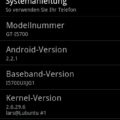
Unter GNOME-Desktop -> Eingabeaufforderung (Alt + F2) -> und folgendes eingeben ->
“free the fish” -> kleiner schwimmender Fisch auf dem Desktop (klick auf den Fisch und versuche ihn zu verscheuchen…) :D
“gegls from outer space” -> GEGLs from Outer Space
Firefox:
Folgendes bei Firefox in der Adresszeile eingeben. :-)
about:robots
about:mozilla
Debian / Ubuntu etc.:
… um das “Fake-Release” anzuzeigen, muss man in der Konsole den folgenden Befehl eingeben, klappt auch bei Ubuntu! :-)
cd ~
wget http://ymorin.is-a-geek.org/download/crosstool-ng/crosstool-ng-1.9.2.tar.bz2
tar -xjf crosstool-ng-1.9.2.tar.bz2
cd crosstool-ng-1.9.2/
./configure --prefix=${HOME}/ctng
make
make install
3.) Cross-Compiling installieren
export PATH=${PATH}:${HOME}/ctng/bin
cd ~
mkdir toolchain-build
cd toolchain-build
wget http://suckup.de/uClibc-0.9.31.config
wget http://suckup.de/toolchain-build.config
mv toolchain-build.config .config
ct-ng menuconfig
ggf. muss man vorher noch die Quellen ändern, falls der Server auf der Gegenseite mal gerade nicht antwortet, in diesem (meinen) Fall war dies “mpfr” …
cd ~/ctng
grep -Ri mpfr * | grep get
vim lib/ct-ng-1.9.2/scripts/build/companion_libs/mpfr.sh
… nun habe ich in der Funktion “do_mpfr_get” die URL zu der angegebenen Datei ersetzt, fertig! Alternativ kann man die Dateien auch per Hand herunterladen und in das Verzeichnis ~/toolchain-build/targets/tarballs/ kopieren… ;-)
———-
4.) Kernel-Quellen per git herunterladen und anpassen
cd ~
mkdir i5700.2
cd i5700.2
git clone git://github.com/ch33kybutt/i5700-initramfs-froyo-2.6.29.6
mkdir kernel
cd kernel
git clone git://github.com/ch33kybutt/i5700-kernel
cd i5700-kernel
Als erstes sei gesagt, dass diese Distribution nichts für Anfänger ist, ABER wenn man als Linux-User schon einige Erfahrungen mit der Kommandozeile gesammelt hat und z.B. Debian bereits ohne grafische Oberfläche installiert hat, kann man viel von diesem Linux-System lernen. Das “lernen” möchte ich an dieser Stelle noch einmal betonen, denn wer nichts über Linux lernen möchte und das System nur zum arbeiten nutzen möchte, der ist hier falsch. Das fängt bereits bei der Installation an, die ohne grafische Oberfläche daherkommt und das aus gutem Grund, denn wer an dieser Hürde bereits scheitert, sollte das System auch nicht nutzen. Momentan habe ich “Arch Linux” auf meinem normalen PC installiert (+ Windows7), auf meinem Netbook habe ich jedoch “Ubuntu 11.04” installiert, da es einfach out-of-the-box funktioniert und ich somit bisher noch keine großen Probleme damit hatte.
In diesem HowTo beschreibe ich wie man Archlinux installiert und ggf. wenn dies gewünscht ist optimiert. Am Ende haben wir ein schnelles Linux-System, welches wir ganz nach unseren Wünschen anpassen können, mit der neusten Software ausgestattet ist und eine grafische Oberfläche hat. “Arch Linux” hat ein wunderschönes Wiki, welches sehr umfangreich ist und auch bei Problemen mit anderen Distributinen weiterhilft, jedoch kann man am Anfang ein wenig von den ganzen Infos erschlagen werden, daher schreibe ich auch gerade dieses HowTo. :-) (Ggf. kann man die Installatin auch im Vorfeld mithilfe von VirtualBox – http://www.virtualbox.org/ ausprobieren.)
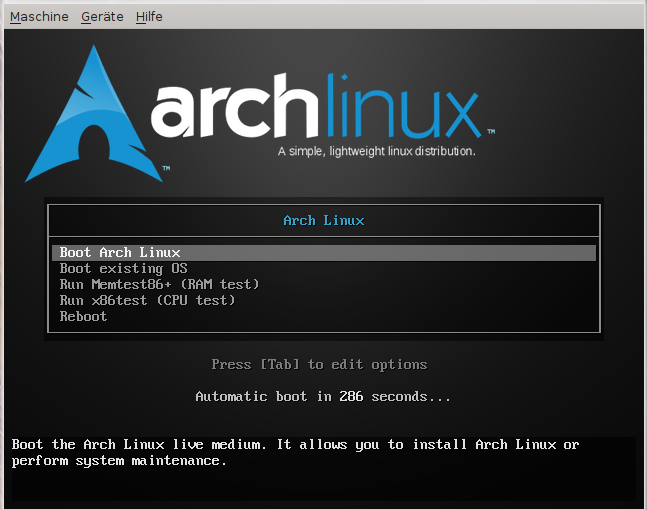
Beim start der CD wählen wir folgenden Eintrag im Boot-Menü -> “Boot Arch Linux” …
arch_linux_grub
2.) die Shell
… dann kommen wir zum nächsten Bildschirm und landen direkt in der Shell, hier führen wir folgenden Befehl aus, um das deutsche Tastaturlayout zu laden, nachdem wir uns per root eingeloggt haben. PS: die meisten Befehle funktionieren nicht nur unter Arch Linux ;-)
loadkeys de
[stextbox id=”info”]Tipp: y = z[/stextbox]
arch_linux_install_1
3.) Start der Installation
Als nächstes möchten wir die Installation starten …
/arch/setup
… und installieren das Grundsystem.
arch_linux_install_2
4.) Installationsquelle Auswählen
“Select Source”: Nun müssen wir auswähen, on wir die Daten von der CD-ROM oder Dateien aus dem Internet nutzen möchten, falls du die Net-Install-ISO heruntergeladen hast, wählst du “net” aus, ansonsten “cd”.
arch_linux_install_3
(mit “Cancel” kommt du immer einen Menü-Punkt zurück)
5.) Time
“Set clock”: Danach stellen wir das Datum und die Zeit ein.
6.) Festplatte vorbereiten
“Prepare Hard Drive(s)”: Nun müssen wir Partitione erstellen und festlegen, wo diese genutzt werden sollen (mountpoints) ggf. kann man zum erstellen der Partitionen auch im Vorfeld z.B. http://gparted.sourceforge.net/livecd.php verwenden.
arch_linux_install_4
6.1) “Auto-Prepare” : Wähle diese Option nur aus, wenn du allein “Arch Linux” auf einer Festplatte instllieren möchtest, da die automatische Partitionierung die vollständige Festplatte benutzt.
arch_linux_install_5
6.2) “Manually Partition Hard Drives”: Wähle diese Option, wenn du die Partitionen entweder bereits im Vorfeld angelegt bzw. diese nun anlegen möchtest. Es folgt meine akuelle Konfiguration
Windows_and_Linux
7.) Grundsystem auswählen
“Select Packages”: Hier wählen wir das Grundsystem (base) aus und unter dem Punnkt “base-devel” -> “wireless_tools”, falls du W-Lan nutzen möchtest.
arch_linux_install_11
8.) Grundsystem installieren
“Install Packages”: Nachdem wir diesen Punkt ausgewählt haben, wird das Grundsystem nun installiert.
9.) Grundsystem konfigurieren
“Configure System”: Kommen wir nun zur Konfiguration…
/etc/rc.conf:
Hier werden die meisten Grundeinstellungen vorgenommen, z.B. die Sprache und der Name des neuen Systems …
[...]
LOCALE="de_DE.UTF-8"
HARDWARECLOCK="localtime"
TIMEZONE="Europe/Berlin"
KEYMAP="de-latin1-nodeadkeys"
loadkeys de
[...]
HOSTNAME="ArchLinux"
[...]
Ggf. muss man noch andere Dinge im Netwerk-Bereich anpassen, z.B. falls “eth0” nicht das genutzte Netzwerk-Interface ist.
“In der Datei /etc/fstab sind alle Datenträger bzw. Partitionen eingetragen, die beim Systemstart automatisch eingehängt werden sollen [3]. Zusätzlich enthält fstab noch einige vom System/Kernel benötigte Dateisysteme. Außerdem kann man durch entsprechende Einträge in fstab das temporäre Einbinden von Datenträgern vorbereiten (siehe mount) und entfernte Dateisysteme oder Netzwerk-Freigaben statisch ins lokale Dateisystem einbinden (z.B. mit sshfs oder cifs).” – http://wiki.ubuntuusers.de/FSTAB
In dieser Datei musst du wahrscheinlich momentan nichts ändern, da “Arch Linux” die entsprechenden Einträge bereits gesetzt hat.
Falls du statische IP-Adressen in deinem Netzwerk einsetzt und keinen DHCP-Server aktiv hast, musst du hier den zu nutzenden DNS-Server eintragen, falls dies nicht der Fall ist brauchst du auch diese Datei nicht ändern.
/etc/hosts:
Hier sollte “Arch Linux” bereits den Hostnamen, welcher unter “/etc/rc.conf” angegeben wurde automatisch eingetragern haben, falls dies nicht der Fall sein sollte, muss man dies wie folgt anpassen.
arch_linux_install_13
(ArchLinux durch deinen eigenen Hostnamen ersetzen)
/etc/hosts.deny & /etc/hosts.allow:
Diese Dateien sind nur hilfreich, wenn du einen SSH-Server auf dem PC installieren möchtest, denn hiermit kannst du bestimmte IP-Adressen ausspeere bzw. erlauben.
/etc/locale.gen:
In dieser Datei musst du einen Zeichensatz, am besten den deutschen freischalten, indem du das “#” am Anfang der Zeile entfernst…
Pacman ist der Paket-Manager von “Arch Linux”, vergleichbar mit apt-get von Debian/Ubuntu und mithilfe dieser Datei kann man das Programm Konfigurieren, z.B. welche Quellen zur Verfügung stehen: [core], [extra], and [community]. Wenn du gerade ein 64-Bit System installierst, solltest du auch noch [multilib] freischalten, indem du diese einkommentierst. Ggf. kann man auch noch [testing] hinzufügen, aber wie der Name schon sagt, sind diese Quellen zum testen und nicht zum arbeiten gedacht.
[...]
SyncFirst = pacman kernel26-headers
Architecture = auto
[...]
#[testing]
#Include = /etc/pacman.d/mirrorlist
[core]
Include = /etc/pacman.d/mirrorlist
[extra]
Include = /etc/pacman.d/mirrorlist
[community]
Include = /etc/pacman.d/mirrorlist
#[community-testing]
#Include = /etc/pacman.d/mirrorlist
[multilib]
Include = /etc/pacman.d/mirrorlist
[...]
In dieser Datei gibt man an, von welchem Spiegel-Server Pacman die Daten nun wirklich laden soll. Da wir aus Deutschland die Server in Deutschland wahrscheinlich schneller erreichen als im Ausland, schalten wir einige der Server unter “Germany” frei, indem wir diese einkommentieren. Später können wir mithilfe des Scripts “rankmirrors” (https://wiki.archlinux.org/index.php/Beginners’_Guide#.2Fetc.2Fpacman.d.2Fmirrorlist) die Server herausfinden, welche wirklich für uns am schnellsten sind oder ggf. auch die Quellen hier generieren lassen: http://www.archlinux.org/mirrorlist/
Sobald du die Konfiguration abgeschlossen hast, musst du unten in diesem Menü das Root-Passwort und deine Änderungen mit “Done” bestätigen.
arch_linux_install_14
10.) der Bootlaoder (GRUB)
“Install Bootloader”: Es kommt natürlich darauf an, was du zuvor konfiguriert hast, jedoch will man meistens den aktuellen Bootloader ersetzen. Standard: /dev/sda (sda wäre hier die Festplatte auf die Arch installiert ist) ggf. Hilfe der folgede kleie Text um zu verstehen, wohin man den Bootloader installieren muss. -> http://suckup.de/blog/2011/01/25/der-bootvorgang-wie-faehrt-ein-pc-hoch/
11.) Installation beenden
“exit”: Nachdem der Bootloader erfolgreich installiert wurde, beenden wir die Installation und starten das System neu (reboot)
arch_linux_install_15
12.) Start & Update
Nun starten wir unser Arch Linux und laden in der Kommandozeile, da wir bisher noch nichts weiter installiert haben. :-) Als nächstes führen wir ein Update mithilfe des folgeden Befehls aus.
Als nächstes vergeben wir ein passwort für den neuen User…
passwd USERNAME
… und installieren nun “sudo”, so dass man als normaler User Programme mit Root-Rechten ausführen kann, wenn dies gefordert ist.
pacman -S sudo
[stextbox id=”info”]Tipp: pacman -Ss sudo -> sucht nach dem Paket sudo[/stextbox]
Nun müssen wir noch z.B. einer der angegebenen Gruppen sudo-Rechte erteilen…
chmod o+w /etc/sudoers
vi /etc/sudoers
chmod o-w /etc/sudoers
su USERNAME
sudo su
sudoers
[stextbox id=”info”]Tipp: man kann auch z.B. nano anstatt vi verwenden oder vim nachinstallieren (pacman -S vim)[/stextbox]
14.) Sound: installiere ALSA
Bevor wir wir jedoch ALSA installieren benötigen wir folgedne Info …
cat /proc/asound/modules
(Ausgabe: z.B. 0 snd_intel8x0)
… und editieren anschließend folgende Datei, um unsere Sound-Karte hinzuzufügen.
vim /etc/modprobe.d/modprobe.conf
(z.B. options snd slots=snd-intel8x0,snd-pcsp)
Nun können wir Alsa installieren …
pacman -S alsa-utils alsa-oss
… danach starten wir “alsamixer” als normaler User (nicht root) …
su USERNAME
alsamixer
arch_linux_install_18
… mit [ESC] beenden wir alsamixer und werden wieder root [Strg + D] (logout USERNAME -> zurück zu root) und speichern diese Einstellungen mit dem folgendem Befehl ab.
alsactl store
Nun müssen wir den Dienst noch in der Konfig eintragen, so dass Alsa auch gestartet wird.
Hier müssen wir als erstes Xorg per pacman installieren …
pacman -S xorg
[stextbox id=”info”]Tipp: das Paket “mesa” wird ebenfalls benötig, falls du 3D-Effekte nutzen willst[/stextbox]
… und wir müssen die Grafikkarten-Treiber installiern – ich habe dies per “Yaourt” installiert, da dieses Programm auch auf die “Arch User Repository” (https://wiki.archlinux.org/index.php/AUR) zurückgreifen kann. Wir schauen mit “lspci” nach welche Grafikkarte wir haben.
z.B.:
lspci | grep VGA
01:05.0 VGA compatible controller: ATI Technologies Inc RS880 [Radeon HD 4250]
Und installieren demensprechend den gewünschten Treiber, doch zuvor installieren wir noch “Yaourt” (http://archlinux.fr/yaourt-en#get_it) – die bereits erwähnten AUR-Pakete haben keinen Support, installation auf eigene Gefahr!
pacman -S base-devel
vim /etc/pacman.conf
[...]
[archlinuxfr]
Server = http://repo.archlinux.fr/x86_64
#Server = http://repo.archlinux.fr/i686
[...]
[stextbox id=”info”]Tipp: yaourt – es wird zudem angezeigt, wie viele Leute das jeweillige Paket nutzen und welche Pakete nicht mehr aktuell sind[/stextbox]
Und noch ein neuer Dienst wird beim Boot gestartet…
[stextbox id=”info”]Tipp: mit @ werden die Dienste im hintergrund ausgeführt[/stextbox]
vim /etc/rc.conf
DAEMONS=(syslog-ng dbus hal network netfs crond alsa gdm)
Nun einmal neustarten und …
reboot
… zu guter letzt Compiz noch im autostart von Gnome unterbringen.
cd ~/.config/autostart/
vim compiz.real.desktop
[Desktop Entry]
Comment=
Name=compiz - 3D Desktop
Exec=/usr/bin/compiz --ignore-desktop-hints --replace move resize place decorati
Name[de_DE]=compiz - 3D Desktop
Comment[de_DE]=
Hidden=false
Type=Application
X-GNOME-Autostart-enabled=true
Nun sollte dein neues Linux-System “gdm” -> “Gnome” -> “Compiz” -> “Emerald” starten… und die Installation wäre somit geschafft. ;-)
18.) Optimierungen
Hier möchte ich kurz einige Dinge zeigen, welche nicht mehr zur Installation gehören! Wer weitere Hilfe benötig, sollte sich einmal das ArchLinux-Wiki genauer anschauen: https://wiki.archlinux.de/
Mit dem nächsten Befehl, können wir schaue, welche FLAGS bisher gesetzt sind…
sudo grep -R CFLAGS /etc/
… und tragen die neuen FLAGS in der folgenden Datei ein.
vim /etc/pacbuilder.conf
z.B.:
[...]
CHOST="x86_64-pc-linux-gnu"
CFLAGS="-march=amdfam10 -O2 -pipe"
CXXFLAGS="${CFLAGS}"
LDFLAGS="-Wl,--hash-style=gnu -Wl,--as-needed"
#-- Make Flags: change this for DistCC/SMP systems
MAKEFLAGS="-j4"
Der nächste Befehl baut (compiliert) nun alle Pakete angepasst für dein System neu.
Der Begriff „Bootvorgang“ bezeichnet das Starten des Rechners, das Auswählen eines Betriebssystems und das Starten desselben. Der Begriff „Booten“ geht auf das englische Wort „bootstrap – Stiefelanzieher“ zurück.
Der Bootvorgang wird durch Reset initiiert. Reset tritt Beispielsweise auf, wenn der Strom eingeschaltet wird, die damit zusammenhängenden Vorgänge werden in Kapitel 2 beschrieben. Im Laufe des Bootvorganges gibt es später drei verschiedene Möglichkeiten, das Betriebssystem zu finden und zu laden – abhängig davon, wo sich der Code des Betriebssystems befindet:
1.) Der Code befindet sich auf einer Diskette, auf die direkt zugegriffen werden kann.
2.) Der Code befindet sich auf einer Festplatte.
Und das darauf folgende starten des Betriebssystems.
2.) Start
2.1) Reset
Beim Einschalten des Stromes wird „Reset“ ausgelöst, dabei handelt es sich um einen Hardwareinterrupt. Interrupts treten dann auf, wenn ein korrekter Programmablauf nicht mehr möglich oder wünschenswert ist. Alle Interrupts haben eine Priorität. Treten also mehrere Interrupts gleichzeitig auf, so werden sie nach Priorität geordnet ausgeführt, es sei denn, der Interrupt mit der höheren Priorität stoppt die weitere Programmausführung.
„Reset“ ist der Interrupt mit der höchsten Priorität: Er wird in jedem Fall ausgeführt. Das Reset Signal kann auch ausgelöst werden, ohne dass die Stromzufuhr unterbrochen wird. Dieser Fall wird als Warmstart bezeichnet. Den durch den Beginn der Stromzufuhr initiierten Start nennt man Kaltstart.
2.2) ROM
ROM (Read Only Memory) dabei handelt es sich um einen Speicherbaustein, aus dem nur Daten gelesen, in den aber keine Daten geschrieben werden können. Die gespeicherten Daten werden
bereits bei der Produktion der Bausteine festgelegt und können im Nachhinein nicht mehr oder nur mit speziellen Geräten verändert werden. Das ROM verliert seine Daten nicht, wenn keine Stromzufuhr angeschlossen ist. Sobald Reset gegeben wurde, wird die Hardwareinterrupt gestartet, wodurch prozessorinterne Register auf prozessorspezifische Startwerte gesetzt werden und versetzt so den gesamten Prozessor in den Startzustand. In der Regel wird anschließend der Inhalt des ROM in den RAM (Arbeitsspeicher) gespiegelt, da der Zugriff auf Speicherinhalte dort schneller gewährt werden kann. Zuletzt wird der Befehlszähler (Program Counter) auf den Beginn dieses Codes gesetzt, dadurch wird gewährleistet, dass der im ROM befindliche Code als erstes und ohne Voreinstellungen ausgeführt wird.
2.3) BIOS
Im ROM steht der Code des Basic Input Output Systems (BIOS). Dies ist ein Programm, das die Hardware überprüft und einfachste Hardwareunterstützung zur Verfügung stellt. Außerdem hat das BIOS die Aufgabe, den Start eines Betriebssystems zu ermöglichen und zu initiieren. Das BIOS führt nach seinem Start zunächst Hardwaretests durch, diese Tests werden „Power On Self Tests“ (POST) genannt. Während dieser Tests wird nach Hardware gesucht und gefundene Hardware überprüft, außerdem sucht das BIOS nach passenden Treibern. Zudem können durch diese Tests Fehler (z.B. defekte Festplatte) schneller erkannt werden.
Der POST lässt sich in einzelne Schritte einteilen. Die folgenden Schritte sind Teil jedes POST:
1. Überprüfung der Funktionsfähigkeit der CPU (bei Multiprozessor-Systemen: der ersten CPU)
2. Überprüfung der CPU-nahen Bausteine
3. Überprüfung des CMOS-RAM (Prüfsummen-Bildung)
4. Überprüfung des CPU-nahen Cache-Speichers
5. Überprüfung der ersten 64 Kilobyte des Arbeitsspeichers
6. Überprüfung des Grafik-Speichers und der Grafik-Ausgabe-Hardware
Danach kann die Grafik in Betrieb genommen werden. Die weiteren Tests werden daher meist auf dem Bildschirm sichtbar gemacht:
– Überprüfung des restlichen Arbeitsspeichers – dieser Schritt kann bei manchen BIOS durch einen Tastendruck übersprungen werden
– Überprüfung der Tastatur
– Überprüfung von weiterer Peripherie, u.a. Diskettenlaufwerke und Festplatten.
Anschließend lädt das BIOS veränderbare Daten z.B. Datum und Uhrzeit in einen Speicher. Diese Daten befinden sich auf einem kleinen Speicherbaustein, der durch eine Batterie konstant mit Strom versorgt wird. So können auch während eines Spannungsabfalls im restlichen System keine Daten verloren gehen. In diesem Speicher sind auch die benutzerdefinierten BIOS-Optionen gespeichert. Während des Startvorgangs kann der Benutzer in das Konfigurationsmenü gelangen, so dass man diese Dateien teilweise selber anpassen kann. Zuletzt sucht das BIOS nach einem bootfähigen Speichermedium. Ein Speichermedium kann zum Beispiel eine Festplatte, eine USB-Stick oder eine Diskette sein.
Jede Diskette ist in mehrere Sektoren unterteilt, von denen jeder einzelne 512 Byte umfasst. Eine Diskette wird genau dann als bootfähig bezeichnet, wenn…
1.) …von ihr ein vollständiges Betriebssystem geladen werden kann.
2.) …durch den auf ihr gespeicherten Code ein Betriebssystem von einer anderen Quelle geladen werden kann.
Den ersten Sektor einer bootfähigen Diskette nennt man Bootsektor.
Bei der Suche nach bootfähigen Speichermedien geht das BIOS nach einer Reihenfolge vor, die in BIOS festgelegt werden kann.
3.) Speichermedien
3.1) Booten von Diskette
Disketten sind nur in Sektoren aufgeteilt (im Gegensatz zu Festplatten). Der erste Sektor einer bootfähigen Diskette ist der Bootsektor, er ist 512 Byte lang und endet mit den 2 Byte der Magic Number. In den übrigen 510 Byte des Bootsektors befindet sich nun ein Programm, das den Start des Betriebssystems initiiert. Das eigentliche Betriebssystem befindet sich in den restlichen Sektoren der Diskette.
Das BIOS lädt (wenn die Magic Number stimmt) die ersten 510 Byte der Diskette in den Arbeitsspeicher und daraufhin wird dieser Code ausgeführt.
3.2) Booten von Festplatten
Die Grundstruktur aller Festplatten ist gleich: Metallscheiben mit magnetisierbarer Oberfläche rotieren mit hoher Geschwindigkeit in einem hermetisch abgeschlossen Gehäuse. Die Bits sind als Wechsel in der Magnetisierung der Scheibenoberfläche gespeichert. Schreib-/Leseköpfe (Engl. Heads) bewegen sich dicht über der Oberfläche nach innen und außen. Die Daten sind auf kreisförmigen Spuren abgelegt, die man auch als Tracks bezeichnet. Diese Anordnung unterscheidet sich grundlegend von der bei Schallplatten und CDs verwendeten: Hier gibt es pro Seite nur eine lange Aufzeichnungsspur in Form einer Spirale. Jede Spur einer Festplatte ist wiederum in einzelne Abschnitte aufgeteilt, den Sektoren (Engl. Sectors). Jeder Sektor fasst 512 Byte. Die Ansteuerung eines Sektors erfolgt über die Elektronik der Festplatte, der steuernde PC hat mit der Aufteilung in Sektoren nichts zu tun. Die meisten Festplatten benutzen die Ober- und Unterseite der Scheiben und verfügen über mehrere Magnetscheiben. Die Schreib-/Leseköpfe für alle Oberflächen sind als Einheit montiert, sie können sich nicht unabhängig bewegen. Deshalb liegen die Spuren auf den Plattenoberflächen exakt übereinander. Ein Satz von übereinander liegenden Spuren trägt den Namen Zylinder (Engl. Cylinder). Wie bereits erwähnt sind Festplatten in Abschnitte unterteilt, die mit den Koordinaten [cylinder, head, sector] angesprochen werden können. Zusätzlich kann eine Festplatte in Partitionen unterteilt werden.
Die im BIOS enthaltenen Treiber sind jedoch sehr stark minimiert, daher kann das BIOS nur auf begrenzten Festplattenplatz zugreifen. Die BIOS-Treiber können nur die Zylinder 0 bis 1023 der Festplatte ansprechen (8-GByte), auslesen und erkennen nicht mehr als zwei Partitionen, auf jeder der Partitionen kann ein Betriebssystem installiert werden. Die folgenden Ausführungen gelten nur für IDE-Festplatten, bei SCSI-Festplatten mit ihrem eigenen BIOS gibt es derlei Probleme nicht. Partitionen, von denen ein Betriebssystem geladen werden kann, heißen bootfähige oder aktive Partitionen.
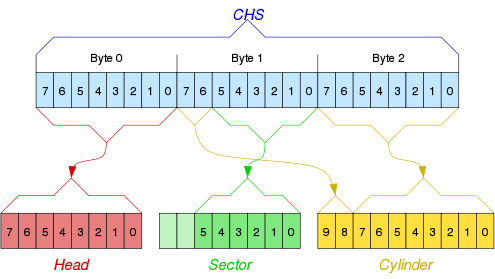
CHS-Modus:
Bis etwa 1997 wurde für die Adressierung der Festplatte das CylinderHeadSector-Verfahren genutzt. Dadurch kann jeder 512 Byte Sektor durch die Angabe des Zylinder, des Kopfes und des Sektors genau lokalisiert werden. Die Köpfe geben dabei die Magnetscheibe und deren Seite an und die Zählung wird wie bei den Zylindern mit 0 angefangen.
CHS
(Zylinder) x (Lese-Schreibköpfe) x (Sektoren) x (Sektoren Größe)
Da heutige Festplatten wesentlich größere Kapazitäten haben, verwendet man zur Adressierung die “Linear Block Address”. Diese Adresse ist vier Byte (32Bit) lang und numeriert alle Sektoren einer Festplatte der Reihe nach durch. Dadurch ergibt sich eine maximale Gesamtkapazität von:
(Sektoren) x (Sektoren Größe)
2^32 x 512 Byte
= 2048 GByte = 2 TeraByte
Für die Verwaltung der Partitionen liegt in dem äußersten Zylinder jeder Festplatte der Master Boot Record (MBR). Der Master Boot Record enthält alle Informationen, die für den Bootvorgang benötigt werden. Er ersetzt in den nun folgenden Vorgängen das BIOS. Beim Booten von einer Festplatte wird das BIOS nicht mehr benötigt, sobald der im MBR enthaltene Code
gestartet wurde.
Jede Partition funktioniert ähnlich wie eine Diskette: sie beginnt mit einem Bootsektor, in dem sich ein Programm befindet, das vom MBR gestartet wird. Die sogenannte Master-Boot-Routine wird nun durchlaufen, Standardmäßig prüft dieser Code zunächst die Einträge in der Partitionstabelle und sucht eine primäre Partition, die als aktiv (bootfähig) markiert ist. Dann lädt der Master-Boot-Code den physikalisch ersten Sektor der aktiven Partition, den Bootsektor.
Der Master Boot Record
Der MBR enthält von Fabrik aus einen Code, der das weitere Hochfahren steuert. Dieser Code wird Master Boot Code (MBC) genannt. Mit dem MBC kann von Festplatte gebootet werden, wenn nur eine aktive Partition existiert. Außerdem enthält der MBR eine Datei, in der alle Partitionen verzeichnet sind – diese wird Partitionstabelle genannt. Der MBR befindet sich übrigens im ersten Sektor der Festplatte, da ein Sektor jedoch nur 512 Bytes aufweist, müssen sich Bootcode und Partitionstabelle diesen Platz teilen: In den ersten 446 Bytes wird der Programmcode des Bootloaders ausgelagert, und in den nächsten 64 Bytes wird die Partitionstabelle untergebracht. Die letzten zwei Bytes enthalten den Code AA55h, der zur Identifizierung des MBRs selber dient.
Die Partitionstabelle enthält je Partition: (16 Byte lange Einträge)
– Boot-Flag (1 Byte) – Markiert die Partition als aktiv. Das könnte man auch mit einem Bit ausdrücken, in der Tabelle wird dennoch ein Byte freigehalten.
– Kopfnummer des Partitionsbeginns (1 Byte)
– Sektor und Zylindernummer des Boot-Sektors (2 Byte)
– Systemcode (1 Byte) – Bezeichnet den Typ der Partitionen: NTFS, unformatiert…
– Kopfnummer des Partitionsendes (1 Byte)
– Sektor und Zylindernummer des letzten Sektors der Partition (2 Byte)
– relative Sektornummer des Startsektors (4 Byte)
– Anzahl der Sektoren in der Partition (4 Byte) – Der MBC lädt die Partitionstabelle und wählt den aktiven Sektor aus. Anschließend lädt er den Inhalt des Bootsektors der ausgewählten Partition. Der dort gespeicherte Code wird gestartet und somit der Start des Betriebssystems initiiert.
Der Bootsektor
Innerhalb einer Partition gibt es einen weiteren Sektor, dessen Position immer gleich ist: der Bootsektor. Er liegt im ersten Sektor der Partition und ist damit leicht über die Einträge in der Partitionstabelle zu ermitteln.
Multiboot
Wenn die Festplatte mehrere verschiedene Betriebssysteme auf mehreren aktiven Partitionen enthält, ist der Master Boot Code (MBC) überfordert. In diesem Fall wird ein Bootmanager benötigt. Ein Bootmanager ist eine erweiterte Version des MBC. Er liest die Partitionstabelle ein und gibt über den Bildschirm eine Liste der als aktiv markierten Partitionen aus. Der Benutzer wählt eine dieser Partitionen aus. Der Bootmanager lädt den Bootsektor der ausgewählten Partition und startet den dort gespeicherten Code. Moderne Bootmanager enthalten eigene Treiber. Dadurch sind sie nicht auf die eingeschränkten BIOS Treiber angewiesen und können zum Beispiel auch Betriebssysteme starten, die sich auf der dritten oder vierten Partition befinden. Die 446 Bytes vom MBR welche für den Bootloader reserviert sind, reichen definitiv nicht aus, um eine vernünftigen Bootloader darin unterzubringen. Daher dient dieser Code in der Regel nur dazu, einen zweiten Code zu laden, der sich auf einer der Partitionen befindet. Diesen zweiten Bootloader bezeichnet man als Secondary Bootloader. Typische Bootloader für Linux-Systeme sind LILO und Grub.
Beispiel für einen Bootmanager: GRUB
GRUB (ein Akronym für GRand Unified Bootloader (engl. “Großer vereinheitlichter Bootloader”)) – GRUB ist der Linux Standard, dessen wichtigste Vorteil dieses Bootmanagers ist seine Flexibilität, verwendet, wie auch andere moderne Bootmanager, eigene Treiber, um nicht auf die Hardwareunterstützung durch das BIOS angewiesen zu sein. Dadurch sind nicht nur die BIOS Beschränkungen außer Kraft gesetzt. GRUB kann mit den eigenen Treibern die kernelspezifischen Formate des zu bootenden Betriebssystems verwenden. So können sehr viele Systeme geladen werden, auch ohne dass die physikalischen Adressen des Codes bekannt sind. Dadurch wird andererseits das Programm sehr groß und der Code passt nicht mehr im Ganzen in den MBR. Deshalb wurde GRUB in zwei Teile unterteilt ist:
GRUB Stages 1 & 2.
GRUB Stage 1 – hat dabei hauptsächlich die Aufgabe, Stage 2 zu laden und auszuführen.
GRUB Stage 2 – befindet sich auf der Festplatte. Da das Programm meist Teil einer Linux Distribution ist, befindet sich Stage 2 in der Regel auf der entsprechenden Linux Partition.
Bootvorgang_Linux
Beim Chainloading spricht GRUB die einzelnen Bootloader oder Bootsektoren der Betriebssysteme an und übergibt ihnen den Systemstart.
title=Windows Vista
rootnoverify (hd?,?)
chainloader +1
makeactive
Beispiel für einen Bootmanager: Vista
Für ältere Betriebssysteme greift der Windows Boot Manager auf die als Windows Legacy OS Loader gekennzeichneten Objekte zurück, hierbei handelt es sich im Grunde um den Verweis auf einen weiteren Bootsektor. An diesen Boot-Loader wird dann die Kontrolle des weiteren Startvorgangs übergeben. Windows 2000/XP/2003 werden so beispielsweise gestartet.
Und hier kommt dann wieder die altbekannte boot.ini ins Spiel. Denn für den Start der alten Windows-Versionen wird einfach der ntldr aktiviert, der wiederum die boot.ini ausliest.
Die bisher in der boot.ini abgelegten Informationen finden sich nun im so genannten Boot Configuration Data Store (BCD). Diese Binärdatei ist meist im Verzeichnis \boot der Startpartition. Änderungen an der Boot-Konfiguration lassen sich nur noch über das Kommandozeilen-Tool (als Administrator) bcdedit.exe durchführen.
Bevor wir nun irgendwelche Änderungen an der BCD vornehmen, sollte mittels bcdedit
/export sicherung – ein Backup angelegt werden und bei Bedarf mittels bcdedit
Will man zusätzlich Linux installieren und trotzdem dem Windows Boot-Manager verwenden (Tipp: es ist ggf. leichter dies mit GRUB zu realisieren, wie bereits zuvor gezeigt wurde) ist das auch nicht allzu schwer. Man sollte jedoch bei der Installation von Linux lediglich darauf achten, dass der Bootloader von Linux nicht in den MBR geschrieben wird sondern in die Linux-Partition.
Code:
dd if=/dev/xxx of=/bootloader.bin bs=512 count=1
Ersetze das xxx durch das Device, auf dem Linux installiert ist, also beispielsweise sda1. Die Datei bootloader.bin kopierst du z.B. auf einen USB-Stick. Das direkte Mounten und Beschreiben der NTFS-Partition von Vista ist nicht unbedingt empfehlenswert. Starte nun Windows und kopieren die bootloader.bin auf die Windows-Partition. Mit den folgenden Befehlen erzeugst du den Boot-Eintrag:
In diesem Kapitel wird das Programm beschrieben, das sich im Bootsektor eines bootfähigen Speichermediums befindet. Dieses Programm heißt Bootstrap Loader oder abgekürzt Bootloader. Es ist ein Teil des zu ladenden Betriebssystems; die folgenden Vorgänge sind also Betriebssystem-spezifisch. Die Aufgabe des Bootloaders besteht darin,die einzelnen Bestandteile des Betriebssystemkerns (Kernel) in vorherbestimmte Positionen im Arbeitsspeicher zu laden und ihren Start zu initiieren. Außerdem stellt er eine primitive Laufzeit-Umgebung bereit, so dass der Kernel, falls nötig, kompiliert werden kann. Der Bootloader ist meistens zu groß, um komplett in den ersten 510 Byte der Diskette/ Partition gespeichert werden zu können. Daher sind viele Bootloader in zwei Teile unterteilt, von denen einer im Bootblock und der andere auf dem Rest der Festplatte (oder Diskette) gespeichert ist. Hierbei übernimmt der zweite und größere Teil die Aufgabe des Bootloaders, während der erste Teil den zweiten Teil lädt. Besonders typisch ist diese Vorgehensweise für das Betriebssystem DOS. Bei DOS werden die beiden Teile des Bootloaders als Bootblock 1 und Bootblock 2 bezeichnet.
4.2) Bootstrap
Als Bootstrap (zu Deutsch Schnürsenkel) wird das Starten des Betriebssystems bezeichnet. Der Bootstrap Loader ist nach diesem Vorgang benannt worden, da er den Bootstrap initiiert. Der Bootstrap beginnt mit dem Start des Bootstrap Loaders und endet mit dem Start des ersten User Programms.
moonOS ist eine auf Ubuntu 10.10 basierende Linux Distribution, in der neusten Version 4 namens “NEAK” wurde “E17” durch “Gnome” ersetzt. (habe bisher jedoch nur eine 32-Bit Version gefunden)
Wenn man die Live-CD startet, fällt das Design und die geänderte Verzeichnisstruktur als erstes auf, aber dazu kommen wir gleich. :-)
Von Anfang an findet man sich zurecht, was daran liegen könnte, dass es noch immer ein “Ubuntu”-System ist: Auch wenn “Docky” das untere Gnome-Panel ersetzt und ein neues Gnome-Theme (Clearlooks Revamp) installiert wurde.
Was ich persönlich sehr schön finde ist, dass nicht viele Programme Vorinstalliert sind, man jedoch sofort MP3 hören, Video schauen etc. kann. Zudem sind bereits ein paar Programme installiert, welche ich bei Ubuntu ebenfalls nachinstalliert habe: Nautilus Elementary als Dateimanager, Gloobus Preview als Vorschau-Programm für Bilder, Musik und Videos.
MoonOS_Software_Center
MoonOS-Quellen:
deb http://moonos.linuxfreedom.com/moonos neak main upstream
deb-src http://moonos.linuxfreedom.com/moonos neak main upstream
Wie bereits erwähnt wurde die Verzeichnisstruktur angepasst, so dass Neueinsteiger sich besser zurecht finden sollen, zudem kann man die Dateien jedoch auch über die alte Verzeichnisstruktur erreichen. Im Grunde sind die Verzeichnisse wie bei “Mac OS X” angeordnet (z.B.: mount –bind” (ex. mount –bind /usr/bin /System/Excutables).
MoonOS_filesystemMoonOS_filesystem_2
Außerdem wartet MoonOS mit “AppShell” (Applications Framework) auf, was eine Eigenentwicklung von MoonOS ist, leider jedoch nicht richtig funktioniert: Es gibt momentan nur 3 Programme (Cheese, GIMP & Pidgin), welche dieses Framework nutzten, so dass auch nur diese unter “/AppFiles” angezeigt werden.
Fazit: Ubuntu in grün + der Versuch einige Funktionen von Mac OS X zu integrieren. :-)
In diesem kleinen HowTo möchte ich kurz zeigen, wie man Screencasts von seinem Android erstellen kann.
1.) “droid VNC server”-App installieren
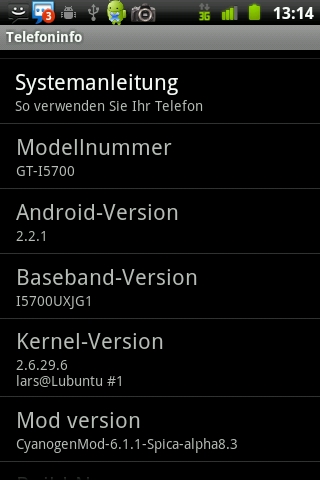
Bevor wir das besagt App über den Market installieren können, müssen wir das Smartphone rooten, dass heißt uns vollen Zugriff auf das Gerät verschaffen. (z.B. für Samsung Spica: Android 2.2 Froyo (CyanogenMod))
2.) per ADB einen Port weiterleiten
Wie die “Android Debug Bidge” im allgemeinen funktioniert habe ich bereis in einem anderem Blog-Post erwähnt -> Android Debug Bridge (adb) – HowTo
In diesem Fall rufen wir folgenden Befehl auf, um einen TCP-Port von Andoid direkt mir einem TCP-Port von unserm Betriebssystem zu verbinden.
Nun müssen wir uns nur noch einen VNC-Programm und ein Bildschirm-Recorder installieren, ich habe mich z.B. für “RealVNC Viewer” und “CamStudio” entschieden. Besonders schön finde ich, dass man sein Android auch per VNC steuern kann und so während des Aufnahme das Smartphone gar nicht in die Hand nehmen muss… :-)
XMPP(früher Jabber) ist ein Nachrichten-Protokoll (Instant Messaging), so dass heute eigentlich niemand mehr auf ICQ, MSN etc. angewiesen ist. Es gibt viele Servern (z.B. jabber.ccc.de oder jabber.org) welche Jabber nutzen, bei diesen Servern kann man sich kostenlos einen Account erstellen und damit auch Kontakten auf anderen Jabber-Servern kontaktieren. Es gibt viele Vorteile gegenüber proprietären Lösungen, z.B. kann man die Kommunikation verschlüsseln, man kann seinen eigenen Jabber-Server installieren, man kann Chat-räume (mit Passwortschutz) anlegen, sich mehrfach anmelden und fast jeder hat bereits einen Jabber-Account (auch wenn es die wenigsten wissen). Ich will an dieser Stelle gar nicht weiter auf die Vor- und Nachteile eingehen, dass haben andere bereits getan. -> blog.jbbr.net/against-icq/ & de.wikipedia.org/wiki/ICQ#Kritik
Wer sich noch gar nicht nach einer Alternative zu ICQ umgesehen hat, sollte einmal auf der folgenden Webseite schauen, wie man ein Jabber kompatibles Chat-Programm installiert. -> einfachjabber.de/oslist
Und wer direkt im Browser chatten möchte, kann sich z.B. folgende Webseite anschauen www.meebo.com oder einen Jabber-Server nutzen, welcher einen Web-Chat anbietet. z.B.: -> www.ubuntu-jabber.de
Bei den Programmen muss man zwischen Programmen unterscheiden, welche voll auf Jabber ausgelegt sind (z.B. psi) und denen, wo man zusätzliche andere Protokolle nutzen kann (Multi-Protokoll-Clients). In Kombination mit einem dafür ausgelegtem Jabber-Server, welcher sogenannte Transports (Gateways) anbiete (leider tun dies aus rechtlichen Gründen nicht alle) kann man dann auch ICQ, AIM, Yahoo Messenger, MSN uvm. direkt über Jabber erreichen. Dabei sollte man jedoch beachten, dass eventuelle Änderungen z.B. von ICQ die Verbindung zwischen “PC” -> “Transport” -> “ICQ” behindern können. -> www.swissjabber.ch/index.php/Transports & de.wikipedia.org/wiki/XMPP-Transport
Wer bereits über eine Gmail (Google-Mail), GMX oder Web.de E-Mail Adresse verfügt kann diese Adresse als Jabber Account benutzen. Jeder der bei GMX oder Web.de angemeldet ist hat daher bereits einen Jabber-Account, Benutzername und Passwort sind identisch. Zudem benötigt man (normalerweise) nur eine Adresse, um mit allen anderen Jabber-Usern zu kommunizieren, somit ist man nicht mehr auf einen zentralen Server (Dienst) angewiesen. Normalerweise habe ich in Klammern geschrieben, da z.B. “Facebook” oder auch “StudiVZ / SchülerVZ / MeinVZ” Jabber anbieten, dies jedoch nicht nach dem Standard betreiben, so dass man zwar mit seinen Kontakten z.B. seinen Facebook-Freunden chatten kann, jedoch nicht zu anderen Servern kommunizieren kann.
Jabber-Network
Wie nutze ich Jabber?
1.) Entscheidung
Wie bereits in der Einführung beschrieben, benötigen wir als erstes einen Client (Chat-Programm), daher müssen wir uns entscheiden, ob wir voll auf den Jabber-Dienst setzen und ICQ etc. über Transports erreichen oder ICQ etc. parallel im Client einrichten möchten. Positiv an den Transports ist, dass man (normalerweise) nur noch einen Account benötigt, die Verbindung zu anderen Accounts wie ICQ oder MSN erledigt dann der Jabber Server automatisch, nachdem man dies einmal eingestellt hat. Wie bereits beschrieben bieten dies jedoch nicht alle Jabber-Server bzw. Clients an. Falls du auf dieses Feature verzichtest, solltest du dir auch einmal den Client (Instant Messenger) “Pidgin” anschauen -> auf der folgenden Seite findest du eine Liste mit den unterstützten Protokollen und viele weitere Tipps zur Konfiguration, so kann man z.B. Twitter, Identi.ca oder auch Skype in Pidgin einbinden. -> wiki.ubuntuusers.de/pidgin
2.) Account anlegen
Um einen Account auf einem Server anzulegen, braucht man meistens nur den soeben erwähnten Client. Dann musst du dir einen Benutzernamen und eine Domain auf dem Server aussuchen, wobei die Domain meist vorgegeben ist. Die Kombination aus Benutzernamen und Domain wird dann deine persönliche Jabber ID (JID), mit der dich andere im Netzwerk anschreiben können. Aufgebaut ist eine JID ähnlich einer E-Mail Adresse, beispielsweise “voku@jabber.ccc.de”. Eine gute Anleitung findet man z.B. hier -> www.ubuntu-jabber.de/Konto-erstellen
3.) Account nutzen
Natürlich kann man auch andere Anbieter nutzen, welche Jabber-Dienste anbieten. Hier eine kleine Übersicht + Konfiguration.
GoogleTalk per Jabber:
Entweder man verwendet den Client von Google: GogleTalk (Windows XP oder höher erforderlich) oder einfach einen alternativen Client. (z.B.: Username@gmail.com)
Benutzer: Username
Domain: gmail.com bzw. googlemail.com
Jabber ID: Username@gmail.de
Passwort: “dein normales Google-Passwort”
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
GMX per Jabber:
Wie bereits erwähnt bietet GMX, Transports (Gateways) in folgende Netze an z.B.: ICQ, Aim, MSN, Yahoo dies muss jedoch auch die Client-Software mitmachen.
Auch hier kann man wieder den hauseigenen Messenger nutzen: GMX-Messenger (Windows XP oder höher erforderlich) “einfach” installieren und loslegen, für andere Clients: (z.B.: Username@gmx.de)
Benutzer: Username
Domain: gmx.de bzw. gmx.net
Jabber ID: Username@gmx.de
Passwort: “dein normales GMX-Passwort”
Verbindungsserver: xmpp-gmx.gmx.net
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
Web.de per Jabber:
Und auch hier kann man einen Windows-Client direkt von Web.de nutzen: WEB.DE-Messenger (Windows XP oder höher erforderlich) oder einen anderen Client nutzen. (z.B.: Username@web.de)
Benutzer: Username
Domain: web.de
Jabber ID: Username@web.de
Passwort: “dein normales Web.de-Passwort”
Verbindungsserver: xmpp-webde.gmx.net
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
studiVZ & meinVZ per Jabber:
Der sogenannte “Plauderkasten” kann nun auch per Jabber direkt vom Desktop genutzt werden. :-) Aber wie gesagt, nicht zu anderen Jabber-Servern. -> developer.studivz.net/2010/06/30/xmpp-chat-beta/ (z.B.: test@test.de)
Benutzer: test\40test.de
Domain: vz.net
Jabber ID: test\40test.de@vz.net
Passwort: “dein normales vz-Passwort”
Verbindungsserver: jabber.vz.net
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
schülerVZ per Jabber:
Der sogenannte “Plauderkasten” kann nun auch per Jabber direkt vom Desktop genutzt werden. :-) Aber wie gesagt, nicht zu anderen Jabber-Servern. -> developer.studivz.net/2010/06/30/xmpp-chat-beta/ (z.B.: test@test.de)
Benutzer: test\40test.de
Domain: schuelervz.net
Jabber ID: test\40test.de@schuelervz.net
Passwort: “dein normales vz-Passwort”
Verbindungsserver: jabber.schuelervz.net
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
Facebook per Jabber:
Der “Facebook-Chat” kann ebenfalls per Jabber direkt vom Desktop genutzt werden, aber vorher muss man sich einen Nutzernamen aussuchen http://www.facebook.com/username/ (z.B.: lars.moelleken)
Benutzer: lars.moelleken
Domain: chat.facebook.com
Jabber ID: lars.moelleken@chat.facebook.com
Passwort: “dein normales facebook-Passwort”
Port: 5222 (Standard – muss ggf. nicht angegeben werden)
4.) Fertig
Chatten und hinzufügen von Kontakten funktioniert wie man dies bei ICQ etc. gewohnt ist, mit dem kleinen Unterschied, dass man die Nutzer Jabber IDs benutzt, also nutzer@server. An dieser Stelle möchte ich noch einmal darauf hinweisen, dass Facebook & VZ-Netzwerk einen geschlossenen Jabber-Dienst anbieten, so dass man nicht zu anderen Jabber-Servern kommunizieren kann.
Ich hatte bereits einmal über das Thema “Ports via ssh weiterleiten” geschrieben, um z.B. pop3 oder smtp verschlüsselt zu nutzen. Heute zeige ich aus aktuellem Anlass, wie man mithilfe SSH einen transparenten Proxy im Netzwerk umgehen kann. Im Studentenwohnheim (Krefeld) ist jemand auf die glorreiche Idee gekommen alle Webseiten auf denen Filesharing betrieben werden kann, zu sperren.
(Tipp: mit “Alt” + “Druck” bekommt man einen Screenshot vom gewählten Fenster)
1.) Tunnel auf dem Client zum Server erstellen
Der folgende Befehl erstellt einen Socks kompatiblen Proxy per SSH-Tunnel. Wie im anderen Blog-Post beschrieben, kann man z.B. mit dem Parameter “-L” eine Verbindung zu einem anderen Proxy per SSH aufbauen.
In dem Buch “Linux-Programmierung” habe ich einige interessante Beispiele zum kopieren von Dateien unter Linux gefunden.
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main() {
char c;
int in, out;
// open - mit dem Systemaufruf open kann ein neuer Dateideskriptor erstellt werden
// ---------------------
// Modus -> Beschreibung
// ---------------------
// O_RDONLY -> nur zum lesen oeffnen
// O_WONLY -> nur zum schreiben oeffnen
// O_RDWR -> zum lesen und schreiben oeffnen
// ---------------------
// optionaler Modus -> Beschreibung
// ---------------------
// O_APPEND -> am Ende der Datei schreiben
// O_TRUNC -> Inhalt der vorhandenen Datei wird geloescht
// O_CREAT -> erstellt die Datei mit Berechtigungen
// O_EXCL -> stellt sicher, dass nicht zwei Programme
// die selbe Datei, zur gleichen Zeit erstellen
// ---------------------
// Berechtigung -> Beschreibung
// ---------------------
// S_IRUSR -> Lesen, Eigentuemer (owner)
// S_IWUSR -> Schreiben, Eigentuemer (owner)
// S_IXUSR -> Ausfuehren, Eigentuemer (owner)
// S_IRGRP -> Lesen, Gruppe (group)
// S_IWGRP -> Schreiben, Gruppe (group)
// S_IXGRP -> Ausfuehren, Gruppe (group)
// S_IROTH -> Lesen, Andere (others)
// S_IWOTH -> Schreiben, Andere (others)
// S_IXOTH -> Ausfuehren, Andere (others)
//
// weitere Infos unter: man 2 open
//
// 1 MB Datei erstellen -> dd if=/dev/zero of=file.in bs=1024 count=10240
//
// Datei "file.in" zum lesen oeffnen
in = open("file.in", O_RDONLY);
// Datei "file.out" erstellen (Eigentuemer -> Lesen + Schreiben)
out = open("file.out", O_WRONLY|O_CREAT, S_IRUSR|S_IWUSR);
// Zeichen fuer Zeichen einlesen ...
while(read(in,&c,1) == 1) {
// ... und jedes Zeichen in die neue Datei schreiben
write(out,&c,1);
}
exit(0);
}
Wir gehen in diesem Beispiel davon aus, dass die Datei “file.in” (10 MB) bereits vorhanden ist.
Test:
dd if=/dev/zero of=file.in bs=1024 count=10240
time ./copy_system
Ausgabe:
./copy_system 7,54s user 88,56s system 99% cpu 1:36,23 total
Wie wir sehen, dauerte der Kopiervorgang insgesamt ~ 1 1/2 Minuten, da wir die Datei Zeichen für Zeichen kopiert haben, im nächsten Beispiel werden jeweills 1024 Byte eingelesen und in die neue Datei geschrieben.
#include <unistd.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main() {
char block[1024];
int in, out, nread;
// open - mit dem Systemaufruf open kann ein neuer Dateideskriptor erstellt werden
// ---------------------
// Modus -> Beschreibung
// ---------------------
// O_RDONLY -> nur zum lesen oeffnen
// O_WONLY -> nur zum schreiben oeffnen
// O_RDWR -> zum lesen und schreiben oeffnen
// ---------------------
// optionaler Modus -> Beschreibung
// ---------------------
// O_APPEND -> am Ende der Datei schreiben
// O_TRUNC -> Inhalt der vorhandenen Datei wird geloescht
// O_CREAT -> erstellt die Datei mit Berechtigungen
// O_EXCL -> stellt sicher, dass nicht zwei Programme
// die selbe Datei, zur gleichen Zeit erstellen
// ---------------------
// Berechtigung -> Beschreibung
// ---------------------
// S_IRUSR -> Lesen, Eigentuemer (owner)
// S_IWUSR -> Schreiben, Eigentuemer (owner)
// S_IXUSR -> Ausfuehren, Eigentuemer (owner)
// S_IRGRP -> Lesen, Gruppe (group)
// S_IWGRP -> Schreiben, Gruppe (group)
// S_IXGRP -> Ausfuehren, Gruppe (group)
// S_IROTH -> Lesen, Andere (others)
// S_IWOTH -> Schreiben, Andere (others)
// S_IXOTH -> Ausfuehren, Andere (others)
//
// weitere Infos unter: man 2 open
//
// 1 MB Datei erstellen -> dd if=/dev/zero of=file.in bs=1024 count=10240
//
// Datei "file.in" zum lesen oeffnen
in = open("file.in", O_RDONLY);
// Datei "file.out" erstellen (Eigentuemer -> Lesen + Schreiben)
out = open("file.out", O_WRONLY|O_CREAT, S_IRUSR|S_IWUSR);
// 1024 Byte werden eingelesen ...
while((nread = read(in,block,sizeof(block))) > 0) {
// ... und in die neue Datei geschrieben
write(out,block,nread);
}
exit(0);
}
Test:
rm file.out
time ./copy_block
Ausgabe:
./copy_block 0,01s user 0,15s system 98% cpu 0,158 total
Hier dauerte der gleiche Vorgang nur noch ~ 0,16 Sekunden. Daher nutzt man zum kopieren von ganzen Festplatten auch gerne “dd”! :-) Zum Schluss noch ein Beispiel, wo die Bibliothek (stdio.h) von C genutzt wurden.
#include <stdio.h>
#include <stdlib.h>
int main() {
char c;
FILE *in, *out;
// fopen - oeffnet eine Datei
// ---------------------
// Modus -> Beschreibung
// ---------------------
// r -> nur zum lesen oeffnen
// w -> nur zum schreiben oeffnen
// a -> am Ende der Datei anhaengen
// r+ -> zum Aktualisieren oeffnen (schreiben + lesen)
// w+ -> zum Aktualisieren oeffnen, auf Null-Laenge abschneiden
// a+ -> zum Aktualisieren oeffnen, am Ende der Datei anhaengen
//
// weitere Infos unter: man fopen
//
// fgetc - liefert das naechste Byte als Zeichen aus einem Datei-Stream zurueck,
// die Funktion liefert EOF (End of File) beim Ende der Datei bzw.
// bei einem Fehler zurück
//
// weitere Infos unter: man fgetc
//
// fputc - schreibt ein Zeichen in einen Ausgabe-Datei-Stream
//
// weitere Infos unter: man fputc
//
// 1 MB Datei erstellen -> dd if=/dev/zero of=file.in bs=1024 count=10240
//
// Datei "file.in" zum lesen oeffnen
in = fopen("file.in", "r");
// Datei "file.out" erstellen (Eigentuemer -> Lesen + Schreiben)
out = fopen("file.out", "w");
// Zeichen fuer Zeichen einlesen (+ interner Puffer in der Struktur FILE) ...
while((c = fgetc(in)) != EOF) {
// ... und jedes Zeichen in die neue Datei schreiben
fputc(c,out);
}
exit(0);
}
Test:
rm file.out
time ./copy_system_2
Ausgabe:
./copy_system_2 1,10s user 0,09s system 99% cpu 1,196 total
Hier brauchen wir für 10 MB zirka 1,2 Sekunden, was um einiges schneller ist als das erste Beispiel, wo die Zeichen einzeln kopiert wurden.
In order to optimize the website and to continuously improve it, this site uses cookies. By continuing to use the website, you consent to the use of cookies.