komprimierung verbessern
Im Gegensatz zur Programmierung, wo man Wiederholungen vermeidet, sollte man im Frontend (HTML, CSS) gezielt Wiederholungen nutzen, um die Komprimierung zu optimieren. So zeigt das folgende Beispiel wie man die Dateigröße durch die korrekte Positionierung von Attributen der HTML-Tags verbessern kann.
Zwei Dateien mit dem selben Dateigröße, nur die Reihenfolge der Attribute in der zweiten HTML-Dateien (“test1_2.html”) wurden nicht in der selben Reihenfolge angegeben.
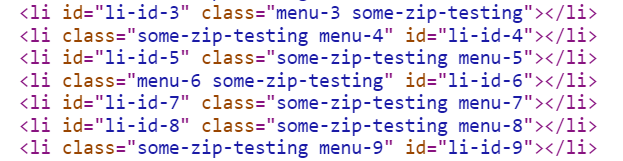
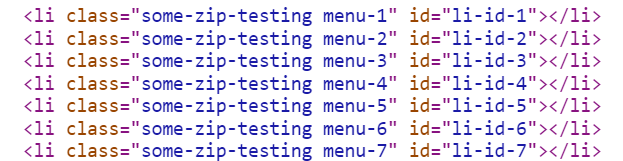
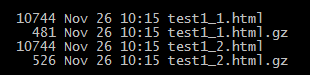
Wie man in dem Bild erkennen kann, haben wir die Dateigröße der HTML-Datei um zirka 10% reduziert indem wir den Komprimierungsalgorithmus bei der Arbeit unterstützen. ;)
Videos: